What is Tesseract OCR?
Tesseract OCR 是一個功能強大、開源的光學字元辨識 (OCR) 解決方案,它以高效能引擎 (libtesseract) 和多功能命令列程式 (tesseract) 的形式提供。它解決了將影像中嵌入的文字轉換為準確、機器可讀資料的關鍵挑戰,使其成為需要穩健、可擴展的文件分析和轉換工具的開發人員及進階使用者的首選基礎。
主要功能
Tesseract 提供處理要求嚴苛的 OCR 工作流程所需的技術深度和靈活性,它善用現代 AI 技術並結合其經過驗證的舊有架構。
🧠 先進神經網路辨識 (LSTM)
Tesseract 4 和 5 引入了一個強大、全新且基於神經網路 (LSTM) 的引擎,專為 行辨識 而設計。這種現代方法顯著提升了準確性,特別是在複雜或多變的文件版面中;同時,在必要時仍能與舊版 Tesseract 3 引擎相容,以辨識字元模式。您可以根據輸入資料需求選擇最佳模式。
🌐 全面的多語言支援
Tesseract 透過 Unicode (UTF-8) 提供原生支援,可 開箱即用超過 100 種語言,辨識全球文字。如果您的專案需要小眾語言支援或特殊字體,Tesseract 的設計具備完整的訓練能力,讓您可以建立自訂的 traineddata 檔案,以符合獨特的專案規範。
⚙️ 靈活的輸入與輸出管理
Tesseract 接受多種常見影像格式,包括 PNG、JPEG 和 TIFF (透過 Leptonica 函式庫,對多頁 TIFF 提供強大支援)。更重要的是,它提供現代文件管理所需的多元輸出選項,支援標準純文字、可搜尋 PDF (僅含隱藏文字)、hOCR (HTML)、TSV、ALTO 和 PAGE 格式。
💻 開發人員導向的 API 存取
對於建立自訂應用程式的開發人員,Tesseract 透過 libtesseract C 和 C++ API 提供直接存取。這使得高效能 OCR 功能能夠無縫整合到更大的系統中,從桌面應用程式到複雜的後端伺服器處理,確保文字擷取是您軟體的核心、可靠組成部分。
應用案例
Tesseract 穩健的功能使其成為各行各業自動化和大規模資料處理的理想選擇。
自動文件數位化與歸檔: 使用命令列介面,批次處理數千份以 TIFF 或 JPEG 檔案儲存的舊有文件 (例如,掃描的歷史記錄、內部備忘錄)。Tesseract 迅速將這些影像轉換為可搜尋、僅含隱藏文字的 PDF,立即將靜態檔案庫轉變為可存取、可索引的知識庫。
建立自訂文字擷取工具: 將 libtesseract 整合到自訂應用程式 (透過 C++ 或語言封裝) 中,以建立專用工具。例如,一家法律科技公司可能會建立一個工具,從大量掃描的法院文件中自動擷取和索引特定欄位 (姓名、日期、案件編號),大幅減少人工資料輸入時間並確保高資料準確性。
嵌入式系統中的即時資料擷取: 開發人員可以將引擎部署到需要本地、即時文字辨識的專用硬體或行動應用程式中 — 例如車牌辨識器或庫存追蹤系統 — 利用其效率和開源性質,而無需依賴外部雲端服務。
為何選擇 Tesseract OCR?
