
What is Tensorlake?
在构建人工智能应用,尤其是由大型语言模型 (LLMs) 驱动的应用时,处理非结构化数据是一个常见的挑战。文档、图像和演示文稿蕴含着宝贵的信息,但要将其转化为人工智能可用的结构化格式,需要付出巨大的努力。您需要可靠的方法来解析复杂的文件,提取特定的数据点,并构建强大的管道来大规模处理一切。
Tensorlake 提供了一个专门的人工智能数据云平台,旨在可靠地将来自各种来源的非结构化数据转换为可供您的人工智能应用程序使用的、可直接导入的格式。它可以帮助开发者简化将混乱的真实世界文件转化为 LLM 可以有效使用的结构化数据的过程,从而为自动化、分析和知识检索开启新的可能性。
主要功能
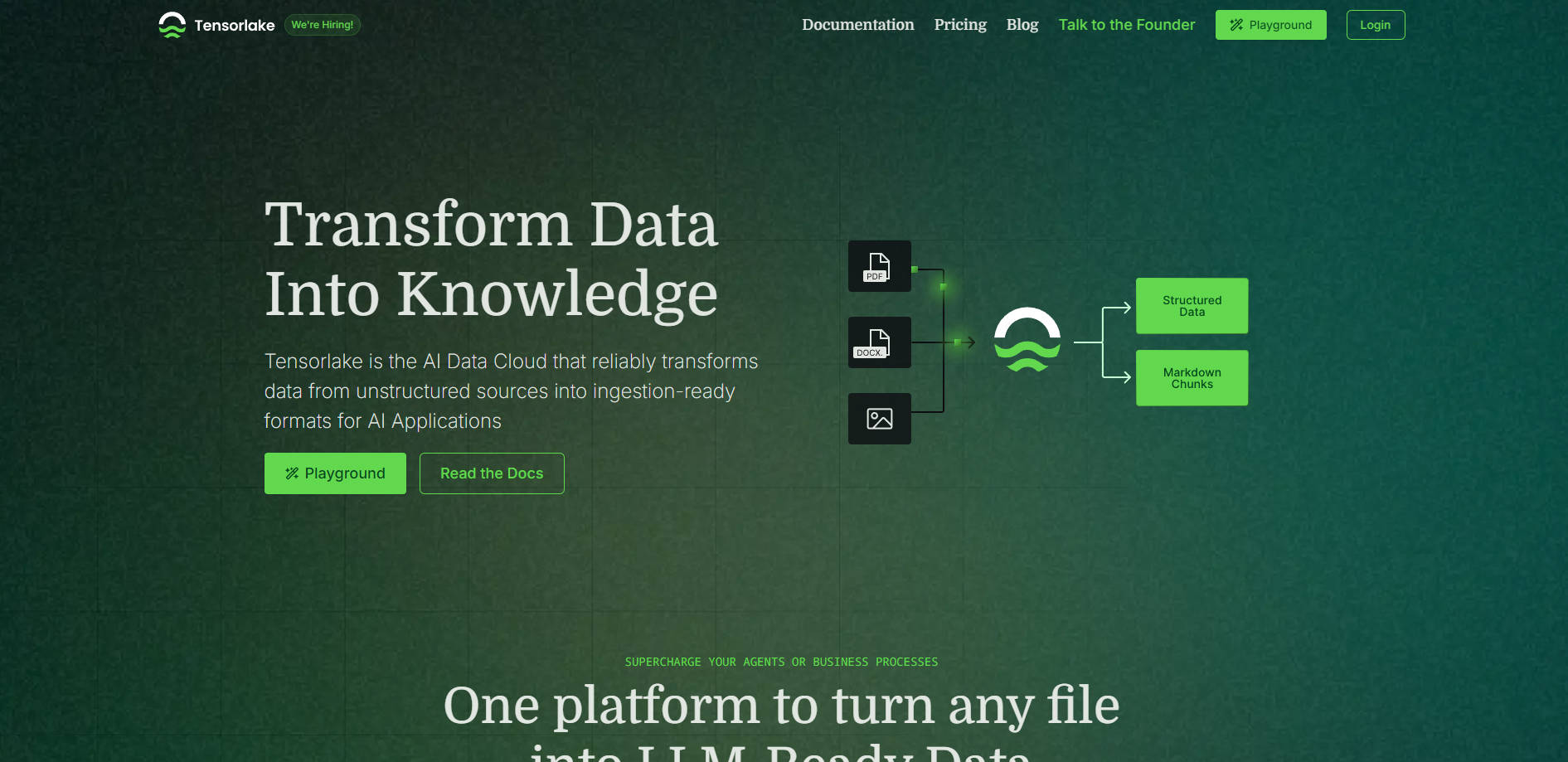
📄 处理任何文件类型: 处理文档、图像、幻灯片、手写笔记、电子表格等。Tensorlake 的 Document Ingestion API 可以解析各种格式,同时保留关键元素,如阅读顺序和布局,使人工智能能够像人类一样理解文档。
🔍 提取结构化信息: 超越简单的解析。使用模式引导的结构化提取,将文档中的特定数据点提取到 JSON 或 markdown 格式中,非常适合输入到数据库或自动化业务流程。即使是跨越数十万页的复杂表格或文档,也能胜任。
🏗️ 构建无服务器数据工作流: 使用 Python 编排端到端的数据处理管道。Tensorlake Workflows 是完全托管的,可以自动从零扩展,以处理海量数据,而无需您管理服务器、队列或复杂的并行处理框架。
⚡ 实现无限扩展: 高效处理大量数据。该平台旨在处理每秒数万个请求,并每天处理超过 100,000 份客户文档,为要求苛刻的应用程序提供所需的吞吐量和低延迟。
🔒 确保数据安全: 通过内置的安全功能保护您的敏感信息。利用基于角色的访问控制 (RBAC) 和命名空间进行精确的数据访问管理,实现安全的团队协作,并通过详细的日志保持合规性的可见性。
用例
