What is Tesseract OCR?
Tesseract OCR is a powerful, open-source Optical Character Recognition solution, provided as a high-performance engine (libtesseract) and a versatile command-line program (tesseract). It solves the critical challenge of converting text embedded in images into accurate, machine-readable data, making it the foundational choice for developers and advanced users needing robust, scalable document analysis and conversion tools.
Key Features
Tesseract provides the technical depth and flexibility required for demanding OCR workflows, leveraging modern AI techniques alongside its proven legacy architecture.
🧠 Advanced Neural Network Recognition (LSTM)
Tesseract 4 and 5 introduce a powerful, new neural network (LSTM) based engine specifically engineered for line recognition. This modern approach significantly enhances accuracy, especially in complex or varied document layouts, while still offering compatibility with the legacy Tesseract 3 engine for recognizing character patterns when necessary. You can choose the optimal mode based on your input data requirements.
🌐 Comprehensive Multilingual Support
Recognize text across the globe with native support for over 100 languages out of the box using Unicode (UTF-8). If your project requires niche language support or specialized fonts, Tesseract is designed to be fully trainable, allowing you to create custom traineddata files to meet unique project specifications.
⚙️ Flexible Input and Output Management
Tesseract accepts a wide array of common image formats, including PNG, JPEG, and TIFF (with robust support for multi-page TIFFs via the Leptonica library). Crucially, it provides diverse output options necessary for modern document management, supporting standard plain text, searchable PDF (invisible-text-only), hOCR (HTML), TSV, ALTO, and PAGE formats.
💻 Developer-First API Access
For developers building custom applications, Tesseract offers direct access via the libtesseract C and C++ APIs. This allows seamless integration of high-performance OCR capabilities into larger systems, ranging from desktop applications to complex backend server processes, ensuring that text extraction is a core, reliable component of your software.
Use Cases
Tesseract’s robust capabilities make it ideal for automation and large-scale data processing across various industries.
Automated Document Digitization and Archiving: Use the command-line interface to batch-process thousands of legacy documents (e.g., scanned historical records, internal memos) stored as TIFF or JPEG files. Tesseract rapidly converts these images into searchable, invisible-text-only PDFs, instantly transforming static archives into accessible, indexed knowledge bases.
Building Custom Text Extraction Tools: Integrate libtesseract into a custom application (via C++ or language wrappers) to create specialized tools. For instance, a legal tech firm might build a tool to automatically extract and index specific fields (names, dates, case numbers) from high volumes of scanned court documents, significantly reducing manual data entry time and ensuring high data accuracy.
Real-Time Data Capture in Embedded Systems: Developers can deploy the engine within specialized hardware or mobile applications requiring local, real-time text recognition—such as license plate readers or inventory tracking systems—leveraging its efficiency and open-source nature without reliance on external cloud services.
Why Choose Tesseract OCR?
Choosing Tesseract means opting for a solution that balances decades of proven reliability with cutting-edge recognition technology.
Enhanced Accuracy via Neural Networks: Unlike older OCR systems reliant solely on character matching, Tesseract’s shift to the LSTM engine focuses on line context recognition. This results in significantly fewer contextual errors and higher overall accuracy, especially when dealing with slight image distortions, variable spacing, or complex font structures.
Unmatched Open-Source Flexibility: Licensed under the Apache License, Version 2.0, Tesseract offers complete freedom for commercial and proprietary use. This open structure, combined with comprehensive API access, ensures you can customize, integrate, and deploy the OCR solution exactly where and how your project demands, without vendor lock-in or restrictive licensing costs.
A Proven, Supported Foundation: Originally developed by Hewlett-Packard and subsequently maintained by Google, Tesseract boasts a long history of refinement and a massive community. This ensures ongoing development, robust documentation, and readily available support through dedicated user and developer mailing lists.
Conclusion
Tesseract OCR provides the technical foundation you need for high-performance, accurate text extraction projects. Its robust, dual-engine architecture, combined with extensive multilingual support and developer-centric APIs, ensures you can handle complex OCR tasks with confidence and flexibility.
