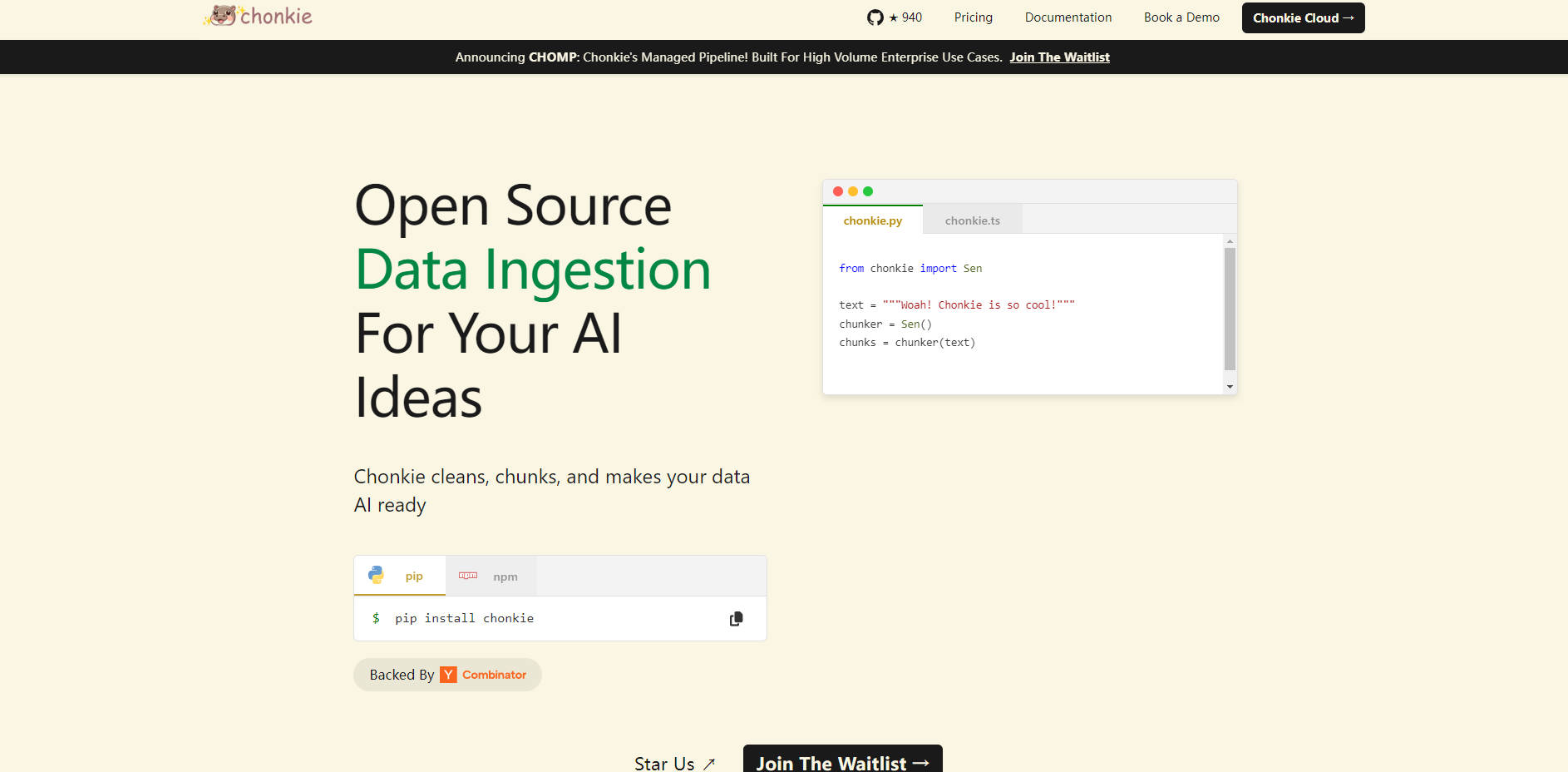
What is Chonkie?