選擇 Tesseract 意味著選擇一個能夠平衡數十年經證實的可靠性與尖端辨識技術的解決方案。
透過神經網路提升準確度: 與僅依賴字元比對的舊式 OCR 系統不同,Tesseract 轉向 LSTM 引擎後,專注於 行語境辨識。這顯著減少了語境錯誤,並提升了整體準確度,尤其是在處理輕微影像失真、可變間距或複雜字體結構時。
無與倫比的開源靈活性: Tesseract 根據 Apache License, Version 2.0 授權,為商業和專有用途提供完全的自由。這種開放結構,結合全面的 API 存取,確保您可以完全按照專案需求,在任何地方、以任何方式自訂、整合和部署 OCR 解決方案,而無需供應商鎖定或限制性授權成本。
經證實、有支援的基礎: Tesseract 最初由 Hewlett-Packard 開發,隨後由 Google 維護,擁有長期的改進歷史和龐大的社群。這確保了持續的開發、完善的文件,以及透過專門的使用者和開發者郵件列表隨時可用的支援。
結論
Tesseract OCR 為您高效能、準確的文字擷取專案提供了所需的技術基礎。其穩健的雙引擎架構,結合廣泛的多語言支援和開發人員導向的 API,確保您能夠自信且靈活地處理複雜的 OCR 任務。
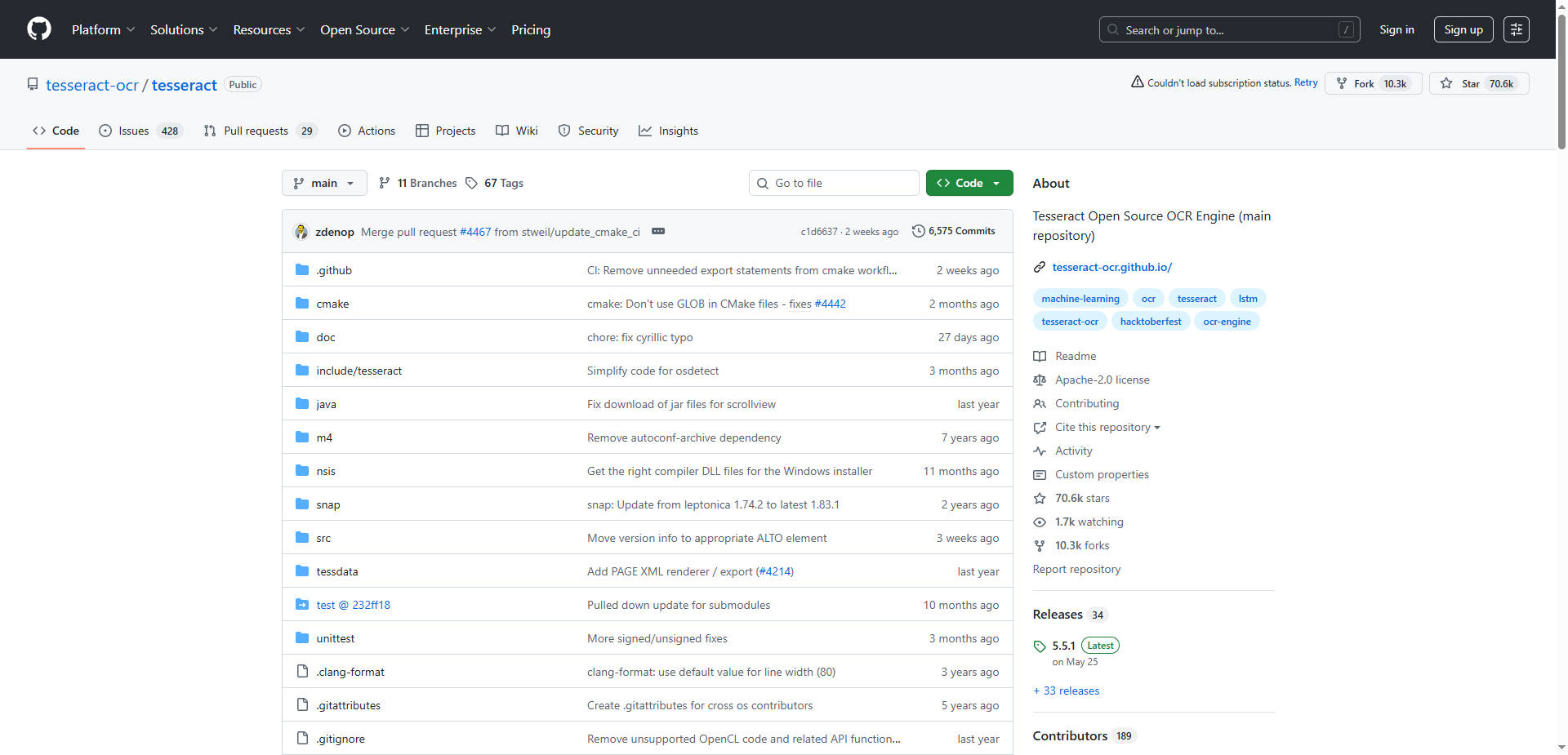
More information on Tesseract OCR
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Tesseract OCR was manually vetted by our editorial team and was first featured on 2025-10-29.