
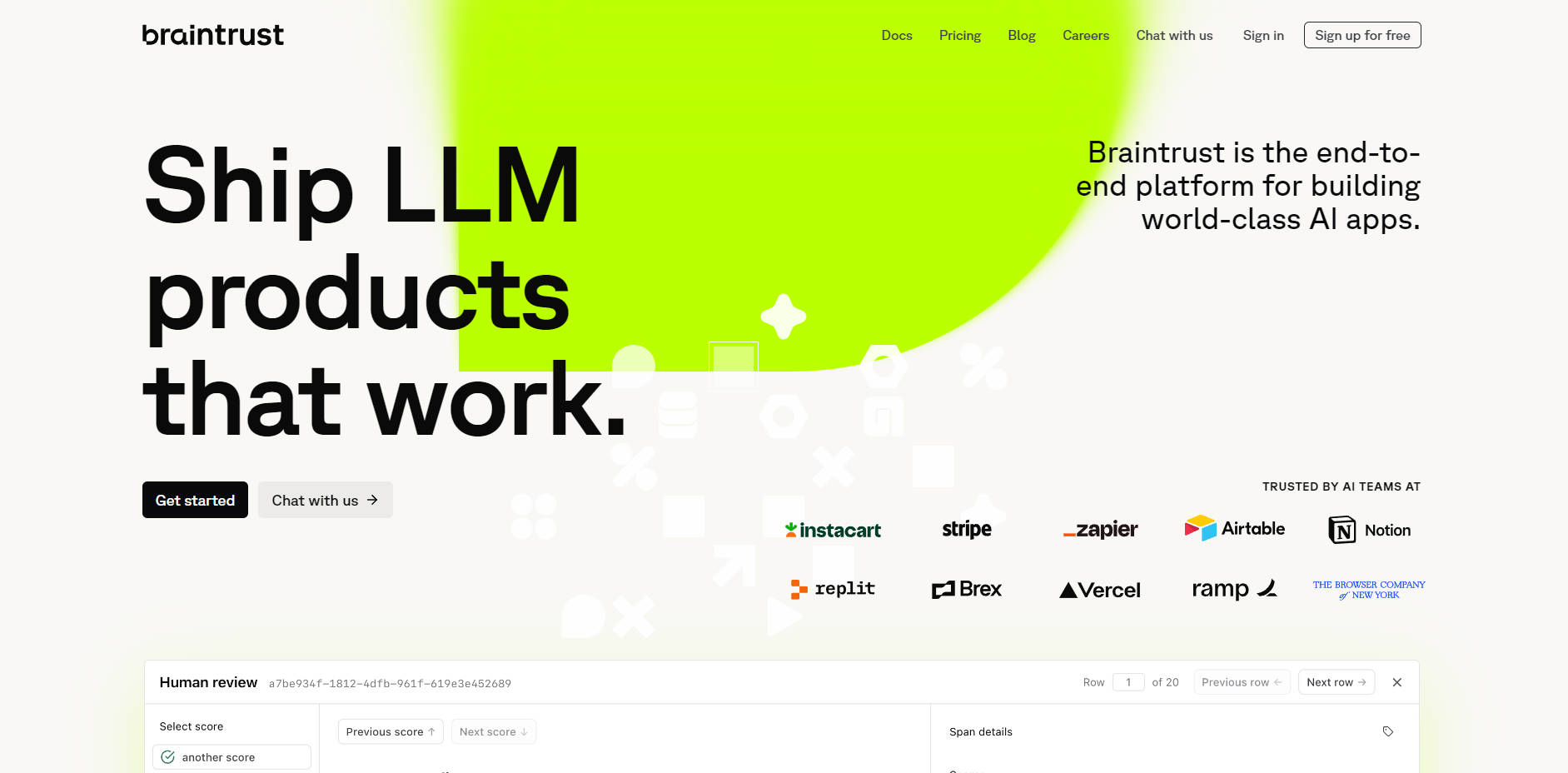
What is Braintrust?
