
What is Parsera ?
Parsera est une plateforme d'extraction de données web basée sur un LLM, conçue spécifiquement pour les développeurs qui nécessitent des données fiables et propres à grande échelle. Elle élimine la complexité et les coûts de maintenance liés au scraping traditionnel en transformant n'importe quel lien de site web en données structurées et prêtes à l'emploi grâce à des agents IA précis et auto-réparateurs. Avec Parsera, vous obtenez des résultats immédiats et précis, sans aucun codage manuel ni interruption, vous permettant de vous concentrer sur l'exploitation des données plutôt que sur la construction et la maintenance de l'infrastructure.
Fonctionnalités Clés
Parsera est conçue pour gérer la complexité du web moderne tout en fournissant des résultats propres et structurés avec un effort minimal.
🤖 Extraction IA Auto-Réparatrice
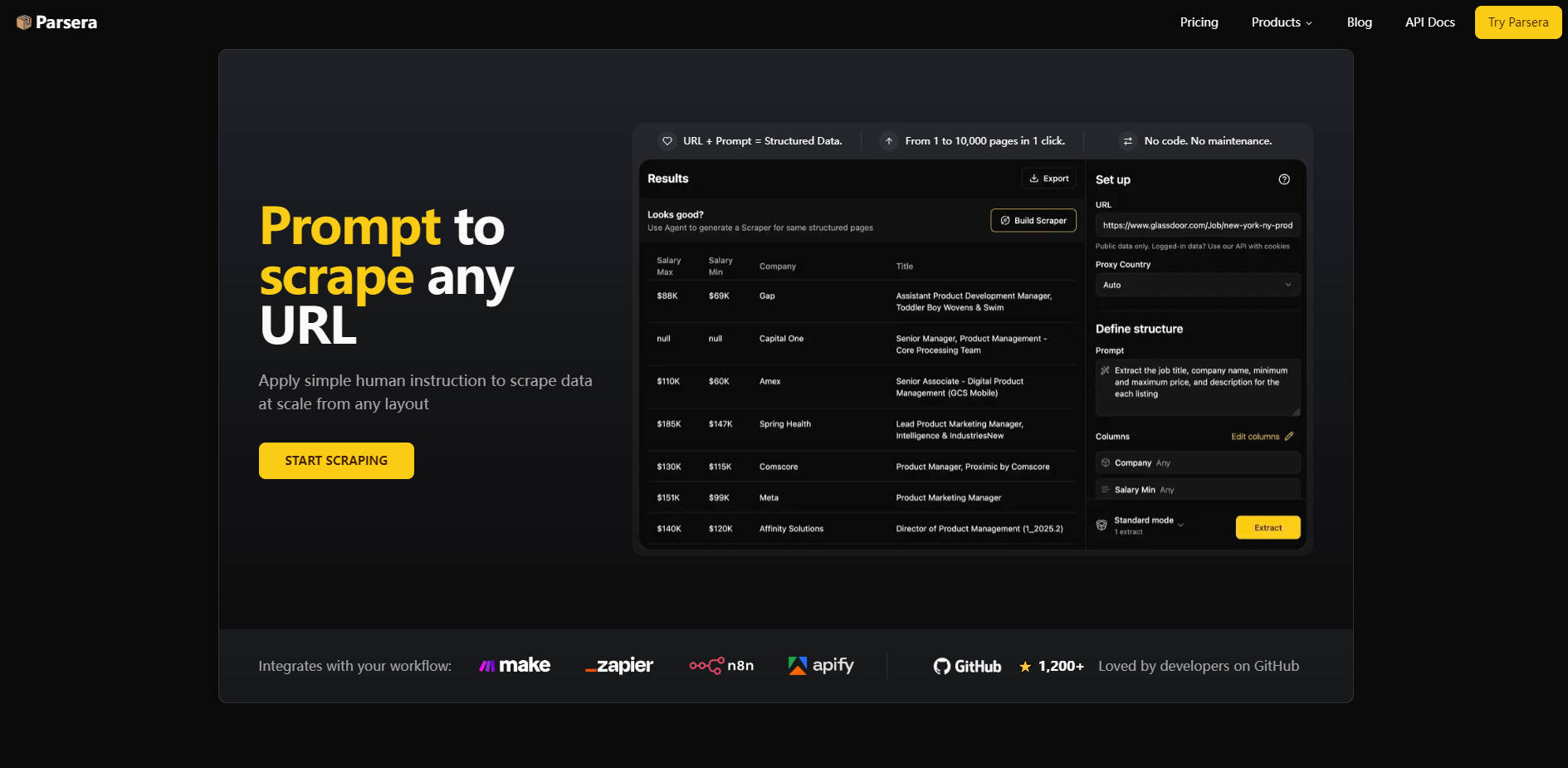
Exploitez des agents IA précis et auto-réparateurs pour fournir des données constamment propres, indépendamment des changements mineurs de mise en page des sites web. Contrairement aux sélecteurs manuels fragiles (XPath/CSS) qui se cassent fréquemment, l'Extracteur basé sur LLM de Parsera s'adapte dynamiquement à la structure de la page, assurant une grande fiabilité et réduisant le besoin de maintenance constante.
🚀 Passez à l'échelle avec les Scrapers Générés
Transformez toute extraction IA réussie (une URL + un Prompt en langage naturel) en un Scraper réutilisable et hautement efficace, en un seul clic. De manière cruciale, ces Scrapers Générés n'utilisent le LLM qu'une seule fois lors de la création initiale du code, réduisant drastiquement les coûts de traitement et permettant un scraping fiable et abordable de milliers de pages de structure identique.
⚙️ Automatisation Simplifiée en 3 Étapes
Lancez et déployez des extractions de données complexes en utilisant un flux de travail simple, proche de celui de l'humain. Décrivez les champs de données requis à l'aide d'instructions en langage naturel, Affinez le contexte spécifique pour la précision, et Automatisez le processus en générant un Scraper réutilisable. Ce processus réduit considérablement le temps entre le concept et la disponibilité des données prêtes pour la production.
🔗 Intégration Fluide au Flux de Travail
Intégrez Parsera directement dans vos pipelines de données existants grâce à un support API robuste. Nous proposons des connecteurs natifs avec des outils d'orchestration de flux de travail populaires, notamment Zapier, Make, n8n, et Apify, garantissant que les données extraites circulent instantanément là où vous en avez besoin pour l'analyse ou l'action.
🍪 Accès Authentifié aux Données
Accédez aux données protégées par des murs de connexion ou des paywalls. L'API de Parsera prend en charge l'utilisation de cookies, vous permettant d'extraire des informations critiques qui nécessitent une authentification utilisateur pour être visibles.
Cas d'Utilisation
Parsera aide les développeurs et les équipes de données à acquérir rapidement des données fiables pour des fonctions commerciales critiques, dépassant les processus manuels et les scripts fragiles.
Veille Concurrentielle E-commerce
Suivez automatiquement les listes de produits concurrents, y compris les prix en temps réel, la disponibilité et les spécifications détaillées sur des milliers de pages de produits uniques. Vous pouvez déployer rapidement des scrapers pré-générés (comme le Amazon Product Scraper) pour maintenir une veille de marché toujours actuelle et précise.
Génération de Leads Ciblés et Études de Marché
Constituez rapidement des listes de leads hautement ciblées et menez une analyse concurrentielle approfondie en collectant les coordonnées et les informations d'entreprise à partir de diverses sources web. Utilisez l'adaptabilité de l'Extracteur LLM pour scraper des données à partir d'URLs de structures différentes, assurant une couverture complète pour la prospection et l'évaluation du marché.
