
What is Parsera ?
Parsera 是一個由 LLM 驅動的網路資料擷取平台,專為需要大規模、可靠且清晰資料的開發者而設計。它透過運用精確且能自我修復的 AI 代理,將任何網站連結轉換為結構化、立即可用的資料,從而消除了傳統網路爬蟲的複雜性和維護負擔。借助 Parsera,您無需手動編碼或擔心停機,即可立即獲得準確的結果,讓您能專注於資料應用,而非基礎設施的建置與維護。
主要特色
Parsera 旨在處理現代網路的複雜性,同時以最少的工作量提供清晰、結構化的輸出。
🤖 自我修復 AI 擷取
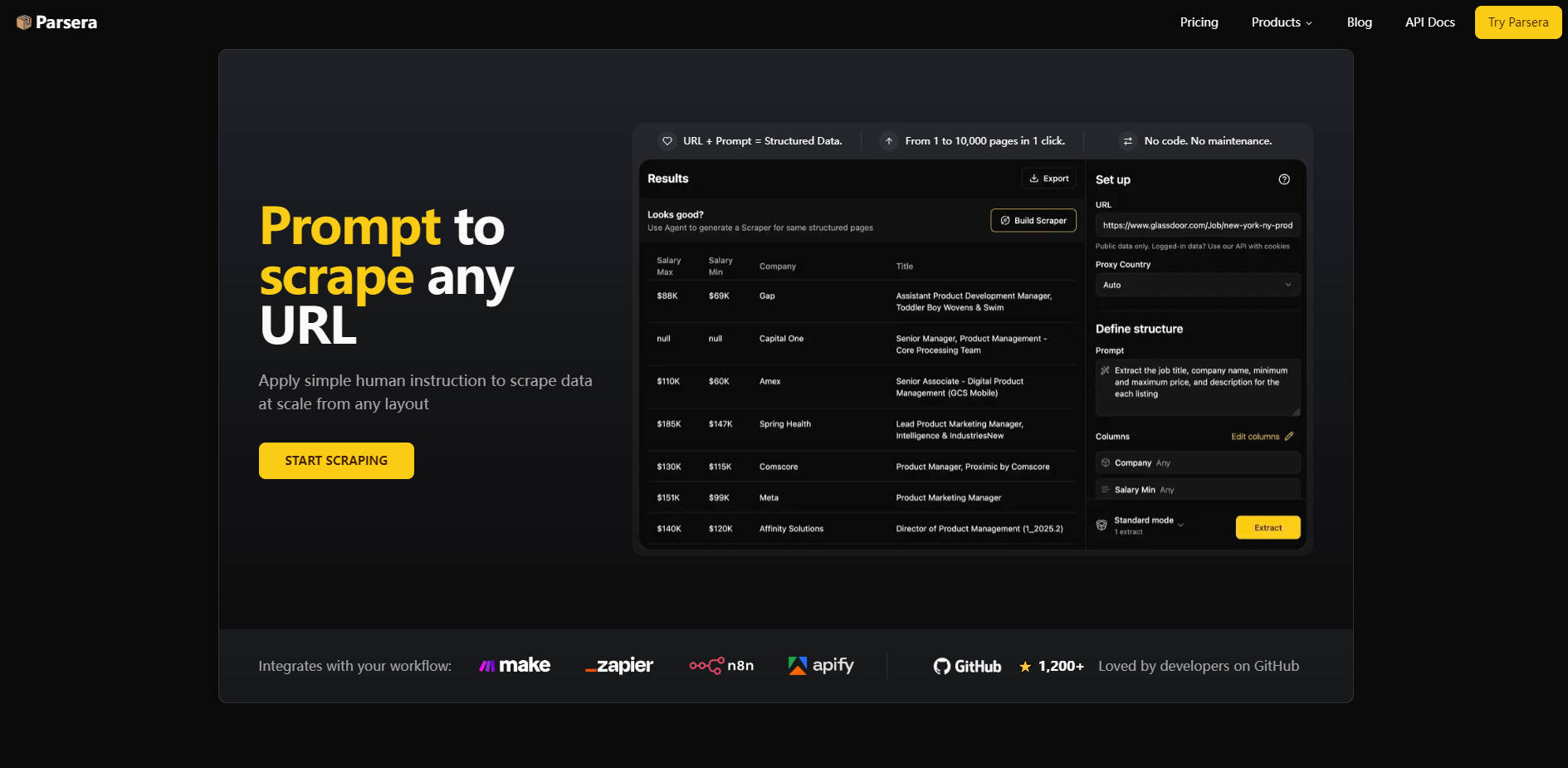
運用精確且能自我修復的 AI 代理,無論網站版面設計如何微幅變動,都能持續提供清晰的資料。不同於易於失效的手動選擇器 (XPath/CSS) ,Parsera 的 LLM 驅動擷取器能動態適應頁面結構,確保高度可靠性,並減少持續維護的需求。
🚀 透過生成式爬蟲實現規模化
透過單次點擊,將任何成功的 AI 擷取(一個網址 + 自然語言提示)轉換為可重複使用的高效率爬蟲。至關重要的是,這些 Generated Scrapers 僅在初始程式碼創建時使用一次 LLM,大幅降低了處理成本,並能以經濟實惠的方式可靠地爬取數千個結構相同的頁面。
⚙️ 流暢三步驟自動化
運用簡單、人性化的工作流程,啟動並部署複雜的資料擷取。透過自然語言指令來描述所需的資料欄位,優化特定上下文以確保準確性,然後藉由生成可重複使用的 Scraper 來自動化整個流程。這個流程大幅縮短了從概念到資料就緒的時間。
🔗 無縫工作流程整合
藉由強大的 API 支援,將 Parsera 直接整合到您現有的資料管線中。我們提供與流行工作流程協調工具的原生連接器,包括 Zapier, Make, n8n, and Apify,確保擷取的資料能即時流向您需要分析或採取行動的地方。
🍪 認證資料存取
存取需要登入或付費牆後的資料。Parsera 的 API 支援使用 Cookies,讓您能夠擷取需要使用者身份驗證才能顯示的關鍵資訊。
應用場景
Parsera 協助開發者和資料團隊,為關鍵業務功能迅速獲取可靠資料,擺脫手動流程和脆弱的腳本。
電子商務競爭情報
自動追蹤競爭對手的產品列表,包括數千個獨特產品頁面上的即時價格、庫存和詳細規格。您可以迅速部署預先生成的爬蟲(例如 Amazon Product Scraper),以維護始終最新且準確的市場情報。
目標客群開發與市場研究
透過從各種網路來源收集聯絡資訊和公司詳細資料,迅速建立高度目標化的潛在客戶名單,並進行深入的競爭對手分析。利用 LLM Extractor 的適應性,從不同結構的網址中爬取資料,確保潛在客戶開發和市場規模分析的全面覆蓋。
不動產與金融市場分析
監控並分析來自不動產列表或專業金融新聞網站的大量結構化資料。僅擷取相關指標——例如歷史價格、位置資料或政策變動——您就能獲得制定投資決策和市場預測所需的洞察。
獨特優勢
Parsera 透過提供一種根本不同、對開發者友善的網路資料擷取方法而脫穎而出,在大規模應用中優先考慮效率、可靠性和成本效益。
