
What is LMQL?
LMQL est un langage de requête spécialement conçu pour les grands modèles de langage (LLM), combinant des invites en langage naturel avec l'expressivité de Python. Il propose des fonctionnalités telles que des contraintes, le débogage, la recherche et le contrôle du flux pour faciliter l'interaction avec les LLM.
Fonctionnalités Principales :
Contraintes : Spécifiez des conditions pour que la sortie générée réponde à des critères spécifiques.
Débogage : Analysez et comprenez comment le LLM génère la sortie, ce qui aide au réglage fin et à l'identification des erreurs.
Recherche : Accédez à des invites prédéfinies pour des tâches courantes, offrant un point de départ pratique.
Contrôle du flux : Utilisez les instructions de contrôle de flux Python pour avoir plus de contrôle sur le processus de génération.
Génération et Validation Automatique de Jetons : Générez automatiquement les jetons requis et validez la séquence produite en fonction des contraintes fournies.
Prise en Charge de Code Python Arbitraire : Incluez des invites dynamiques et un traitement de texte à l'aide du code Python.
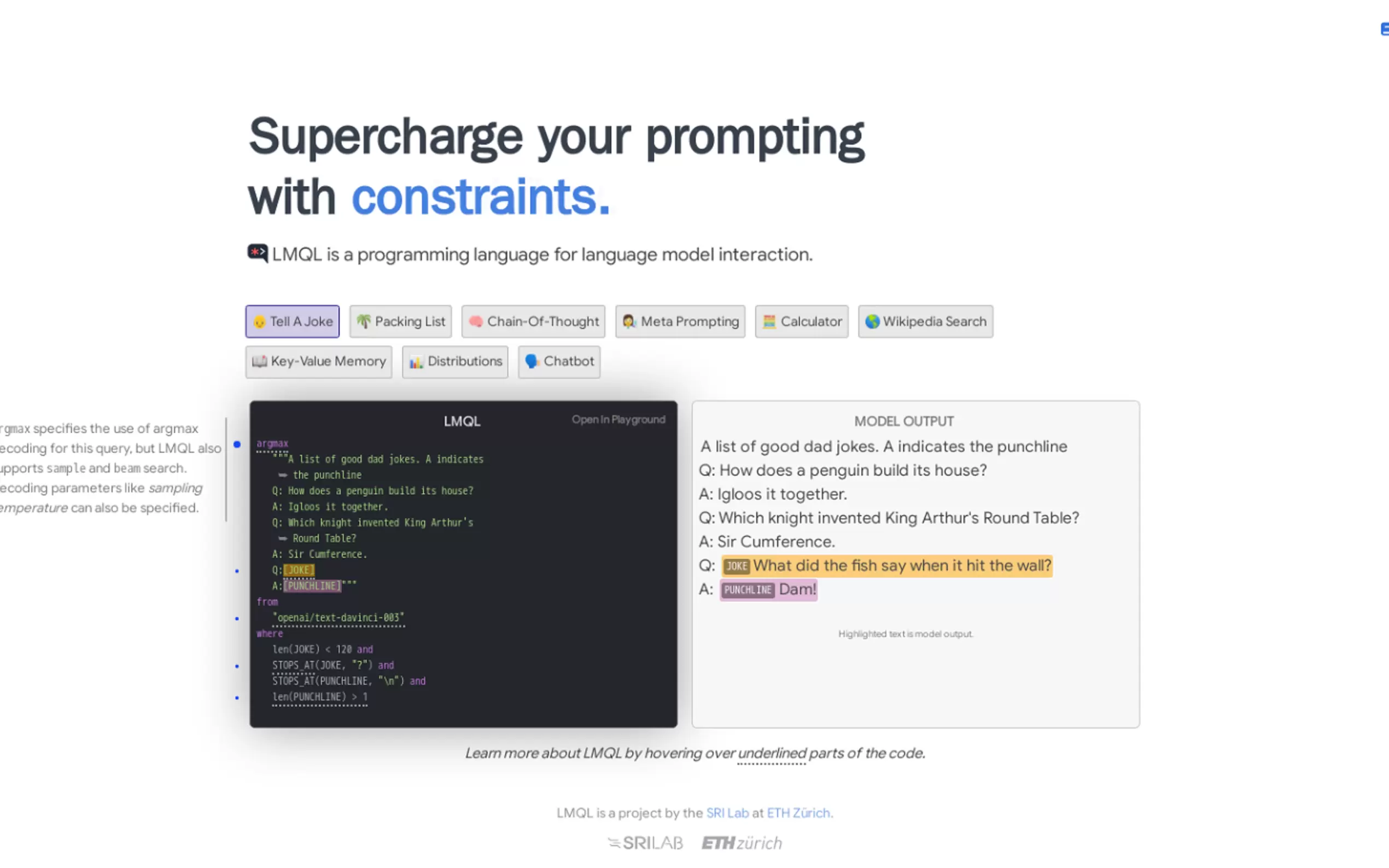
More information on LMQL
Top 5 Countries
72.28%
15.73%
7.01%
3.22%
1.76%
United States
India
Germany
Canada
Spain
Traffic Sources
8.35%
1.01%
0.06%
10.95%
34.99%
44.61%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
LMQL was manually vetted by our editorial team and was first featured on 2023-05-22.
Related Searches
LMQL Alternatives
Plus Alternatives-

LM Studio est une application de bureau intuitive, conçue pour faciliter l'expérimentation avec les Large Language Models (LLM) locaux et open-source. Cette application multiplateforme vous offre la possibilité de télécharger et d'exécuter n'importe quel modèle compatible ggml directement depuis Hugging Face. Elle intègre une interface utilisateur (UI) pour la configuration et l'inférence des modèles, se distinguant par sa simplicité d'accès et sa puissance. De plus, elle tire pleinement parti de votre GPU lorsque les conditions le permettent.
-

-

-

-