Analyse des Marchés Immobiliers et Financiers
Surveillez et analysez de grandes quantités de données structurées provenant d'annonces immobilières ou de sites d'information financière spécialisés. En extrayant uniquement les métriques pertinentes — telles que les prix historiques, les données de localisation ou les changements de politique — vous obtenez les informations nécessaires pour éclairer les décisions d'investissement et les prévisions de marché.
Avantages Uniques
Parsera se distingue en offrant une approche fondamentalement différente et conviviale pour les développeurs en matière d'extraction de données web, privilégiant l'efficacité, la fiabilité et la rentabilité à grande échelle.
Fiabilité grâce à l'IA Auto-Réparatrice
Les scrapers web traditionnels exigent un effort de codage et une maintenance constants à mesure que les sites web changent. L'avantage principal de Parsera réside dans son Extracteur basé sur un LLM, qui comprend le contexte et la mise en page de manière dynamique. Cette capacité d'auto-réparation signifie que vous ne subissez aucune interruption et aucune maintenance liée à la rupture des sélecteurs, garantissant que vos pipelines de données restent robustes.
Coûts Optimisés pour le Passage à l'Échelle
Parsera gère intelligemment les ressources de calcul en séparant l'étape de haute adaptabilité (Extracteur) de l'étape de haute échelle (Scrapers Générés).
Extracteur (Coût Plus Élevé) : Utilise le LLM pour chaque requête, idéal pour les tests, l'adaptation à de nouvelles structures ou la gestion d'URLs uniques et variées.
Scrapers Générés (Coût Inférieur) : N'utilisent le LLM qu'une seule fois pour la génération de code. Une fois construits, ces scrapers s'exécutent de manière fiable à une fraction du coût (1 crédit par scrape), rendant l'extraction massive et répétitive très économique.
Engagement envers un Scraping Éthique
Nous croyons en une extraction de données responsable. Parsera adhère strictement aux pratiques éthiques de scraping de sites web en respectant automatiquement les fichiers robots.txt des sites web cibles, vous aidant à maintenir la conformité et une bonne citoyenneté numérique.
Conclusion
Parsera offre aux développeurs une alternative puissante, évolutive et résiliente aux solutions de scraping manuel fragiles. En tirant parti d'agents IA avancés, vous pouvez concentrer vos ressources d'ingénierie sur l'utilisation de données propres plutôt que sur la maintenance du code d'extraction. Découvrez notre plateforme dès aujourd'hui et commencez à transformer sans effort des mises en page web complexes en données structurées.
More information on Parsera
Launched
2024-07
Pricing Model
Freemium
Starting Price
$29 / month
Global Rank
1355150
Follow
Month Visit
15.6K
Tech used
Top 5 Countries
27.25%
18.5%
11.6%
8.41%
4.89%
United States
India
Indonesia
Vietnam
Russia
Traffic Sources
4.99%
0.89%
0.09%
15.11%
35.61%
43.25%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Parsera was manually vetted by our editorial team and was first featured on 2025-10-31.
Parsera Alternatives
Plus Alternatives-

Scrapeless : La boîte à outils d'extraction de données web, optimisée par l'IA, pour une extraction sans tracas. Contournez les blocages, résolvez les CAPTCHA et évoluez sans effort.
-

Vous avez besoin de données web ? MrScraper utilise l'IA pour un web scraping facile et sans code. Extrayez des données propres de n'importe quel site, en contournant les blocages anti-bot grâce à de puissants proxies.
-

-

Cessez de lutter contre les bloqueurs de web scraping. L'API WebScraping.AI gère le JS, les proxys, les CAPTCHA et utilise l'IA pour une extraction et une analyse intelligentes des données.
-

Parse Extract : Extraction de données avancée et OCR pour les pipelines de LLM. Transformez des documents complexes et des données web en un texte épuré et optimisé pour les LLM. Rentable et sécurisé.