開發大型語言模型(LLM)應用程式面臨著獨特的挑戰,從難以預測的輸出到缺乏結構化的測試。Braintrust 是一個端到端的評估平台,專為協助AI團隊克服這些複雜性而設計。我們提供您所需的工具,讓您能夠以嚴謹的工程紀律開發、測試和監控由LLM驅動的產品,確保您交付的應用程式能在真實世界中可靠運作。
主要功能
Braintrust 提供一套整合式工具套件,旨在為您的AI開發生命週期帶來清晰度和掌控力。
📊 全方位模型與提示詞評估 別再憑空猜測,開始精準衡量。您可以針對您的資料集,系統性地比較來自OpenAI、Anthropic和Google等供應商的不同提示詞與模型。使用業界標準或自訂評分器,可產生關於品質、成本和延遲的客觀、可量化指標,讓您能夠做出資料導向的決策。
🧪 互動式開發試驗場 在強大、協作的工作空間中加速您的迭代週期。該試驗場可讓您快速進行原型設計,並並排測試不同的提示詞、模型和資料組合。這有助於您快速建立假設並找到有效的方法,無需複雜耗時的設定。
🗂️ 集中式與版本化資料集 為您所有的評估資料建立單一事實來源。您可以在一個安全、可擴展的位置,擷取、管理和版本控制您的「黃金」測試案例和評分過的生產範例。這確保您的團隊每次都能運行一致且可重現的評估。
📈 生產日誌記錄與監控 深入了解您的應用程式部署後的實際表現。Braintrust 讓您能夠記錄和分析真實世界的互動,提供可操作的洞察,以調試問題、識別新的邊緣案例,並根據實際用戶行為持續改進您的產品品質。
Braintrust 如何解決您的問題:
Braintrust 旨在解決AI開發中實際的日常挑戰。以下是您如何應用它的方法:
改進表現不佳的AI功能: 當用戶回報由AI驅動的功能出現問題時,您可以使用 Braintrust 記錄這些有問題的互動。將這些範例整理成新的評估資料集,然後使用 Playground 試驗改進後的提示詞或不同的模型。最後,運行全面的評估以比較新舊版本,確保您的修復在發布前是可衡量的改進。
針對新任務比較LLM供應商: 選擇正確的模型對於性能和成本至關重要。藉助 Braintrust,您可以設定一個實驗,將相同的提示詞和資料集應用於來自多個供應商的模型。評估結果將為您提供準確性、速度和成本的清晰並排比較,讓您能夠針對特定使用案例做出明智且基於證據的決策。
確保CI/CD流程的品質: 使用SDK將 Braintrust 評估直接整合到您的開發工作流程中。就像您為傳統軟體運行單元測試一樣,您可以在每次代碼更改時自動運行AI評估。這有助於您及早發現迴歸問題,並確保每次更新都能維持或提高您的AI應用程式品質。
獨特優勢
真正的端到端工作流程: Braintrust 的強大之處在於其工具的無縫整合。該平台創建了一個持續的意見回饋循環,讓您可以從記錄生產問題、創建測試案例、在試驗場中迭代,到自信地部署經過驗證的改進。
專為現代工程技術棧而打造: 我們明白AI開發是一項團隊合作,必須融入現有流程。憑藉強大的SDK(TypeScript/Python)、穩健的API,以及支援自行託管選項以實現最大程度的資料控制,Braintrust 旨在增強您的工程技術棧,而非擾亂它。
結論:
Braintrust 用結構化、迭代式和資料驅動的流程取代了AI開發中的猜測。它賦能您的整個團隊——從開發人員到產品經理——有效協作,並自信地交付更高品質的AI產品。
探索 Braintrust 如何為您的AI開發生命週期帶來可靠性和精確性!
More information on Braintrust
Launched
2023-03
Pricing Model
Freemium
Starting Price
$249 / month
Global Rank
196333
Follow
Month Visit
174.6K
Tech used
Next.js,Vercel,Webpack,HSTS
Top 5 Countries
60.41%
7.54%
2.36%
2.26%
1.63%
United States
India
United Kingdom
France
Belgium
Traffic Sources
3.99%
0.53%
0.13%
10.59%
31.36%
53.36%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Braintrust was manually vetted by our editorial team and was first featured on 2023-09-30.
Related Searches
Braintrust 替代方案
更多 替代方案-
-

-

Deepchecks:大型語言模型(LLM)的端對端評估平台。 從開發到上線,有系統地測試、比較並監控您的AI應用程式。 有效降低幻覺,並加速產品上市。
-
-
