
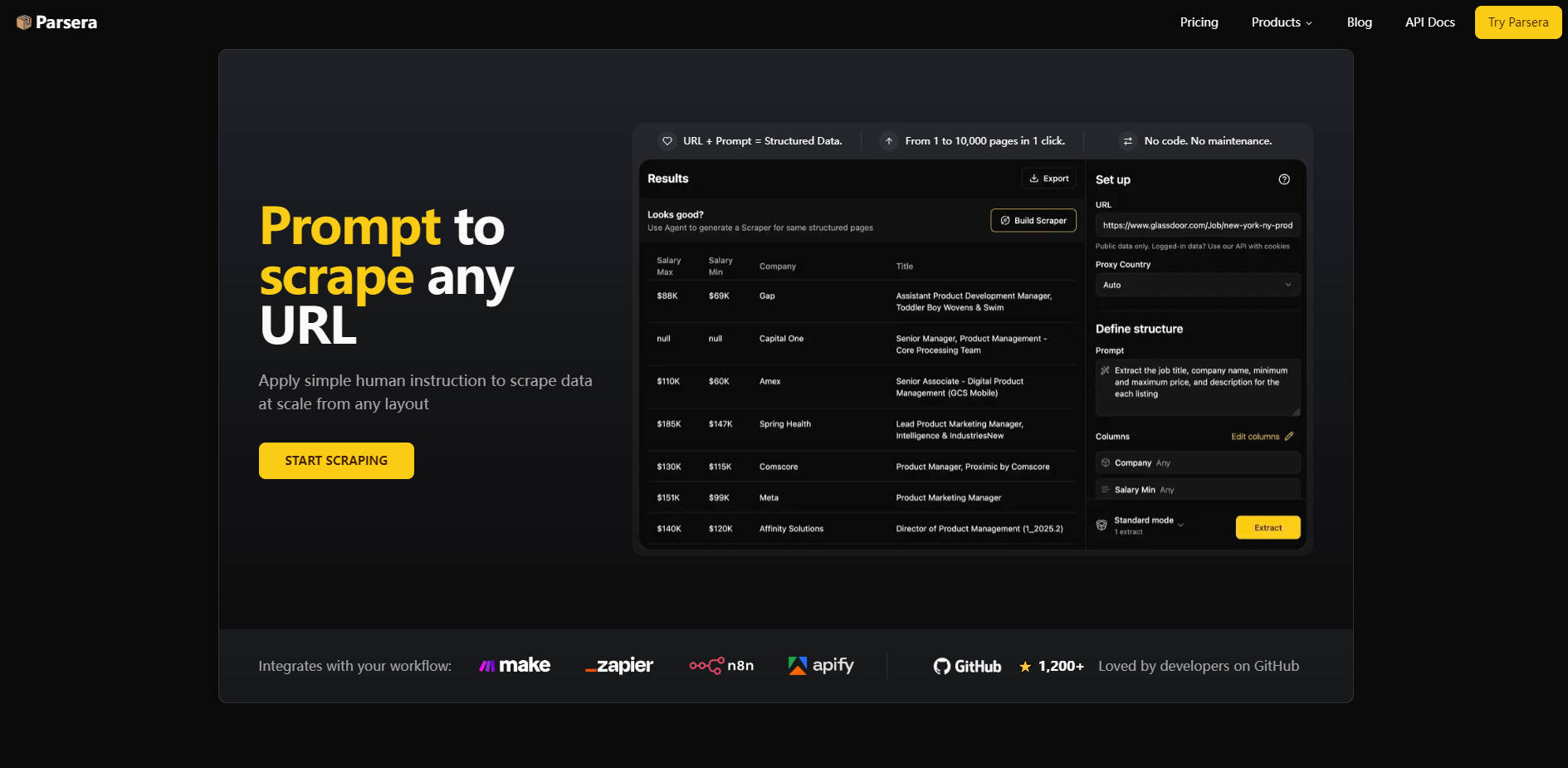
What is Parsera ?
Parsera 是一款由大型语言模型(LLM)驱动的网页数据提取平台,专为需要大规模可靠、干净数据的开发者而设计。它通过利用精准的自修复AI智能体,将任何网站链接转化为结构化、即用型数据,从而消除了传统数据抓取方式的复杂性和维护开销。借助 Parsera,您无需手动编写代码或担心停机,即可获得即时、准确的结果,让您能专注于数据利用,而非基础设施的构建和维护。
Key Features
Parsera 旨在应对现代网络的复杂性,同时以最少的投入提供干净、结构化的输出。
🤖 自修复AI提取
利用精准的自修复AI智能体,即使网站布局发生细微变化,也能持续提供干净的数据。与经常失效的脆弱手动选择器(XPath/CSS)不同,Parsera 基于 LLM 的提取器能够动态适应页面结构,从而确保高可靠性并减少持续维护的需求。
🚀 通过生成式爬虫实现规模化
只需轻轻一点,即可将任何成功的AI提取(一个URL + 自然语言 Prompt)转化为可复用、高效率的 Scraper。关键在于,这些生成式爬虫仅在初始代码创建阶段使用一次 LLM,从而大幅降低了处理成本,并能经济可靠地抓取数千个结构相同的页面。
⚙️ 精简三步自动化流程
采用简单、直观的工作流程,启动并部署复杂的数据提取任务。您只需使用自然语言指令描述所需数据字段,精炼特定上下文以提高准确性,并通过生成可复用的 Scraper 来自动化整个流程。这一流程大幅缩短了从概念到生成可用于生产数据的时间。
🔗 无缝工作流集成
借助强大的API支持,将 Parsera 直接集成到您现有的数据管道中。我们提供与流行工作流编排工具的本地连接器,包括 Zapier、Make、n8n 和 Apify,确保提取的数据能即时流向您需要进行分析或操作的地方。
🍪 认证数据访问
访问登录或付费墙后的数据。Parsera 的 API 支持使用 Cookie,使您能够提取需要用户认证才能显示的关键信息。
Use Cases
Parsera 助力开发者和数据团队快速获取关键业务功能所需的可靠数据,从而摆脱手动流程和脆弱脚本的束缚。
Competitive E-commerce Intelligence
自动跟踪竞争对手的产品列表,包括实时价格、库存情况和详细规格,覆盖数千个独特的商品页面。您可以快速部署预生成的爬虫(例如 Amazon Product Scraper),以确保市场情报始终保持最新和准确。
Targeted Lead Generation and Market Research
通过从各种网络源收集联系信息和公司详情,快速构建高度目标化的潜在客户列表,并进行深入的竞争对手分析。利用 LLM 提取器的适应性,从不同结构的 URL 中抓取数据,确保为客户开发和市场规模评估提供全面覆盖。
Real Estate and Financial Market Analysis
监控并分析来自房地产列表或专业金融新闻网站的大量结构化数据。通过仅提取相关指标——例如历史价格、位置数据或政策变化——您将获得做出投资决策和市场预测所需的洞察力。
