Click outside to close
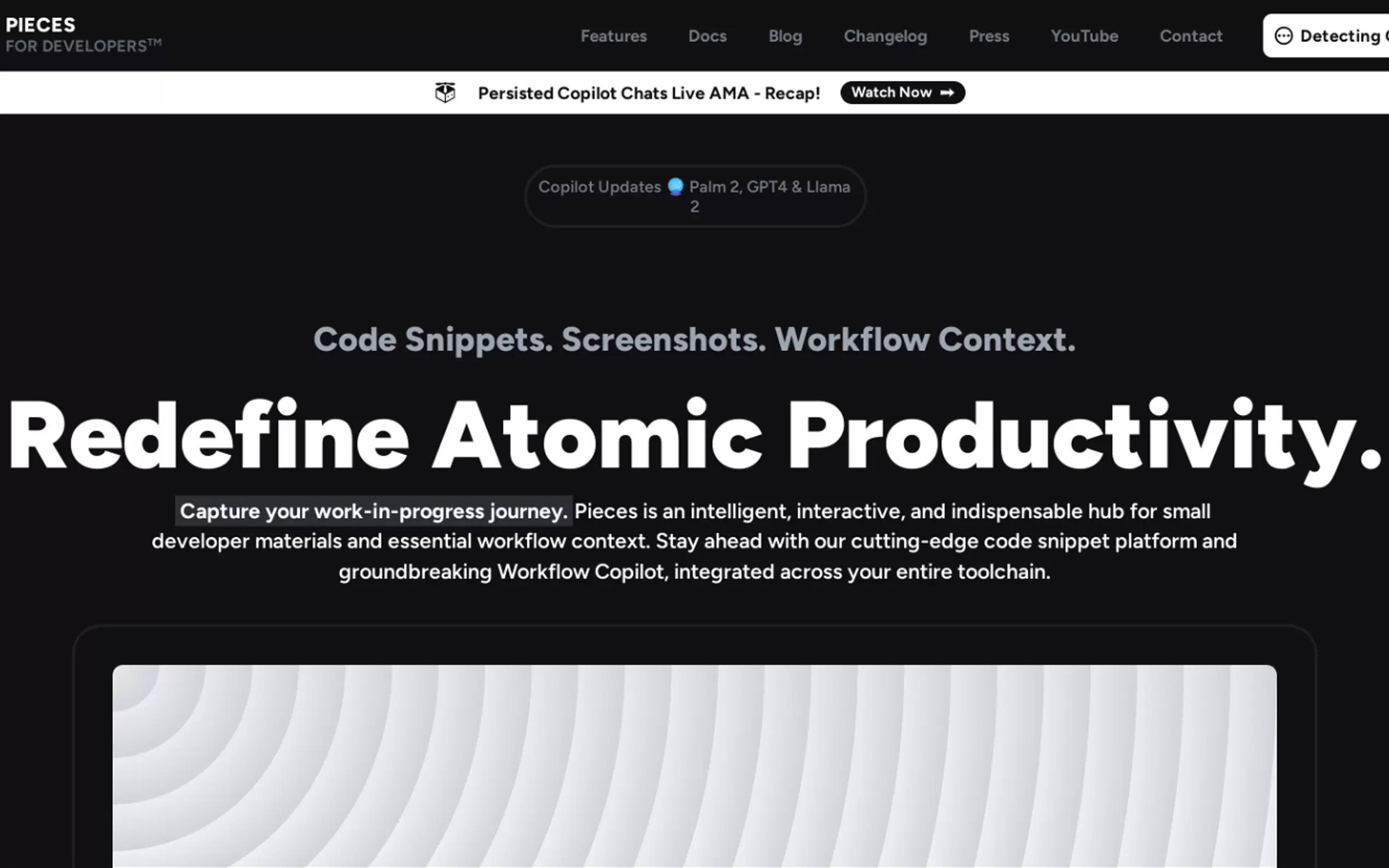
What is Pieces?
