
Click outside to close
What is Tensorlake?
在建構人工智慧應用程式時,處理非結構化資料是一項常見的挑戰,尤其是那些由大型語言模型 (LLMs) 驅動的應用程式。文件、圖片和簡報都蘊藏著寶貴的資訊,但要將這些資訊轉換成結構化、可供人工智慧使用的格式,需要投入大量的努力。您需要可靠的方法來剖析複雜的檔案、提取特定的資料點,並建構穩健的管線來大規模地處理所有事務。
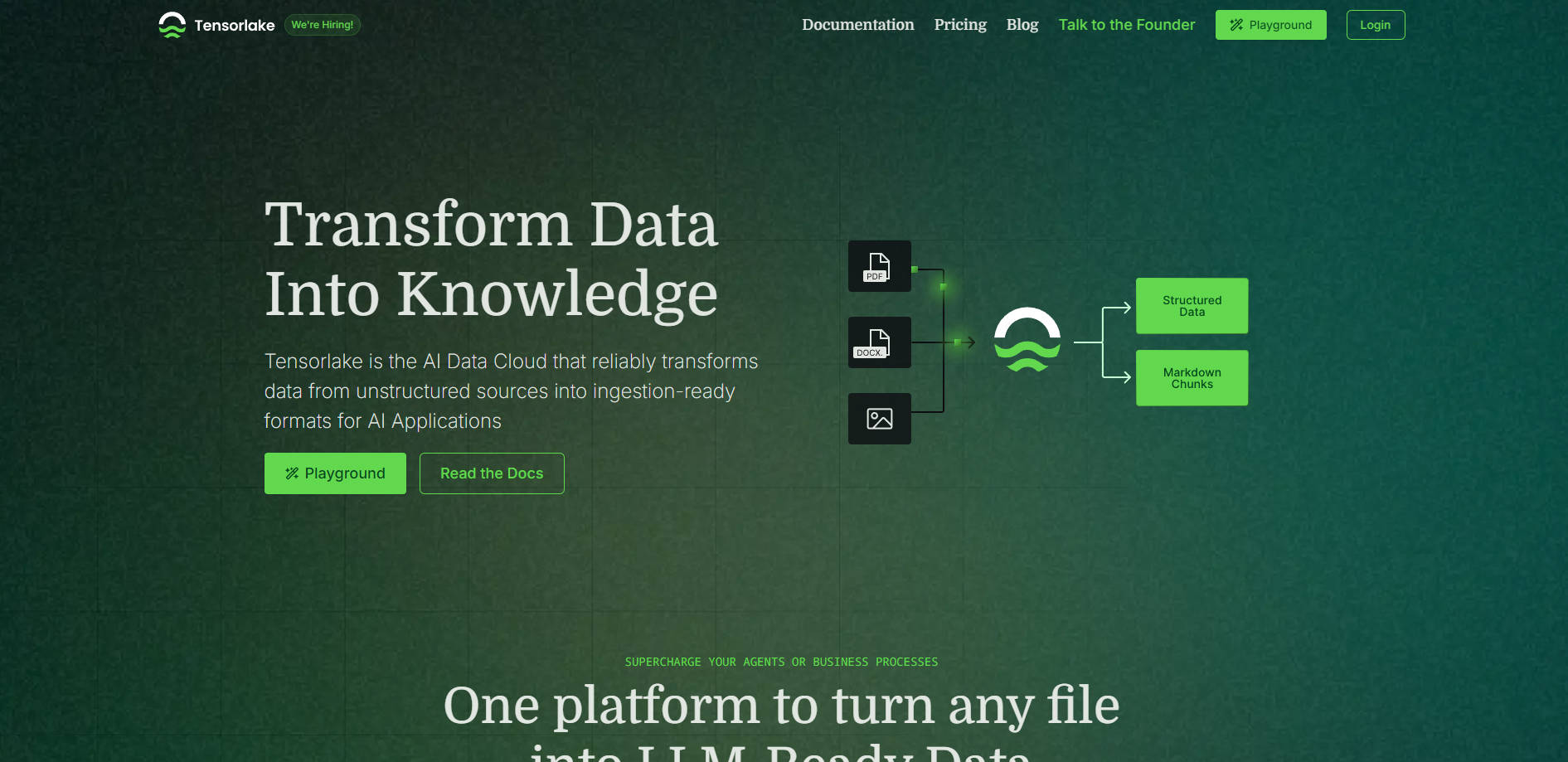
Tensorlake 提供了一個專用的人工智慧資料雲平台,旨在可靠地將來自各種來源的非結構化資料轉換為可供您的人工智慧應用程式攝取的格式。它可以幫助開發人員簡化將混亂的真實世界檔案轉換為 LLMs 可以有效使用的結構化資料的過程,從而釋放自動化、分析和知識檢索的新可能性。
主要功能
📄 處理任何檔案類型: 處理文件、圖片、投影片、手寫筆記、試算表等。Tensorlake 的 Document Ingestion API 可以剖析各種格式,同時保留重要的元素,例如閱讀順序和版面配置,使人工智慧能夠像人類一樣理解文件。
🔍 提取結構化資訊: 超越簡單的剖析。使用 schema-guided structured extraction 從文件中提取特定的資料點到 JSON 或 markdown 格式,非常適合饋送到資料庫或自動化業務流程。即使是複雜的表格或跨越數十萬頁的文件,也能正常運作。
🏗️ 建構無伺服器資料工作流程: 使用 Python 編排端到端的資料處理管線。Tensorlake Workflows 是完全託管的,可以從零開始自動擴展,以處理大量的資料,而無需您管理伺服器、佇列或複雜的平行處理框架。
⚡ 實現無限擴展: 高效地處理大量的資料。該平台旨在處理每秒數萬個請求,並且每天為每個客戶處理超過 100,000 份文件,從而為要求嚴苛的應用程式提供所需的吞吐量和低延遲。
🔒 確保資料安全: 使用內建的安全功能保護您的敏感資訊。利用基於角色的存取控制 (RBAC) 和命名空間來實現精確的資料存取管理,從而實現安全的團隊協作,並通過詳細的日誌來保持合規性。
使用案例
增強檢索增強生成 (RAG): 通過將來自各種文件的高品質、結構化的區塊饋送到 RAG 系統,來提高其準確性和相關性。Tensorlake 的剖析和分塊功能可確保保留原始文件的上下文和版面配置,從而獲得更好的檢索結果。
自動化業務流程: 簡化發票處理或將資料輸入到 CRM 系統等操作。使用結構化提取自動識別和提取文件中的關鍵資訊(例如帳戶號碼、客戶名稱、到期金額和日期),從而大大減少手動工作和潛在的錯誤。
