
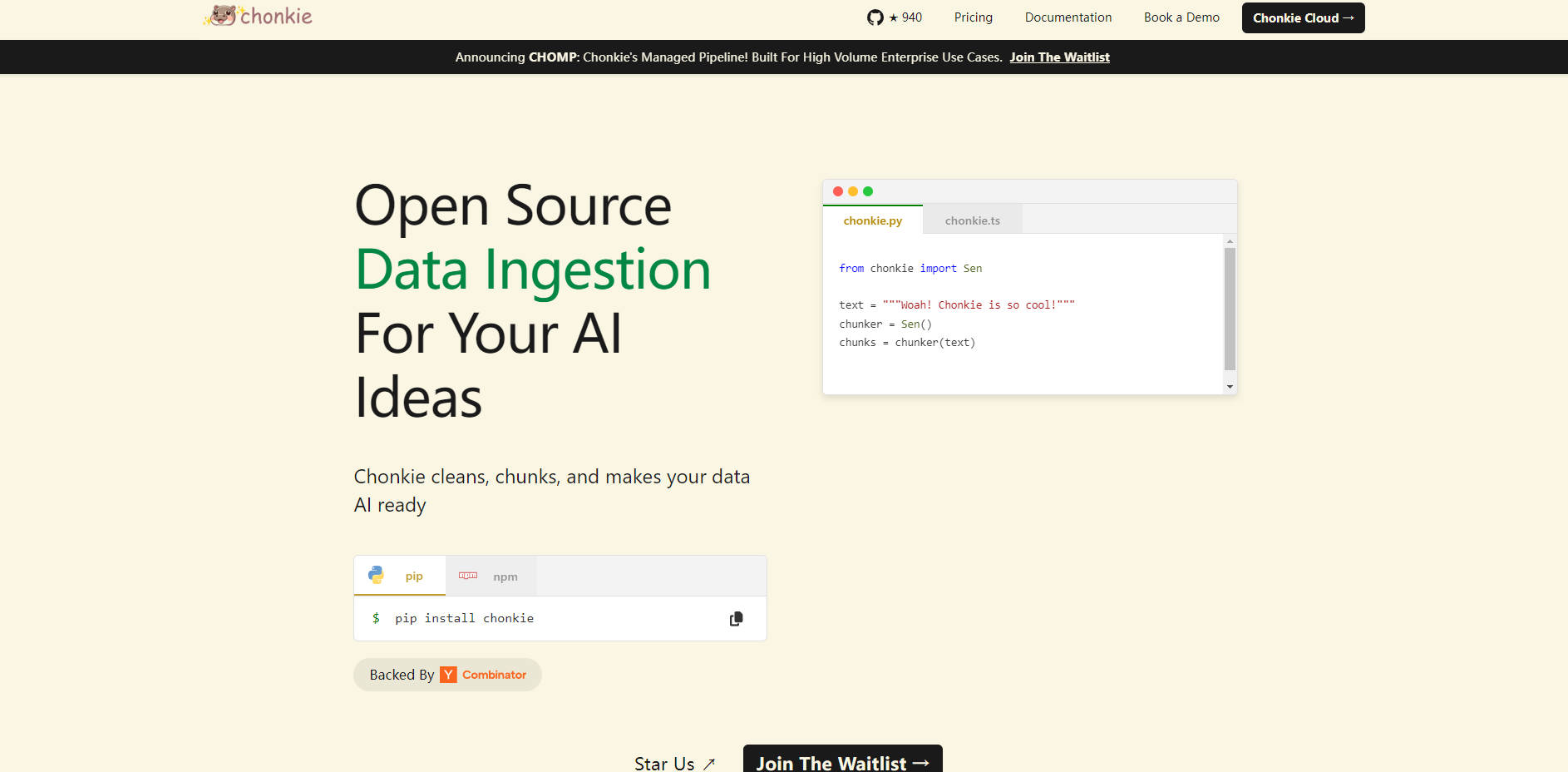
What is Chonkie?
Building effective Retrieval-Augmented Generation (RAG) systems often hinges on how well you prepare your source data. A critical, yet frequently challenging, step is splitting your documents into meaningful, AI-ready pieces – a process known as chunking. Developers repeatedly face the need for robust, yet straightforward, chunking solutions, often finding existing libraries either overly complex and bloated or lacking essential features.
Chonkie addresses this challenge directly. It's designed as a focused, high-performance library that provides the essential tools you need to transform raw text data into optimized chunks for your RAG applications, all while keeping things simple and efficient.
Key Capabilities
Effortless Integration ✨: Get started quickly with a simple
pip installand intuitive API. Integrate chunking into your pipeline with minimal setup, allowing you to focus on other aspects of your RAG system.Exceptional Speed ⚡: Process your text data at impressive speeds. Benchmarks show Chonkie performing common chunking tasks significantly faster than alternatives – up to 33x faster for token chunking and 2.5x faster for semantic chunking.
Remarkably Lightweight 🪶: Avoid unnecessary dependencies and overhead. Chonkie boasts a minimal installation size, keeping your project dependencies lean. Even with advanced features like semantic chunking, it remains substantially lighter than competing libraries.
Comprehensive Chunking Strategies 🧠: Access a variety of chunking methods, including token-based, sentence-based, recursive, semantic, code-specific, and even methods leveraging neural models or LLMs, ensuring you have the right tool for different text types and retrieval goals.
Wide Ecosystem Support 🌍: Connect seamlessly with your existing AI stack. Chonkie integrates with numerous tokenizers (5+), embedding providers (6+), LLM providers (2+), and vector databases (3+ like Chroma, Qdrant, Turbopuffer), offering flexibility in your tooling choices.
Structured Data Processing (CHOMP Pipeline) 📄👨🍳🦛🏭🤝: Utilize a modular pipeline approach (CHOMP) that guides your data from raw documents through cleaning (Chef), chunking (Chunker), enrichment (Refinery), and final output (Porters for export, Handshakes for vector DB ingestion). This structure promotes clarity and customization.