透過自我修復 AI 實現可靠性
傳統網路爬蟲隨著網站變更,需要不斷的編碼工作和維護。Parsera 的核心優勢在於其由 LLM 驅動的 Extractor,能夠動態理解上下文和版面配置。這種自我修復能力意味著您將體驗 零停機 和 零維護,不再受選擇器失效的困擾,確保您的資料管線保持強健。
規模化下的成本最佳化
Parsera 透過將高適應性階段 (Extractor) 與高規模階段 (Generated Scrapers) 分開,智慧地管理運算資源。
Extractor(成本較高): 每次請求都使用 LLM,非常適合測試、適應新結構或處理獨特、多樣化的網址。
Generated Scrapers(成本較低): 僅在程式碼生成時使用一次 LLM。一旦建立,這些爬蟲能以極低的成本(每次爬取 1 點數)可靠執行,使大規模、重複性的擷取變得非常經濟實惠。
致力於道德爬取
我們堅信負責任的資料擷取。Parsera 嚴格遵守道德的網站爬取實踐,自動尊重目標網站的 robots.txt 文件,協助您維持合規性並成為良好的數位公民。
結論
Parsera 為開發者提供了一個強大、可擴展且具有韌性的替代方案,取代了脆弱的手動爬取解決方案。透過利用先進的 AI 代理,您可以將工程資源集中於運用清晰的資料,而非維護擷取程式碼。立即探索我們的平台,輕鬆將複雜的網頁版面配置轉換為結構化資料。
More information on Parsera
Launched
2024-07
Pricing Model
Freemium
Starting Price
$29 / month
Global Rank
1355150
Follow
Month Visit
15.6K
Tech used
Top 5 Countries
27.25%
18.5%
11.6%
8.41%
4.89%
United States
India
Indonesia
Vietnam
Russia
Traffic Sources
4.99%
0.89%
0.09%
15.11%
35.61%
43.25%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Parsera was manually vetted by our editorial team and was first featured on 2025-10-31.
Parsera 替代方案
更多 替代方案-

-

您正在尋找網路資料嗎? MrScraper 運用 AI 技術,讓您輕鬆執行「無程式碼」網頁資料擷取。無論任何網站,都能擷取乾淨的資料,並透過強大的代理伺服器,輕鬆突破反爬蟲機制。
-

-

別再與網路爬蟲阻擋機制纏鬥了。WebScraping.AI API 能為您全權處理 JS、代理伺服器與驗證碼等問題,更運用 AI 進行智慧資料擷取與分析。
-

Parse Extract: 先進的資料萃取與光學字元辨識技術,專為大型語言模型(LLM)管線設計。能將繁雜的文件與網路數據,轉化為清晰易懂、可供LLM使用的文本。兼具成本效益與安全保障。