
Click outside to close
What is Lumigo?
管理现代微服务环境带来了独特的挑战。当分布式系统出现问题时,确定根本原因就像大海捞针,会耗费宝贵的开发时间。Lumigo 为像您一样的开发者提供了一个专为微服务设计的智能可观测性平台。它可以帮助您了解复杂的系统,更快地解决问题,并以更高的清晰度和更少的精力优化性能。
主要特性
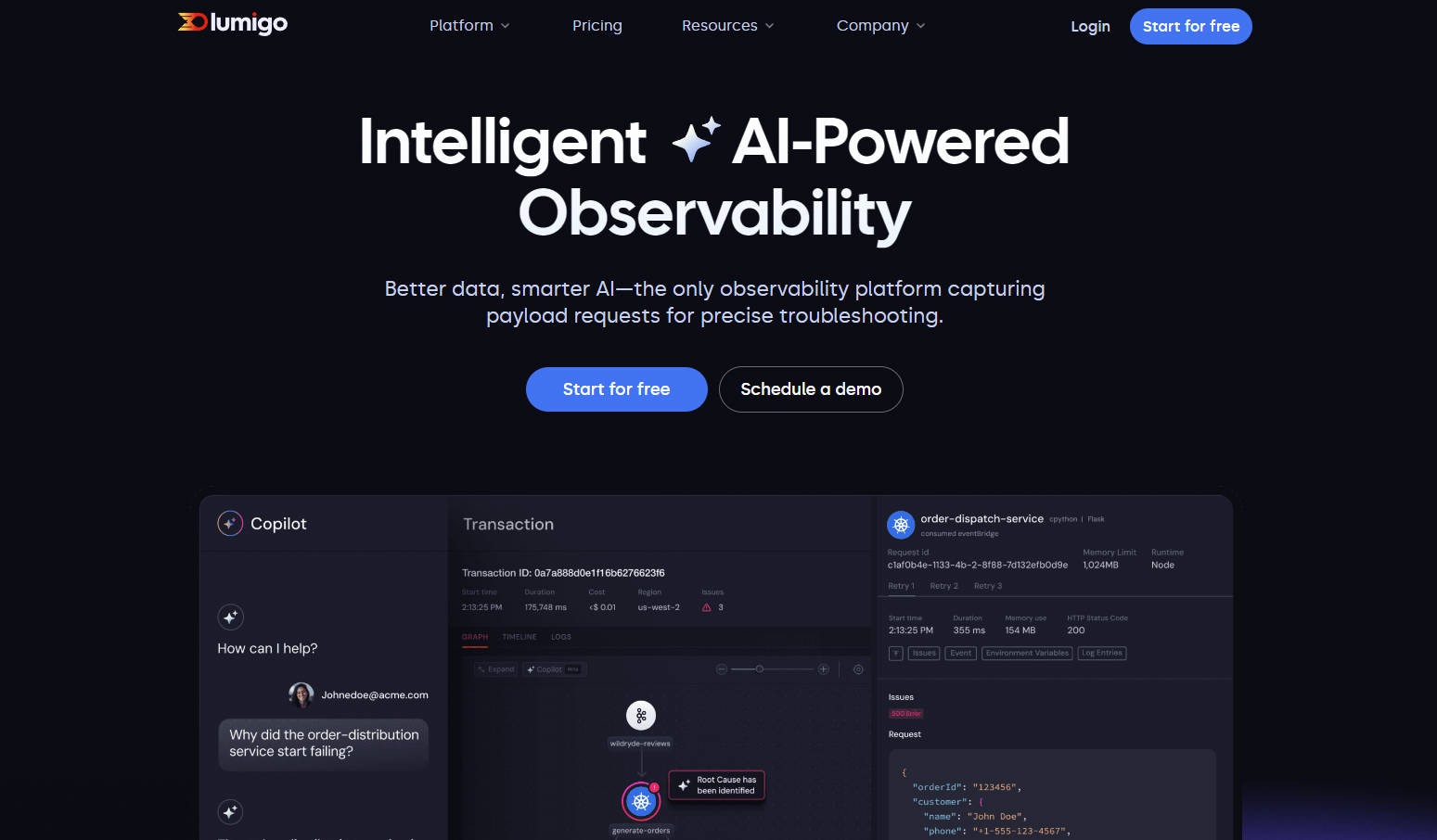
🧠 AI 驱动的可观测性: 超越标准监控。Lumigo 利用 AI,将请求和响应负载与追踪、日志和指标进行独特关联。这使得平台能够自动识别问题并在几秒钟内提出根本原因建议,从而显著减少您在手动调试上花费的时间。
⏱️ 即时追踪部署: 在几分钟内在 AWS、Kubernetes 和 OpenTelemetry 环境中实现全面的端到端分布式追踪。Lumigo 自动执行追踪器注入——通常无需更改代码——让您立即了解请求流、服务依赖关系和性能瓶颈。部署选项包括一键式 AWS 集成和用于 Kubernetes 的简单 Helm 命令。
💰 经济高效的日志管理: 控制您的日志记录费用,有可能降低高达 70% 的成本。Lumigo 的自定义数据摄取管道允许您集中且高效地管理日志。它使用追踪和负载上下文丰富日志,确保您保留关键的故障排除信息,而无需为所有内容编制索引的高昂成本。
📊 全面的指标和可视化: 实时了解您的应用程序的运行状况。监控基础设施和应用程序的关键绩效指标 (KPI),创建针对您需求量身定制的自定义指标,并设置智能的、AI 驱动的警报。通过直观的仪表板和事务视图可视化系统性能和依赖关系。
用例:Lumigo 如何帮助开发者
快速调试生产故障: 一个间歇性错误开始影响跨三个不同微服务的用户。您没有手动筛选每个服务的日志,而是求助于 Lumigo。它的 AI 立即关联跨服务的失败请求,使用在追踪中捕获的负载数据突出显示确切的错误,并指向特定的代码行或配置问题,从而将解决时间从数小时减少到数分钟。
识别性能瓶颈: 用户报告高峰时段响应时间缓慢。使用 Lumigo 的端到端追踪,您可以可视化整个请求旅程。事务视图清楚地显示了单个服务中特定数据库查询中的过度延迟。您可以直接访问相关的请求和响应负载以了解查询参数并确定所需的优化,所有这些都无需切换工具。
