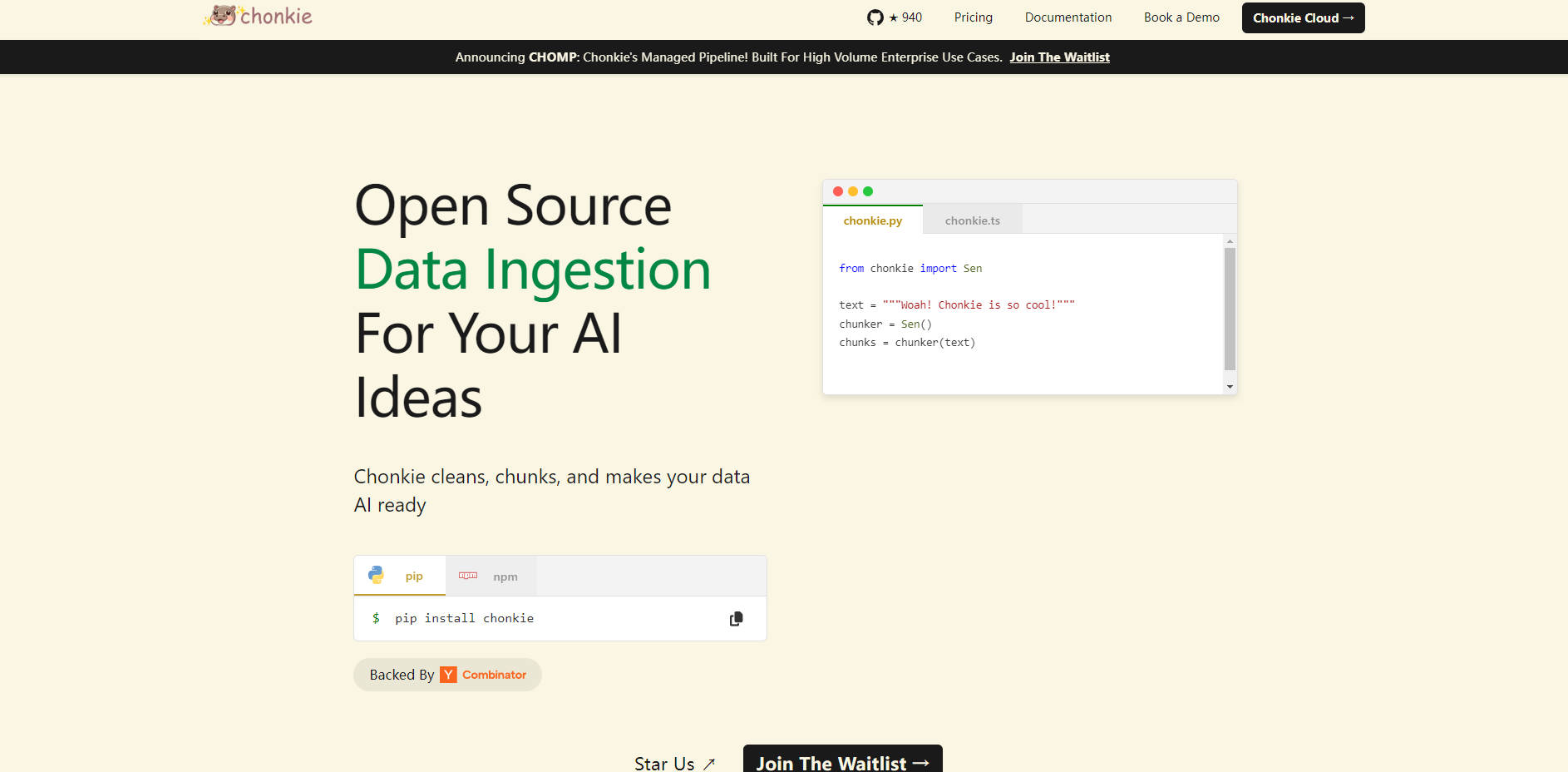
What is Chonkie?
