
Click outside to close
What is Unstract?
Unstract is the open-source, no-code platform purpose-built for high-accuracy data extraction from complex unstructured documents using Large Language Models (LLMs). It effectively eliminates the manual complexity often associated with preparing and processing highly variant documents, allowing forward-thinking engineers and organizations demanding precision and scale to deploy reliable, auditable API and ETL pipelines for their critical unstructured data assets.
Key Features
Unstract provides the necessary architectural components to transform arbitrary document inputs into clean, reliable, and system-ready JSON or CSV data.
🧠 LLMChallenge: Dual-LLM Consensus Engine
This unique mechanism elevates data trust by employing two separate LLMs—an extractor and a challenger—to validate results. The system operates on the principle that NULL is better than wrong, catching and discarding hallucinations early in the process. This ensures that only accurate, verified values are returned, significantly enhancing the integrity of your automated workflows.
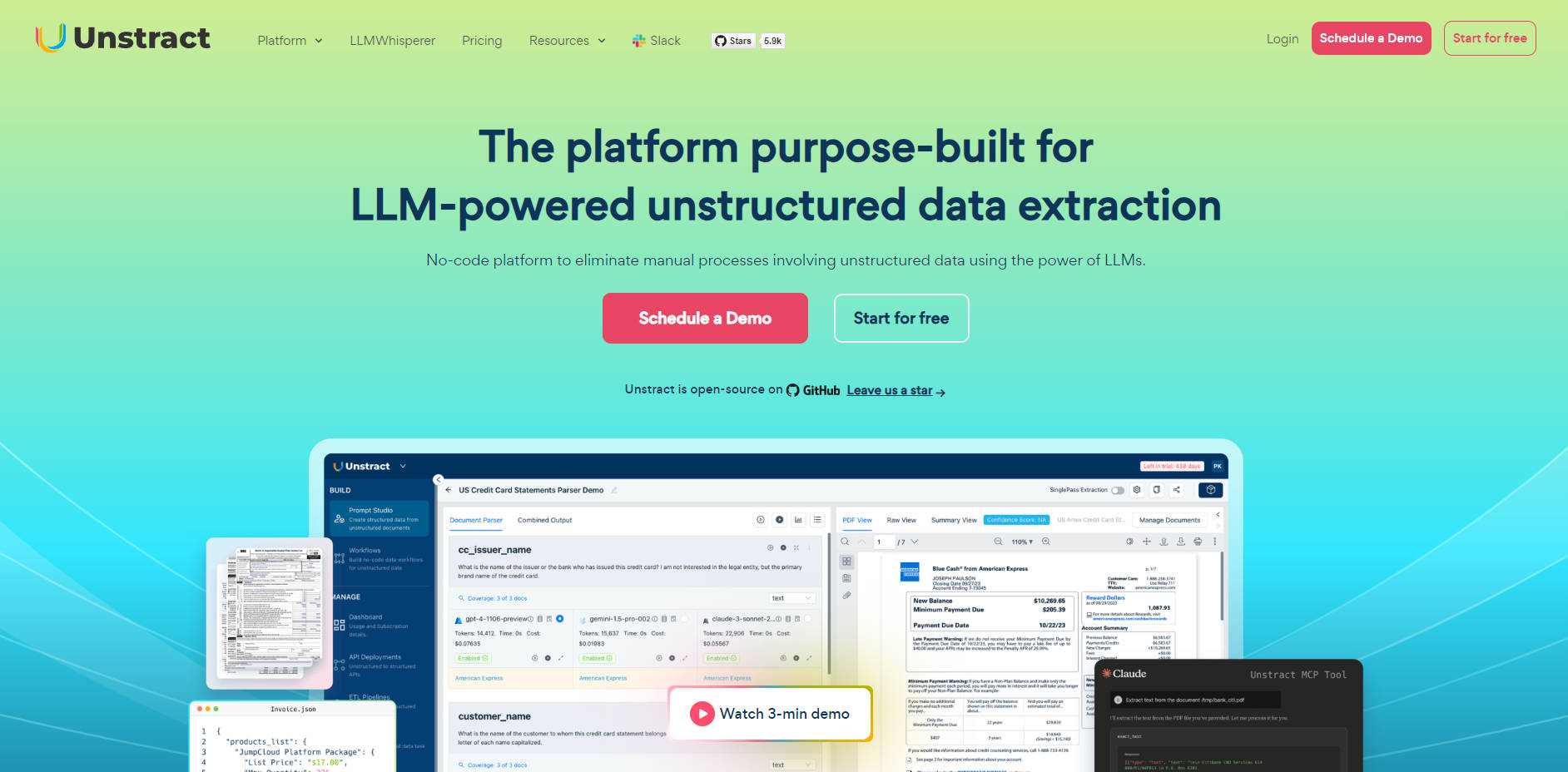
🛠️ Prompt Studio: Dedicated Engineering Environment
The Prompt Studio offers a specialized canvas for prompt engineers to build, test, and refine extraction logic at speed. You can build generic prompts quickly from a small sample of representative documents, enforce consistent schema (from simple text to nested JSON), and leverage built-in versioning for easy testing and rollback. This capability provides the control needed for complex, high-fidelity deployments.
🖼️ LLMWhisperer: Layout-Preserving Document Preparation
Dealing with real-world documents—scanned PDFs, multi-column forms, or smartphone-captured images—requires intelligent pre-processing. The LLMWhisperer acts as a companion service, producing highly optimized output in a format LLMs can best understand. Its unique layout-preserving mode allows LLMs to accurately interpret multi-column layouts, forms, tables, and even reliably detect handwritten text, checkboxes, and radio buttons.
⚡ SinglePass & Summarized Extraction for Cost Efficiency
Achieve dramatic cost savings and speed improvements by optimizing token usage. SinglePass Extraction consolidates all field extraction prompts into one large, single execution against the full document. Alternatively, Summarized Extraction automatically constructs an extremely compact version of the input document, running prompts against this optimized version to process lesser text. These strategies can reduce token usage by up to 7x, providing maximum extraction with minimum cost.
🧑💻 Human-in-the-Loop (HITL) Validation
For production-grade data that requires absolute certainty, the HITL feature bridges the gap between automated extraction and flawless data. You can configure smart routing rules based on confidence scores or field values, ensuring your team only reviews edge cases. Users can view extracted data side-by-side with source documents, utilizing Source Document Highlighting for instant verification, editing mistakes, and maintaining a completely auditable trail.
Use Cases
Unstract is built to handle the complexity and scale that traditional Intelligent Document Processing (IDP) and Robotic Process Automation (RPA) systems struggle with.
High-Variation Document Processing: Easily automate tasks involving highly variant documents, such as processing bank statements from 200 different banks or handling the same form with variations across 50 different states. Unstract ensures consistent, structured JSON output irrespective of the document variant.
