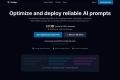
What is Galileo?
大规模构建可靠的生成式 AI 应用面临着独特的挑战。与传统软件不同,AI 的输出结果可能千变万化,这使得持续的质量控制和调试变得异常困难。随着模型和数据的不断演进,要确保你的应用表现符合预期,就需要持续的关注和精密的评估工具。而这正是 Galileo AI 的用武之地。Galileo 专为 AI 团队设计,提供了一个全面的平台,用于评估、迭代、监控和保护你的生成式 AI 应用,助你自信且快速地发布产品。
关键功能
✨ 自动化评估: 利用高精度、自适应的指标,取代耗时的人工审核。对你的 AI 功能进行严格的测试,无论是在开发过程中的离线环境,还是在生产环境中的在线状态,都可以将 AI 评估整合到你的标准 CI/CD 工作流程中。
⚡ 加速迭代: 通过同时自动化测试大量的提示词和模型,加快你的开发周期。Galileo 助你快速识别性能问题,查明根本原因,并了解失效模式,从而指导有效的修复。
🛡️ 确保实时保护: 通过低延迟的指标,实现对准确性、安全性和性能的全面生产环境监控。主动阻止不良输出,例如幻觉、PII 泄露和提示词注入,避免其触达用户。
🔬 利用强大的评估引擎: 访问一个灵活的系统,该系统由预构建的、准确的评估器驱动,并且能够轻松创建针对你的特定应用量身定制的自定义指标。通过诸如 Continuous Learning with Human Feedback (CLHF) 等技术,持续改进你的评估标准。
📊 获得端到端的可视性: 跟踪你的 AI 应用在整个生命周期中的性能,从最初的提示词设计到生产环境监控。可视化趋势,设置潜在问题的警报,并通过详细的追踪高效地进行调试。
实际应用
调试复杂问题: 当你的 RAG 应用开始生成不正确的答案时,使用 Galileo 的 token 级别分析和根本原因识别功能。基于平台处理的数百万个信号,查明问题是源于检索错误、幻觉内容还是不正确的工具使用。该系统甚至可以建议潜在的修复方案,例如添加特定的 few-shot 示例。
比较模型性能: 在部署新的 LLM 或更改你的提示策略之前,将你的测试数据集上传到 Galileo。并行运行自动化评估,比较正确性、安全性和相关性等维度上的指标,从而根据数据驱动的决策来确定哪种方法能为你的特定用例带来最佳结果。
实施生产环境的防护措施: 将 Galileo 的低延迟评估器直接部署到你的生产环境中。设置策略以自动检测并阻止有害响应、PII 或实时幻觉,即使在用户输入各不相同且模型不断演进的情况下,也能确保你的应用保持质量和安全标准。
Galileo AI 提供了 AI 团队驾驭生成式 AI 开发复杂性所需的基本工具。通过提供自动化、准确和低延迟的评估、强大的调试洞察以及实时的生产环境保护,Galileo 使你能够更快、更自信地构建、测试和部署可靠的 AI 应用。它是一个旨在为你的 AI 工作流程带来严谨性和洞察力的端到端平台。
More information on Galileo
Launched
2020-05
Pricing Model
Free
Starting Price
Global Rank
217481
Follow
Month Visit
208.1K
Tech used
Google Analytics,Google Tag Manager,Framer,Google Fonts,Gzip,HTTP/3,OpenGraph,HSTS
Top 5 Countries
20.78%
6.14%
3.55%
3.52%
3.39%
United States
India
Nigeria
Vietnam
Germany
Traffic Sources
3.82%
0.91%
0.32%
8.04%
39.65%
47.2%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Galileo was manually vetted by our editorial team and was first featured on 2025-05-24.
Related Searches