
What is MakeSense?
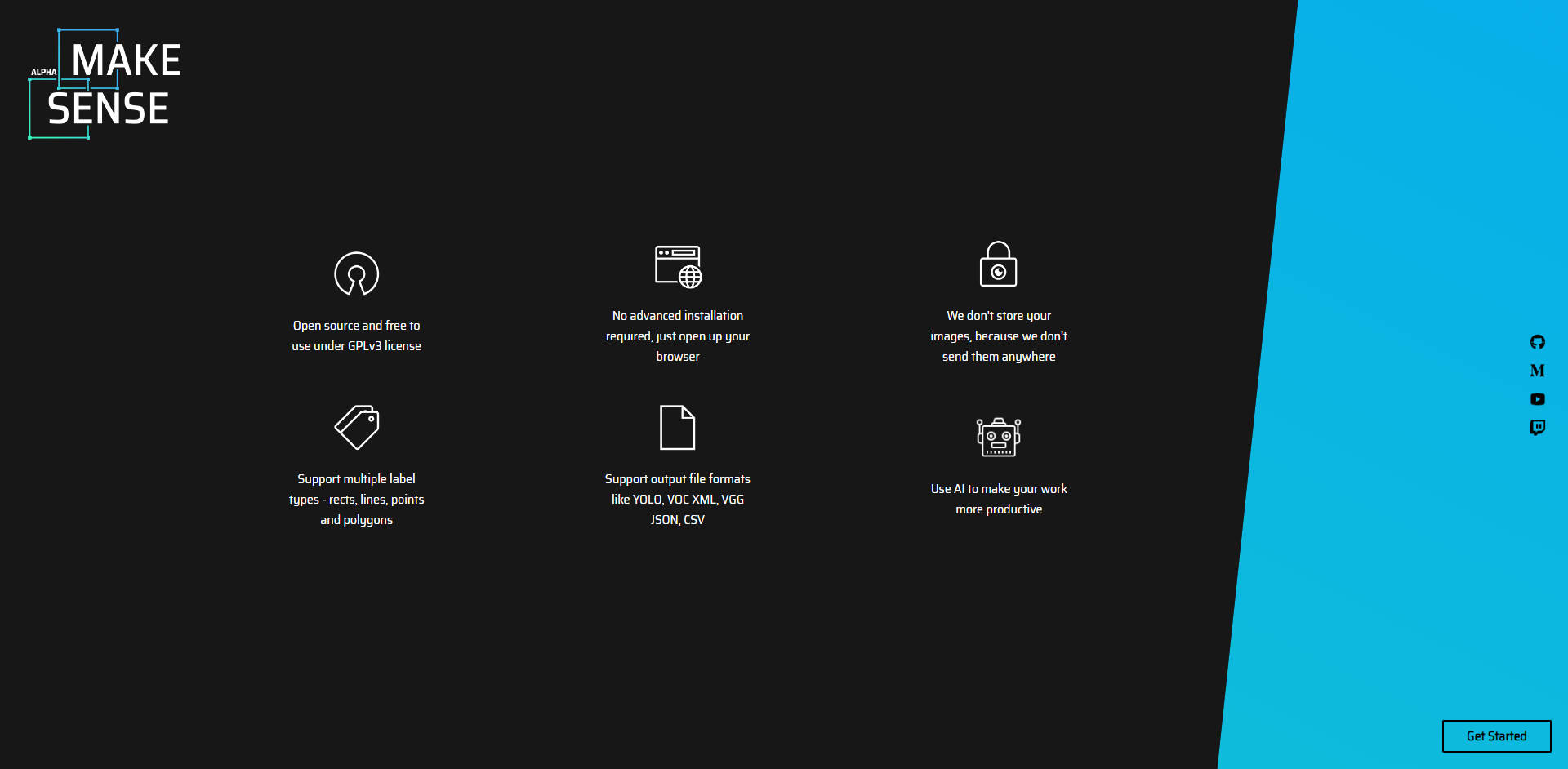
makesense.ai 是一款免費的線上工具,旨在簡化並加速電腦視覺專案的影像標註流程。如果您正在進行深度學習專案,並且需要準備資料集,makesense.ai 能消除複雜的軟體安裝和繁瑣的手動標註所帶來的麻煩。由於它直接在您的瀏覽器中運行,因此您可以立即開始標註,不受作業系統的限制。
主要功能:
🚀 立即開始: 直接透過您的網頁瀏覽器存取此工具,無需下載或安裝。這種跨平台相容性意味著您可以在 Windows、macOS 或 Linux 上使用它。
🤖 利用 AI 驅動的輔助功能: 透過整合的 AI 模型,減少您的標註時間。
YOLOv5 整合: 載入預先訓練的模型或您自己的自訂 YOLOv5 模型(匯出為 tfjs 格式),以獲得強大的物件偵測建議。
SSD (COCO): 受益於 COCO 資料集上預先訓練的 Single Shot MultiBox Detector 模型,以自動生成邊界框並建議標籤。
PoseNet: 利用 PoseNet 透過識別關鍵身體關節來估計人體姿勢,從而簡化帶有人物影像的註釋。
🧠 由 TensorFlow.js 驅動: makesense.ai 的 AI 功能核心是 TensorFlow.js,確保高效處理,最重要的是,保護您的影像隱私。您的資料永遠不會離開您的裝置。
📁 以多種格式匯出: 以各種格式下載您完成的標籤,這些格式與流行的機器學習框架相容,包括 CSV、YOLO、VOC XML、VGG JSON 和 COCO JSON。此外,還提供像素遮罩匯出的支援,但並非適用於所有標籤類型。
⌨️ 透過鍵盤快捷鍵高效工作: 使用直觀的鍵盤快捷鍵加速您的工作流程,以執行常見操作,例如多邊形完成、影像導航和標籤選擇。
✅ 匯入現有標籤: 匯入以下格式的標籤:矩形: YOLO, VOC XML, VGG JSON, COCO JSON, 多邊形: COCO JSON。
技術細節(適用於開發人員和進階使用者):
架構: makesense.ai 是使用 TypeScript 建構的,並利用 React/Redux 框架來實現響應式且使用者友好的介面。