构建有效的检索增强生成 (RAG) 系统,关键在于如何出色地准备源数据。其中至关重要但又经常充满挑战的一步,是将文档分割成有意义且适合 AI 使用的片段——这个过程被称为分块 (chunking)。开发者经常面临对强大而又简洁的分块解决方案的需求,但现有的库要么过于复杂和臃肿,要么缺乏必要的功能。
Chonkie 正是为了直接解决这一挑战而设计的。它是一个专注、高性能的库,提供将原始文本数据转换成针对 RAG 应用优化的数据块所需的基本工具,同时保持简单和高效。
主要功能
轻松集成 ✨:通过简单的
pip install和直观的 API 快速上手。将分块集成到您的流程中,只需最少的设置,让您可以专注于 RAG 系统的其他方面。卓越的速度 ⚡:以惊人的速度处理您的文本数据。基准测试表明,在执行常见的分块任务时,Chonkie 的性能明显优于其他方案——token 分块速度快达 33 倍,语义分块速度快达 2.5 倍。
非常轻量级 🪶:避免不必要的依赖和开销。Chonkie 拥有最小的安装体积,保持您项目的依赖关系精简。即使拥有像语义分块这样的高级功能,它仍然比同类库轻得多。
全面的分块策略 🧠:访问各种分块方法,包括基于 token、基于句子、递归、语义、代码特定,甚至利用神经模型或 LLM 的方法,确保您拥有适合不同文本类型和检索目标的正确工具。
广泛的生态系统支持 🌍:与您现有的 AI 技术栈无缝连接。Chonkie 与众多 tokenizers (5+)、embedding providers (6+)、LLM providers (2+) 和向量数据库 (3+,如 Chroma, Qdrant, Turbopuffer) 集成,为您在工具选择上提供灵活性。
结构化数据处理 (CHOMP Pipeline) 📄👨🍳🦛🏭🤝:利用模块化管道方法 (CHOMP),引导您的数据从原始文档开始,经过清洗 (Chef)、分块 (Chunker)、丰富 (Refinery) 和最终输出 (Porters 用于导出,Handshakes 用于向量数据库摄取)。这种结构提高了清晰度和定制性。
多语言就绪 🌐:通过支持 5 种以上的语言,开箱即用地处理各种语言的文本,从而扩展您的 RAG 系统在全球范围内的适用性。
用例
提高 AI 聊天机器人的准确性:通过应用高级分块策略,如
RecursiveChunker或SemanticChunker,开发者可以确保提供给 LLM 以回答查询的检索文本片段更相关且上下文更完整。这可以带来更准确的响应,并显着减少幻觉的发生。加速数据摄取管道:对于处理大量文本数据的应用程序,分块过程的速度至关重要。使用 Chonkie 快速分块方法使开发者能够更快地处理和准备用于向量数据库的数据,从而加快更新速度并降低 RAG 系统的计算成本。
处理多样化的文档类型:当在包含文档、代码和结构化文本的异构数据集上构建 RAG 时,开发者可以在灵活的 CHOMP 管道中使用 Chonkie 的专用分块器,如
CodeChunker。这确保了在索引之前对每种数据类型进行最佳处理,从而提高了整个知识库的检索性能。
结论
Chonkie 为 RAG 管道中必不可少的文本分块任务提供了一个专注、高性能且易于集成的解决方案。它的速度、最小占用空间、多样化的分块方法和广泛的集成支持使其成为希望构建更高效、更准确和更易于维护的 AI 应用程序的开发者的宝贵工具。通过简化和加速数据准备阶段,Chonkie 帮助您为模型构建更好的上下文,并实现卓越的 AI 结果。
More information on Chonkie
Launched
2024-11
Pricing Model
Free
Starting Price
Global Rank
1384819
Follow
Month Visit
14.5K
Tech used
HTTP/3,HSTS
Top 5 Countries
25.07%
20.04%
15.85%
11.88%
9.96%
United States
Vietnam
Nigeria
India
Belgium
Traffic Sources
8.32%
0.97%
0.07%
5.86%
37.04%
47.52%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Chonkie was manually vetted by our editorial team and was first featured on 2024-11-14.
Related Searches