What is Tesseract OCR?
Tesseract OCR 是一款功能强大的开源光学字符识别解决方案,它既可以作为高性能引擎 (libtesseract) 使用,又可以作为一个多功能命令行程序 (tesseract) 运行。它攻克了将图像中嵌入的文本转化为准确、机器可读数据的关键难题,使其成为寻求强大、可扩展文档分析和转换工具的开发者和高级用户的基石之选。
主要功能
Tesseract 融合了现代人工智能技术与其久经考验的传统架构,为严苛的 OCR 工作流程提供了所需的技术深度与灵活性。
🧠 先进的神经网络识别 (LSTM)
Tesseract 4 和 5 引入了一个强大且全新的基于神经网络(LSTM)的引擎,专为**行识别**而设计。这种现代化方法显著提升了准确性,尤其在复杂或多变的文档布局中表现出色,同时仍可与传统的 Tesseract 3 引擎兼容,必要时用于字符模式识别。您可以根据输入数据需求选择最佳模式。
🌐 全面多语言支持
通过 Unicode (UTF-8),Tesseract 原生支持**超过 100 种开箱即用的语言**,助力您识别全球范围内的文本。如果您的项目需要小语种支持或专业字体,Tesseract 被设计为完全可训练的,允许您创建自定义的 traineddata 文件以满足独特的项目需求。
⚙️ 灵活的输入与输出管理
Tesseract 支持多种常见的图像格式,包括 PNG、JPEG 和 TIFF(通过 Leptonica 库对多页 TIFF 提供完善支持)。至关重要的是,它提供了现代文档管理所需的多种输出选项,支持标准纯文本、可搜索 PDF(仅含不可见文本)、hOCR (HTML)、TSV、ALTO 和 PAGE 格式。
💻 开发者优先的 API 访问
对于构建自定义应用程序的开发者,Tesseract 通过 libtesseract C 和 C++ API 提供直接访问接口。这使得高性能 OCR 功能能够无缝集成到从桌面应用程序到复杂后端服务器进程的各类大型系统中,确保文本提取成为您软件中核心且可靠的组成部分。
应用场景
Tesseract 强大的功能使其成为各行业自动化和大规模数据处理的理想选择。
自动化文档数字化与归档: 使用命令行界面批量处理数千份以 TIFF 或 JPEG 文件形式存储的历史文档(例如,扫描的历史记录、内部备忘录)。Tesseract 迅速将这些图像转换为可搜索的、仅含不可见文本的 PDF,将静态档案即刻转化为可访问、可索引的知识宝库。
构建自定义文本提取工具: 将 libtesseract 集成到自定义应用程序中(通过 C++ 或其他语言封装)以创建专用工具。例如,一家法律科技公司可以开发一个工具,自动从大量的扫描法庭文件中提取和索引特定字段(姓名、日期、案件编号),大幅缩短人工数据录入时间,同时确保数据高度准确。
嵌入式系统中的实时数据捕获: 开发者可以将该引擎部署到需要本地实时文本识别的专用硬件或移动应用程序中,例如车牌识别器或库存追踪系统,充分利用其高效性和开源特性,无需依赖外部云服务。
为何选择 Tesseract OCR?