本地設定: 對於開發人員,可以輕鬆地從 GitHub 儲存庫中複製該專案,並使用 npm 在本地運行。(需要 npm 8.x.x 和 Node.js v16.x.x)。
Docker 支援: 提供了一個 Dockerfile 以進行容器化部署,簡化了設定並確保在不同環境中實現一致的操作。
開放原始碼: 該專案是開放原始碼的,允許社群貢獻和自訂修改。
使用案例:
自動駕駛車輛的物件偵測: 一個開發自動駕駛汽車技術的團隊需要標註數千張影像,並在汽車、行人和交通號誌周圍繪製邊界框。makesense.ai 的 YOLOv5 整合提供了智慧建議,從而大大減少了所需的手動工作。然後,團隊可以匯出與其訓練管道相容的格式的標籤。
健身應用程式的人體姿勢估計: 一位開發人員正在創建一個健身應用程式,該應用程式可以追蹤使用者在鍛鍊期間的運動,他們使用 makesense.ai 及其 PoseNet 整合來註釋影像和影片中的關鍵身體關節。此標記的資料用於訓練可以準確識別和分析運動形式的模型。
電子商務的影像分類: 一家電子商務公司需要對大量產品影像目錄進行分類。makesense.ai 允許他們快速在商品周圍繪製邊界框並分配標籤。然後,匯出的資料用於改進產品搜尋和推薦演算法。
結論:
makesense.ai 為影像標註提供了一個強大、使用者友善且注重隱私的解決方案。無論您是學生、研究人員還是專業開發人員,makesense.ai 都能簡化您的工作流程,讓您可以專注於構建和訓練您的電腦視覺模型。它結合了 AI 驅動的輔助功能、基於瀏覽器的可訪問性和靈活的匯出選項,使其成為任何電腦視覺專案的寶貴工具。
More information on MakeSense
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
MakeSense was manually vetted by our editorial team and was first featured on 2025-02-24.
Related Searches
MakeSense 替代方案
更多 替代方案-

-
PredictSense 是一個由 AutoML 支援的端到端機器學習平台,用於建立 AI 驅動的分析解決方案。透過加速機器智慧,為明日科技革命注入新動力。
-

-
-