优化云日志记录支出: 随着应用程序的扩展,您的日志记录成本不断攀升。您实施 Lumigo 以更智能地管理日志摄取。您配置规则以对不太重要的日志进行采样,同时确保捕获与错误相关的日志,并利用上下文相关的日志(用追踪和负载数据丰富)来保留必要的故障排除信息。这显著减少了存储和索引的日志量,在不损失关键可见性的情况下实现了可观的成本节省。
结论
Lumigo 使您(开发者)能够自信而快速地应对微服务环境的复杂性。通过结合智能的 AI 驱动的分析、追踪中完整负载可见性的独特优势、快速部署、原生 OpenTelemetry 支持和经济高效的日志管理,Lumigo 显著加速了故障排除并加深了对应用程序的理解。减少诊断问题的时间,将更多时间用于构建出色的软件。
More information on Lumigo
Top 5 Countries
7%
6.71%
5.44%
4.72%
4.17%
Belgium (7%)
United States (6.71%)
Russia (5.44%)
India (4.72%)
Canada (4.17%)
Traffic Sources
3.77%
8.26%
52.11%
34.55%
social (3.77%)
paidReferrals (1.13%)
mail (0.12%)
referrals (8.26%)
search (52.11%)
direct (34.55%)
Source: Similarweb (Sep 25, 2025)
Lumigo was manually vetted by our editorial team and was first featured on 2025-04-01.
Lumigo 替代
Lumigo 替代-
Lumi 是一款基于聊天的 AI 数据分析师,能够快速、低成本地从 ERP 系统和数据库中挖掘出全新洞察,其速度远超人工分析,成本仅为后者的一小部分。
-

Lumino:全球AI训练云平台。简易SDK,自动伸缩,成本降低高达80%。数据安全可靠。非常适合初创企业、大型企业和自由职业者。革新您的AI项目!
-

-

-
Lumro: 部署全天候AI智能代理,赋能销售与客户支持。自动处理各项任务,精准捕捉潜在客户,高效完成支付流程,从而让您的团队从繁琐事务中解放出来,聚焦核心战略增长。