Automating Complex Contract Analysis: Engineers can leverage LLMWhisperer and SinglePass extraction to efficiently extract specific, detailed line items from invoices or pinpoint critical clauses within long legal contracts, turning previously human-only review tasks into reliable, automated workflows.
Data Ecosystem Integration: Structure unstructured documents stored in cloud file storage and automatically push them to data warehouses and databases using pre-built ETL pipelines. Alternatively, embed extraction capabilities directly into existing applications by calling Unstract APIs, enabling seamless document structuring at the point of ingestion.
Unique Advantages
Unstract is designed to surpass the limitations of legacy document processing solutions, focusing on speed, accuracy, and engineering flexibility.
Trust Through Consensus: The LLMChallenge (Dual-LLM consensus engine) is a core differentiator, catching and eliminating hallucinations where legacy systems rely solely on confidence scores or single-model outputs. This guarantees production-grade data integrity.
Maximum Efficiency, Minimum Cost: Achieve up to 7x token usage reduction through specialized optimization techniques like SinglePass and Summarized Extraction. This dramatically lowers operational costs while increasing processing speed.
Open-Source Flexibility: As an open-source, no-code platform, Unstract provides organizations with complete transparency and control. It supports multi-LLM environments (OpenAI, Claude, Azure GPT, Vertex) and allows you to select the best Vector DB, Embedding Model, and Text Extraction service for your specific compliance and performance needs.
Beyond IDP and RPA: By leveraging cutting-edge LLM capabilities, Unstract addresses the core challenges of unstructured data—specifically high variation and inconsistent formats—going beyond the rule-based or template-dependent limitations of traditional IDP and RPA.
Conclusion
Unstract provides the necessary tooling and production architecture to turn complex, high-variation documents into structured, trustworthy data ready for deployment. Built for precision and scale, it empowers engineers to achieve improved automation scaling and significantly reduced manual oversight.
Explore how Unstract can help you achieve maximum extraction efficiency and deploy your next data pipeline. Start your 14-day free trial today.
More information on Unstract
Top 5 Countries
14.99%
8.71%
8.58%
7.61%
6.02%
United States (14.99%)
Nigeria (8.71%)
India (8.58%)
Brazil (7.61%)
Germany (6.02%)
Traffic Sources
15.81%
9.05%
40.45%
33.65%
social (15.81%)
paidReferrals (0.86%)
mail (0.11%)
referrals (9.05%)
search (40.45%)
direct (33.65%)
Source: Similarweb (Sep 24, 2025)
Unstract was manually vetted by our editorial team and was first featured on 2024-06-19.
Unstract Alternatives
Unstract Alternatives-

Automate high-precision structured data extraction from any document with NuExtract AI. Get reliable, low-hallucination results for critical workflows.
-

Unsiloed AI is a cutting-edge platform that transforms unstructured documents into structured, actionable data using advanced AI agents.
-

DocStrange: Open-source Python library. Transform any document into AI-ready, structured data for LLMs & RAG with privacy & accuracy.
-

Parse Extract: Advanced data extraction & OCR for LLM pipelines. Transform complex documents & web data into clean, LLM-ready text. Cost-efficient & secure.
-

DeepTagger: No-code AI automates intelligent document data extraction. Turn complex documents into structured, actionable data & unlock insights.