
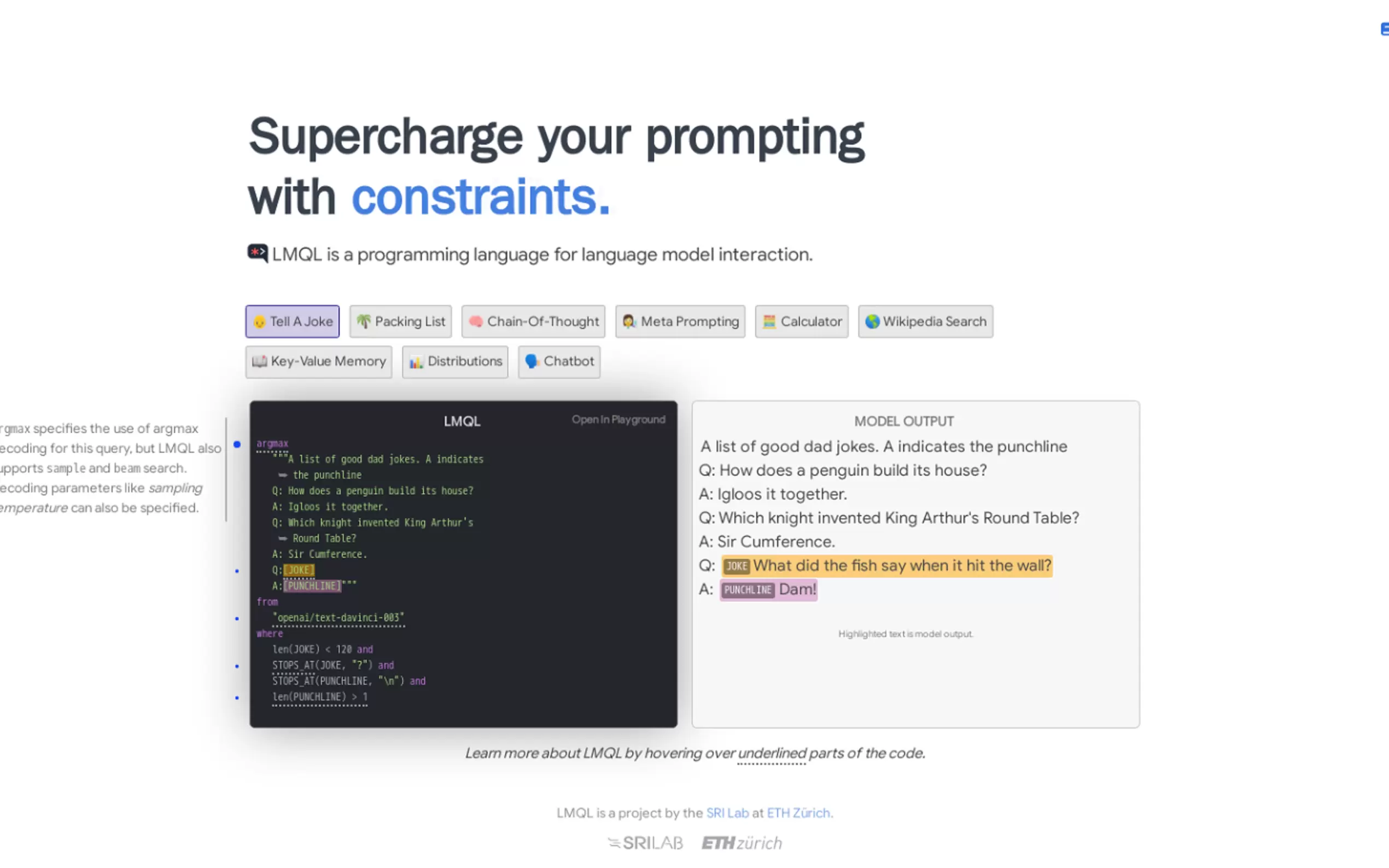
What is LMQL?
LMQL — язык запросов, специально разработанный для крупных языковых моделей (КЯМ) и сочетающий естественноязыковые подсказки с выразительностью Python. Он предоставляет такие функции, как ограничения, отладка, поиск и управление ходом выполнения, что облегчает взаимодействие с КЯМ.
Основные характеристики:
Ограничения: указывайте условия, которым должен соответствовать сгенерированный вывод, для удовлетворения особых критериев.
Отладка: анализируйте и понимайте, как КЯМ генерирует вывод, что помогает в точной настройке и обнаружении ошибок.
Поиск: доступ к готовым подсказкам для обычных задач, которые предоставляют удобную отправную точку.
Управление ходом выполнения: используйте операторы управления ходом выполнения Python, чтобы лучше контролировать процесс генерации.
Автоматическая генерация и проверка токенов: автоматическая генерация необходимых токенов и проверка полученной последовательности на основе указанных ограничений.
Поддержка произвольного кода Python: добавление динамических подсказок и обработка текста с помощью кода Python.
More information on LMQL
Top 5 Countries
72.28%
15.73%
7.01%
3.22%
1.76%
United States
India
Germany
Canada
Spain
Traffic Sources
8.35%
1.01%
0.06%
10.95%
34.99%
44.61%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
LMQL was manually vetted by our editorial team and was first featured on 2023-05-22.
Related Searches
LMQL Альтернативи
Больше Альтернативи-

LM Studio — это удобное настольное приложение для экспериментов с локальными и открытыми большими языковыми моделями (LLM). Кроссплатформенное настольное приложение LM Studio позволяет скачивать и запускать любую ggml-совместимую модель с Hugging Face, а также предоставляет простой, но мощный пользовательский интерфейс для настройки моделей и выполнения инференса. Приложение задействует ваш GPU по возможности.
-

-

-

-