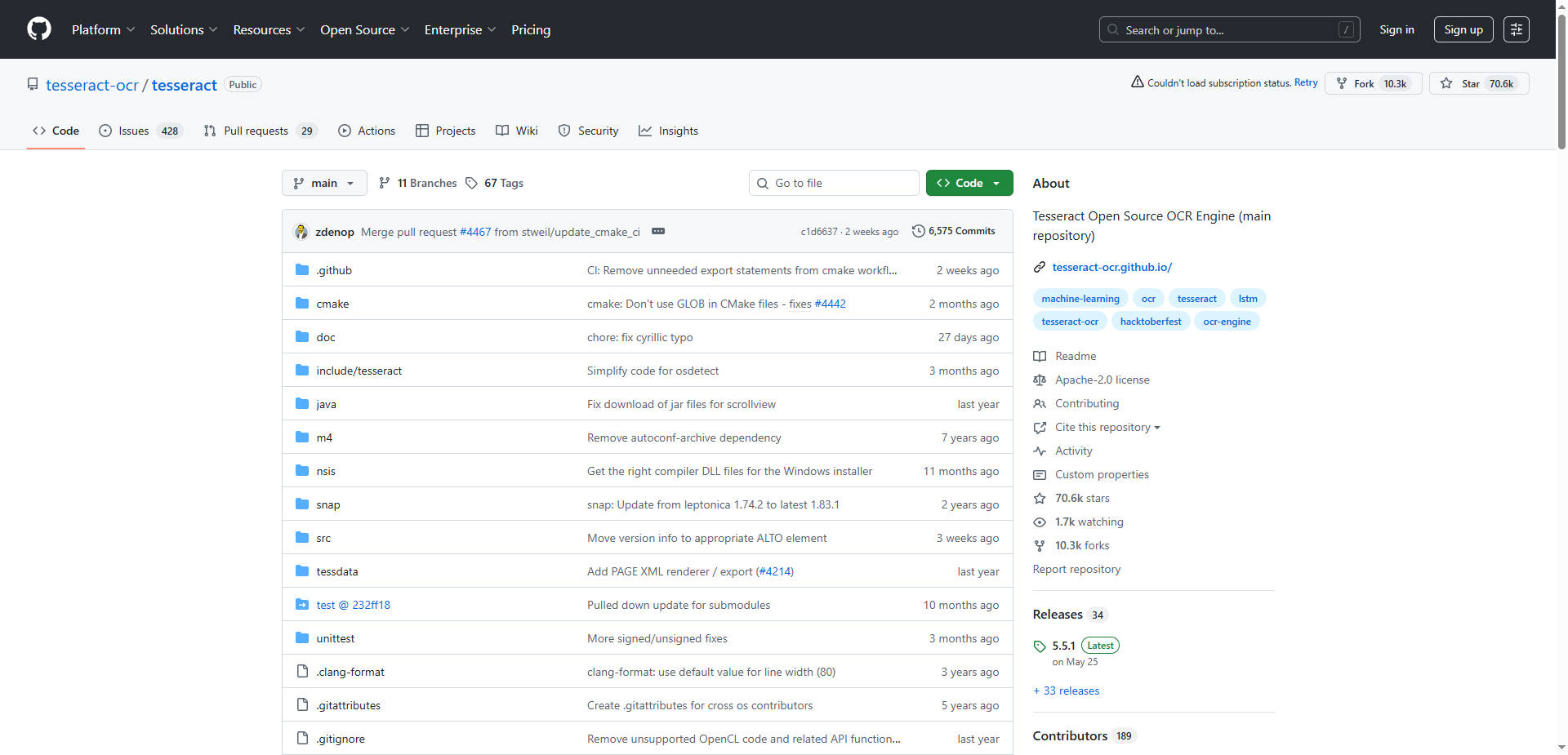
More information on Tesseract OCR
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Tesseract OCR was manually vetted by our editorial team and was first featured on 2025-10-29.
Tesseract OCR Alternatives
Load more Alternatives-

-

-
Image to text converter has completely transformed how we engage with digital content. It is also known as an optical character recognition (OCR) tool.
-
-