
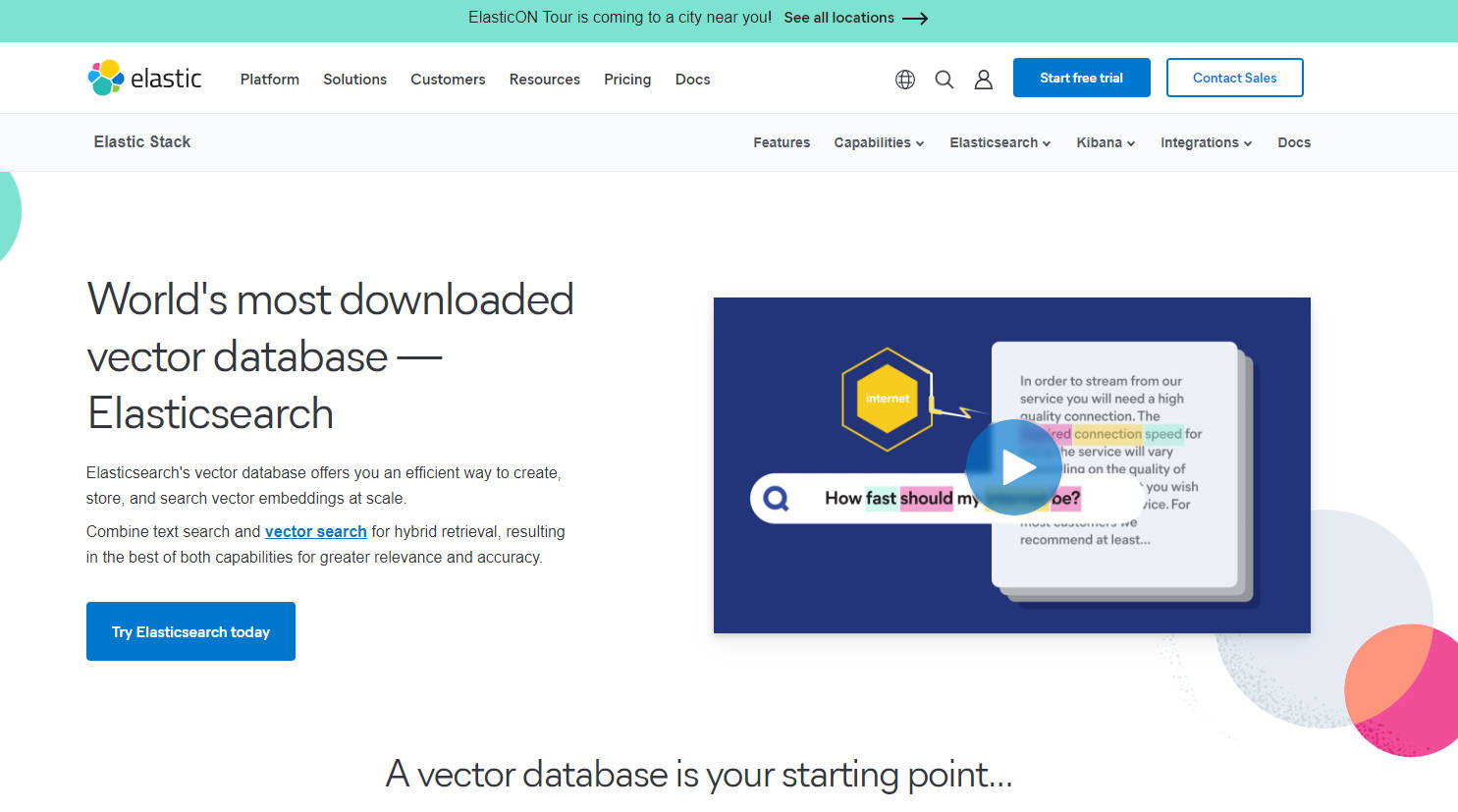
What is Elasticsearch's vector database?
Elasticsearch 的向量数据库是一个强大的工具,它使您可以有效地大规模创建、存储和搜索向量嵌入。通过结合文本搜索和向量搜索功能,它为您的检索需求提供了更高的相关性和准确性。
主要特点:
1. 向量存储:Elasticsearch 的向量存储基于 Lucene 的 HNSW 算法,该算法在向量搜索算法的基准测试中表现良好。
2. 混合检索:通过混合检索,您可以从 BM25、训练的稀疏模型 (ELSER) 和密集向量之类的检索方法的组合中进行选择,以优化搜索结果。
3. 文档安全和合规性:Elasticsearch 提供基于角色的细粒度访问控制,以及文档和字段级别的安全,以确保符合各种框架。
用例:
1. 语义搜索:将向量数据库用于语义搜索应用程序,在其中您希望关注意图和上下文含义,而不仅仅是简单的文本匹配。
2. 多模态搜索:跨文本、向量、图像、音频、视频、地理位置信息或非结构化数据等不同类型的数据执行综合搜索。
3. 人工智能驱动的搜索体验:通过机器学习技术增强您的检索能力,以获得使用向量和混合相关性的高级 GAI(生成式 AI)搜索体验。
结论:
Elasticsearch 的向量数据库使用户能够利用向量的强大功能创建高效的搜索,同时保持与基于文本的传统搜索方法的兼容性。凭借混合检索和文档级安全控制等强大的功能,此工具使开发人员能够构建复杂的应用程序,从而在不同的数据集上提供准确的结果。无论是语义搜索还是多模态数据源探索,Elasticsearch 都能满足您的需求!
More information on Elasticsearch's vector database
Launched
2010-7
Pricing Model
Freemium
Starting Price
Global Rank
29863
Follow
Month Visit
1.7M
Tech used
Google Analytics,Google Tag Manager,Optimizely,Google Fonts,Next.js,Emotion,Gzip,JSON Schema,OpenGraph,Progressive Web App,Varnish,Webpack,HSTS
Top 5 Countries
19.96%
8.53%
6.12%
4.67%
3.7%
United States
China
India
Korea, Republic of
United Kingdom
Traffic Sources
1.77%
0.82%
0.05%
7.31%
51.58%
38.46%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Elasticsearch's vector database was manually vetted by our editorial team and was first featured on 2024-01-26.
Related Searches
Elasticsearch's vector database 替代方案
更多 替代方案-
-

-

-
-

PGVecto.rs 是一个 PostgreSQL 扩展,它支持可扩展的向量搜索,使您能够在 PostgreSQL 数据库之上构建强大的基于相似性的应用程序。