打造有效的 Retrieval-Augmented Generation (RAG) 系統,往往取決於您準備原始資料的完善程度。其中一個關鍵但經常具有挑戰性的步驟,是將您的文件分割成有意義、適合 AI 處理的區塊,這個過程稱為分塊 (chunking)。開發人員經常面臨需要強大且簡單易用的分塊解決方案的需求,但往往發現現有的函式庫過於複雜臃腫,或是缺乏必要的功能。
Chonkie 直接應對了這個挑戰。它被設計為一個專注、高效能的函式庫,提供您將原始文字資料轉換為 RAG 應用程式優化區塊所需的基本工具,同時保持簡潔和高效。
主要功能
輕鬆整合✨:透過簡單的
pip install和直觀的 API 快速上手。以最少的設定將分塊整合到您的流程中,讓您可以專注於 RAG 系統的其他方面。卓越速度⚡:以驚人的速度處理您的文字資料。基準測試顯示,Chonkie 執行常見的分塊任務比其他替代方案快得多,token 分塊速度快達 33 倍,semantic 分塊速度快達 2.5 倍。
極其輕巧🪶:避免不必要的依賴和額外負擔。Chonkie 擁有最小的安裝大小,保持您的專案依賴關係精簡。即使具有 semantic 分塊等進階功能,它仍然比同類函式庫輕得多。
全面的分塊策略🧠:存取各種分塊方法,包括基於 token、基於句子、遞迴、語義、程式碼特定的方法,甚至是可以利用神經模型或 LLM 的方法,確保您擁有適用於不同文字類型和檢索目標的合適工具。
廣泛的生態系統支援🌍:與您現有的 AI 技術堆疊無縫連接。Chonkie 與眾多的 tokenizers (5 個以上)、embedding providers (6 個以上)、LLM providers (2 個以上) 和向量資料庫 (3 個以上,如 Chroma、Qdrant、Turbopuffer) 整合,在工具選擇方面提供靈活性。
結構化資料處理 (CHOMP Pipeline)📄👨🍳🦛🏭🤝:利用模組化的流程方法 (CHOMP),引導您的資料從原始文件經過清理 (Chef)、分塊 (Chunker)、豐富化 (Refinery) 到最終輸出 (用於匯出的 Porters,用於向量資料庫攝取的 Handshakes)。這種結構提高了清晰度和客製化程度。
多語言就緒🌐:透過支援 5 種以上的語言,開箱即用地處理各種語言的文字,從而擴大您的 RAG 系統在全球範圍內的適用性。
使用案例
提高 AI 聊天機器人的準確性:透過應用諸如
RecursiveChunker或SemanticChunker之類的進階分塊策略,開發人員可以確保提供給 LLM 用於回答查詢的檢索文字片段更相關且在上下文中更完整。這可以帶來更準確的回應,並顯著減少產生幻覺的情況。加速資料攝取流程:對於處理大量文字資料的應用程式,分塊過程的速度至關重要。使用 Chonkie 的快速分塊方法,開發人員可以更快地處理和準備用於向量資料庫的資料,從而加快更新速度並降低 RAG 系統的計算成本。
處理多樣化的文件類型:在異質資料集 (包括文件、程式碼和結構化文字) 上建構 RAG 時,開發人員可以在靈活的 CHOMP 流程中使用 Chonkie 的專用分塊器,例如
CodeChunker。這確保在索引之前以最佳方式處理每種資料類型,從而提高整個知識庫的檢索效能。
結論
Chonkie 為 RAG 流程中重要的文字分塊任務提供了一個專注、高效能且易於整合的解決方案。它的速度、最小佔用空間、多樣化的分塊方法和廣泛的整合支援使其成為希望建構更高效、更準確和更易於維護的 AI 應用程式的開發人員的寶貴工具。透過簡化和加速資料準備階段,Chonkie 幫助您為您的模型建構更好的上下文,並實現卓越的 AI 成果。
More information on Chonkie
Launched
2024-11
Pricing Model
Free
Starting Price
Global Rank
1384819
Follow
Month Visit
14.5K
Tech used
HTTP/3,HSTS
Top 5 Countries
25.07%
20.04%
15.85%
11.88%
9.96%
United States
Vietnam
Nigeria
India
Belgium
Traffic Sources
8.32%
0.97%
0.07%
5.86%
37.04%
47.52%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Chonkie was manually vetted by our editorial team and was first featured on 2024-11-14.
Related Searches