选择 Tesseract 意味着选择一个巧妙地平衡了数十年的可靠实践与前沿识别技术的解决方案。
通过神经网络提升准确性: 不同于仅依赖字符匹配的旧式 OCR 系统,Tesseract 转向 LSTM 引擎,其核心在于**行上下文识别**。这显著减少了上下文误判,大幅提升了整体准确率,尤其在处理轻微图像畸变、可变间距或复杂字体结构时表现更佳。
无与伦比的开源灵活性: Tesseract 采用 Apache License, Version 2.0 授权,为商业和专有用途提供了充分自由。这种开放结构,结合全面的 API 访问,确保您可以根据项目需求,在任何地方以任何方式定制、集成和部署 OCR 解决方案,避免了供应商锁定和高昂的许可费用。
坚实可靠的社区支持: Tesseract 最初由 Hewlett-Packard 开发,后由 Google 维护,拥有悠久的发展历程和庞大的用户社区。这确保了持续的开发、完善的文档以及通过专门的用户和开发者邮件列表提供的便捷支持。
总结
Tesseract OCR 为您的高性能、准确文本提取项目提供了所需的技术基础。其强大的双引擎架构,结合广泛的多语言支持和以开发者为中心的 API,确保您能够自信且灵活地应对各类复杂的 OCR 任务。
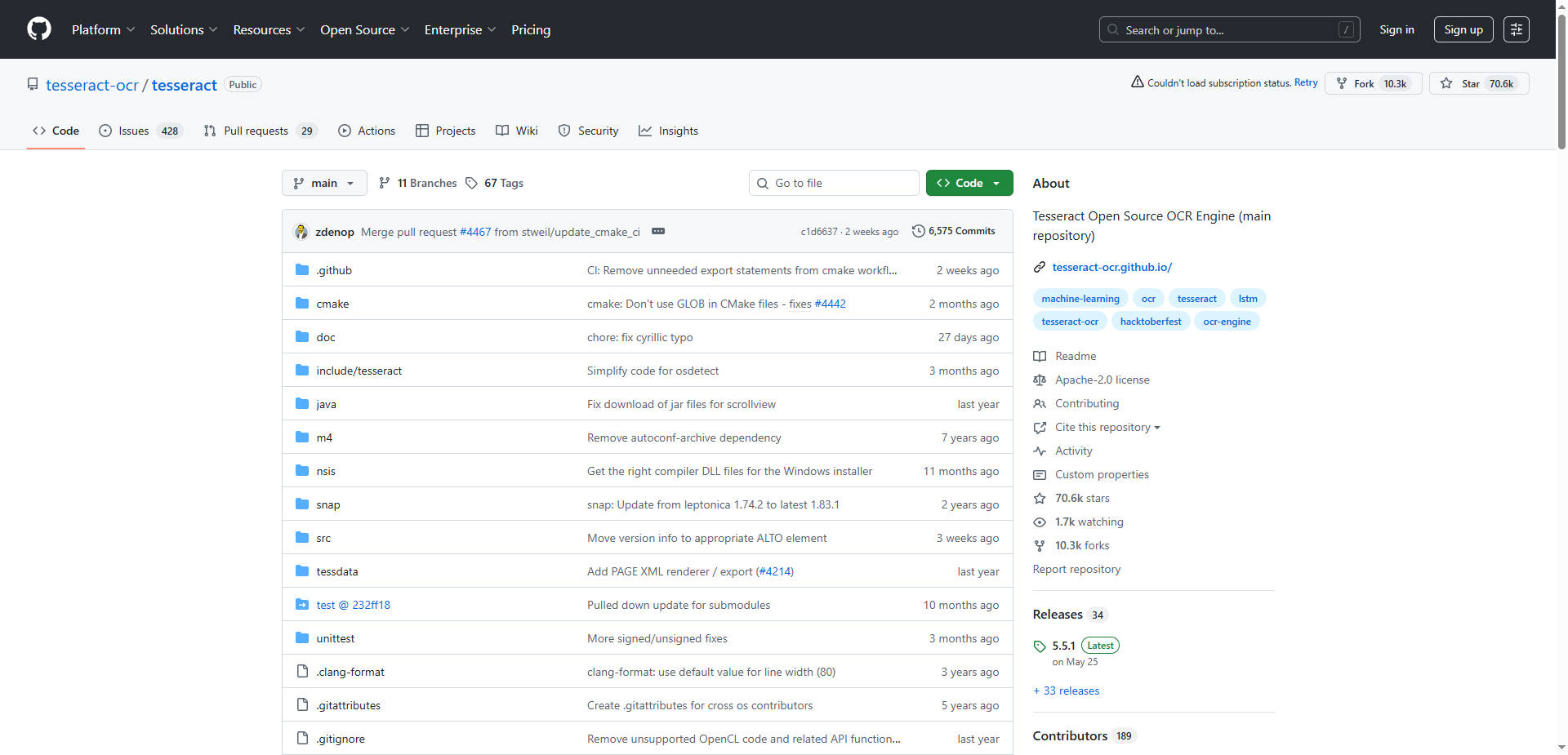
More information on Tesseract OCR
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Tesseract OCR was manually vetted by our editorial team and was first featured on 2025-10-29.