增强检索增强生成 (RAG): 通过向 RAG 系统提供从各种文档中提取的高质量结构化数据块,提高其准确性和相关性。Tensorlake 的解析和分块功能可确保保留原始文档的上下文和布局,从而获得更好的检索结果。
自动化业务流程: 简化诸如发票处理或将数据输入 CRM 系统等操作。使用结构化提取自动识别并从文档中提取关键信息(如帐号、客户姓名、应付金额和日期),从而大大减少人工工作和潜在错误。
构建自定义数据管道: 为非结构化数据创建复杂的多步骤数据转换和丰富管道。在 Python 中定义工作流以处理来自摄取的数据,使用 Tensorlake Functions 应用自定义逻辑或模型,并将结果集成到您的数据库或下游系统中,所有这些都在无服务器基础设施上进行管理。
对于面临使非结构化数据可供人工智能使用的挑战的开发者,Tensorlake 提供了一个强大的平台。通过将强大的文档提取与灵活、可扩展的无服务器工作流相结合,它简化了解析、提取和转换数据的过程。这使您可以专注于构建创新的人工智能应用程序,并确信您的数据可以可靠、安全且大规模地进行处理。
More information on Tensorlake
Top 5 Countries
35.01%
32.28%
24.95%
4.69%
1.93%
United States
Korea, Republic of
India
Vietnam
Colombia
Traffic Sources
7.15%
1.03%
0.06%
4.83%
19.58%
67.26%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Jan 4, 2026)
Tensorlake was manually vetted by our editorial team and was first featured on 2025-05-16.
Related Searches
Tensorlake 替代方案
更多 替代方案-

-

UnDatasIO 是一个企业级平台,能够将非结构化数据转化为可用于人工智能的资产。它提供精准的文档解析、智能表格提取、多格式支持以及无缝的 API 集成。 立即释放您数据的潜力!
-

-

-