Unique Advantages
Parsera 凭借其根本不同且对开发者友好的网页数据提取方法脱颖而出,优先考虑规模化效率、可靠性和成本效益。
Reliability Through Self-Repairing AI
随着网站变化,传统网页爬虫需要持续的编码工作和维护。Parsera 的核心优势在于其由 LLM 驱动的提取器,它能够动态理解上下文和布局。这种自修复能力意味着您不会因选择器失效而面临 停机或 零维护的困扰,从而确保您的数据管道保持健壮。
Optimized Cost for Scale
Parsera 通过将高适应性阶段(Extractor)与高规模化阶段(Generated Scrapers)分离,智能地管理计算资源。
提取器(高成本): 每次请求都使用 LLM,非常适合用于测试、适应新结构或处理独特、多样的 URL。
生成式爬虫(低成本): 仅在代码生成时使用一次 LLM。一旦构建完成,这些爬虫便能以极低的成本(每次抓取仅需1个点数)可靠运行,使大规模、重复性的数据提取变得高度经济。
Commitment to Ethical Scraping
我们坚信负责任的数据提取。Parsera 通过自动遵守目标网站的 robots.txt 文件,严格恪守道德网站抓取规范,帮助您维护合规性并成为优秀的数字公民。
Conclusion
Parsera 为开发者提供了一个强大、可扩展且具备韧性的替代方案,以取代脆弱的手动抓取解决方案。通过利用先进的AI智能体,您可以将工程资源集中于利用干净数据,而非维护提取代码。立即探索我们的平台,开始轻松地将复杂的网页布局转化为结构化数据。
More information on Parsera
Launched
2024-07
Pricing Model
Freemium
Starting Price
$29 / month
Global Rank
1355150
Follow
Month Visit
15.6K
Tech used
Top 5 Countries
27.25%
18.5%
11.6%
8.41%
4.89%
United States
India
Indonesia
Vietnam
Russia
Traffic Sources
4.99%
0.89%
0.09%
15.11%
35.61%
43.25%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Parsera was manually vetted by our editorial team and was first featured on 2025-10-31.
Parsera 替代方案
更多 替代方案-

-

需要网络数据吗?MrScraper融合AI技术,为您提供便捷的无代码网页抓取方案。无论何种网站,都能助您轻松提取纯净数据,并凭借强大的代理服务器,有效突破各类反爬虫限制。
-

-

-

Parse Extract:专为LLM管道打造的高级数据提取与OCR功能。将复杂的文档和网络数据转化为规整、可直接用于LLM的文本。成本效益高,安全可靠。