Pieces 是一款操作系统级的 AI 伴侣,能为你的整个工作流——从代码片段、文档到聊天记录和研究资料——构建持久、长期的记忆。它消除了上下文切换与手动整理的摩擦,确保开发者和技术团队能够即时回溯自己做过什么、在哪个应用中操作、以及具体时间。Pieces 让你构建得更快、更智能,始终为你的 AI 工具提供所需的关键上下文。
核心功能
🧠 LTM-2:长期记忆引擎
专有的长期记忆引擎(LTM-2)可在你的工作流中自动创建安全、基于时间的代码、文档和通信记忆,无需任何手动输入。每一条保存的内容或代码片段都与其原始上下文保持关联,让你即使在九个月后,也能通过基于时间的查询精准找到所需信息。
🛠️ 无缝跨工具上下文捕获(插件)
Pieces 旨在融入你当前的工作环境,最大限度减少上下文切换。通过专为 VS Code、Chrome 以及各类操作系统(Windows、Linux、macOS)打造的插件,Pieces 能在你进行研究、调试或协作时自动捕获并保留工作流,确保在整个数字环境中形成统一的记忆体系。
🔒 默认本地运行,隐私优先设计
安全性和用户控制权至关重要。Pieces 默认在设备端运行,尽可能在本地离线处理数据,既快速又安全,并与云端完全隔离。平台赋予你对记忆内容的端到端控制权,可随时启用、禁用或删除数据,实现最高级别的隐私与安全保障。
🤝 上下文感知的 LLM 集成(MCP)
Pieces 确保你的 AI 工具掌握你所知道的信息。通过 Model Context Protocol(MCP)服务器,Pieces 将你的私有长期记忆直接连接至主流大语言模型(LLM),包括 GitHub Copilot、Claude 和 Gemini。这为你的常用语言模型提供实时、个性化的上下文,超越仅依赖公开数据的通用回答。
💡 自动化代码增强与转换
轻松从 IDE、图片、文件或网页中捕获代码片段。Pieces 会自动对其进行增强处理:追踪协作者信息、识别敏感内容,并优化可读性或性能;必要时,还能将代码转换为其他编程语言。
应用场景
简化深度工作与调试流程 当你遇到复杂 Bug,或需要引用数月前实现的特定解决方案时,无需再依赖零散的聊天记录或深埋的提交信息。Pieces 会完整捕获上下文——包括相关代码、你阅读过的文档,以及讨论解决方案的聊天内容——让你通过自然语言搜索,瞬间定位所需记忆,精准接续此前的工作状态。
无感式研究与文档整理 在技术调研过程中,Pieces 会静默记录你遇到的每个重要链接、高亮内容和关键词,彻底告别频繁书签收藏或手动记笔记。这意味着你可以全神贯注于信息吸收,同时后台自动构建一份完整索引、可随时检索的研究记忆库。
赋能个性化 AI 交互 使用 Pieces Copilot 向其咨询你专属私有项目的问题。Copilot 不再给出泛泛而谈的答案,而是依托你的 LTM-2 记忆——包括历史代码、文档及具体项目细节——提供高度精准、上下文感知的协助,完美契合你独特的工作流与知识体系。
为何选择 Pieces?
Pieces 不仅仅是一个存储库,更是一位专注的工作流助手,从根本上重塑你与上下文及 AI 的交互方式。
- 超越自动补全: 与仅聚焦于 IDE 内代码补全的工具不同,Pieces 是一个贯穿你整个工作流的 AI 连接器。它在你使用的所有工具间提供持久记忆与上下文感知能力,无论当前使用何种应用,都能最大化效率。
- 真正的数据主权: Pieces 在设备本地处理数据。这种强大的隐私保障机制——除非用户明确授权,否则绝不上传至云端——对个人开发者和高安全要求的企业部署至关重要,确保敏感上下文始终安全留存于你的环境中。
- 更深层的 LLM 推理能力: 通过 MCP 提供个人上下文,Pieces 使 Claude 4 Sonnet、Opus 等先进大模型能基于你真实的历史项目进行高阶推理,从而提供比仅依赖公开数据训练的模型更相关、更具可操作性的 AI 辅助。
结语
通过将操作系统级的记忆捕获与注重隐私的 AI 相结合,Pieces 为现代高速开发提供了不可或缺的持久上下文引擎。别再让关键细节在上下文切换中流失,现在就开始借助过往工作的全部力量高效构建吧。
More information on Pieces
Top 5 Countries
14.04%
12.24%
3.22%
2.81%
2.26%
India
United States
Germany
France
Vietnam
Traffic Sources
0.09%
37.22%
50.05%
3.46%
7.66%
1.48%
mail
direct
search
social
referrals
paidReferrals
Source: Similarweb (Jan 3, 2026)
Pieces was manually vetted by our editorial team and was first featured on 2023-10-24.
Related Searches
Pieces 替代方案
更多 替代方案-
-

为你的AI赋予可靠的记忆能力。MemoryPlugin 确保你的AI能够跨越17+个平台,精准回忆起关键上下文,告别重复,为您节省宝贵的时间并降低token消耗。
-
Activepieces: 编排AI智能体,自动化贯穿您整个技术栈的复杂工作流。开源、AI优先,既能满足无代码用户的需求,也支持开发者深度定制。
-
Claude-Mem 能够无缝地在会话之间保留上下文,通过自动捕获工具使用过程中的观察结果、生成语义摘要,并将这些信息提供给后续会话。这使得 Claude 即便在会话结束或重新连接后,依然能保持对项目知识的连贯性。
-