建構自定義資料管線: 為非結構化資料創建複雜的、多步驟的資料轉換和豐富管線。在 Python 中定義工作流程以處理來自攝取的資料,使用 Tensorlake Functions 應用自定義邏輯或模型,並將結果整合到您的資料庫或下游系統中,所有這些都在無伺服器基礎架構上進行管理。
Tensorlake 為面臨使非結構化資料可用於人工智慧的挑戰的開發人員提供了一個強大的平台。通過將穩健的文件攝取與靈活、可擴展的無伺服器工作流程相結合,它簡化了剖析、提取和轉換資料的過程。這使您可以專注於構建創新的人工智慧應用程式,並確信您的資料可以可靠、安全地且大規模地進行處理。
More information on Tensorlake
Top 5 Countries
35.01%
32.28%
24.95%
4.69%
United States (35.01%)
Korea, Republic of (32.28%)
India (24.95%)
Vietnam (4.69%)
Colombia (1.93%)
Traffic Sources
7.15%
4.83%
19.58%
67.26%
social (7.15%)
paidReferrals (1.03%)
mail (0.06%)
referrals (4.83%)
search (19.58%)
direct (67.26%)
Source: Similarweb (Jan 4, 2026)
Tensorlake was manually vetted by our editorial team and was first featured on 2025-05-16.
Tensorlake 替代方案
Tensorlake 替代方案-

Activeloop-L0:您的 AI 知識代理人,旨在為您帶來精確且可溯源的深入洞見,全面解析您的多模態企業資料。安全部署於您的專屬雲端環境,效能凌駕 RAG 架構。
-

UnDatasIO 是一個企業級平台,能將非結構化資料轉化為可供 AI 使用的資產。它提供精準的文件剖析、智慧表格擷取、多格式支援以及無縫的 API 整合。今天就來釋放您資料的潛力吧!
-

-

Unsiloed AI 是一個領先的尖端平台,它運用先進的人工智慧代理程式,將非結構化文件梳理成有條理且具實用價值的結構化資料。
-

Unstract:開源、無程式碼的大型語言模型平台,專為高準確度的非結構化資料萃取而設計。輕鬆從複雜文件中擷取可靠、可稽核的資料。