Multilingual Ready 🌐: Handle text in various languages out-of-the-box with support for 5+ languages, expanding the applicability of your RAG systems globally.
Use Cases
Improving AI Chatbot Accuracy: By applying advanced chunking strategies like
RecursiveChunkerorSemanticChunker, developers can ensure that the retrieved text snippets provided to an LLM for answering a query are more relevant and contextually complete. This leads to more accurate responses and significantly reduces instances of hallucination.Accelerating Data Ingestion Pipelines: For applications dealing with large volumes of text data, the speed of the chunking process is critical. Using Chonkie's fast chunking methods allows developers to process and prepare data for vector databases much quicker, leading to faster updates and lower compute costs for their RAG systems.
Handling Diverse Document Types: When building RAG over a heterogeneous dataset including documents, code, and structured text, developers can utilize Chonkie's specialized chunkers, like the
CodeChunker, within the flexible CHOMP pipeline. This ensures each data type is processed optimally before being indexed, improving retrieval performance across the entire knowledge base.
Conclusion
Chonkie provides a focused, high-performance, and easy-to-integrate solution for the essential task of text chunking in RAG pipelines. Its speed, minimal footprint, diverse chunking methods, and broad integration support make it a valuable tool for developers looking to build more efficient, accurate, and maintainable AI applications. By simplifying and accelerating the data preparation stage, Chonkie helps you build better context for your models and achieve superior AI results.
More information on Chonkie
Launched
2024-11
Pricing Model
Free
Starting Price
Global Rank
1384819
Follow
Month Visit
14.5K
Tech used
HTTP/3,HSTS
Top 5 Countries
25.07%
20.04%
15.85%
11.88%
9.96%
United States
Vietnam
Nigeria
India
Belgium
Traffic Sources
8.32%
0.97%
0.07%
5.86%
37.04%
47.52%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Chonkie was manually vetted by our editorial team and was first featured on 2024-11-14.
Related Searches
Chonkie Alternatives
Load more Alternatives-

-
-

-

-

Embedchain: The open-source RAG framework to simplify building & deploying personalized LLM apps. Go from prototype to production with ease & control.