
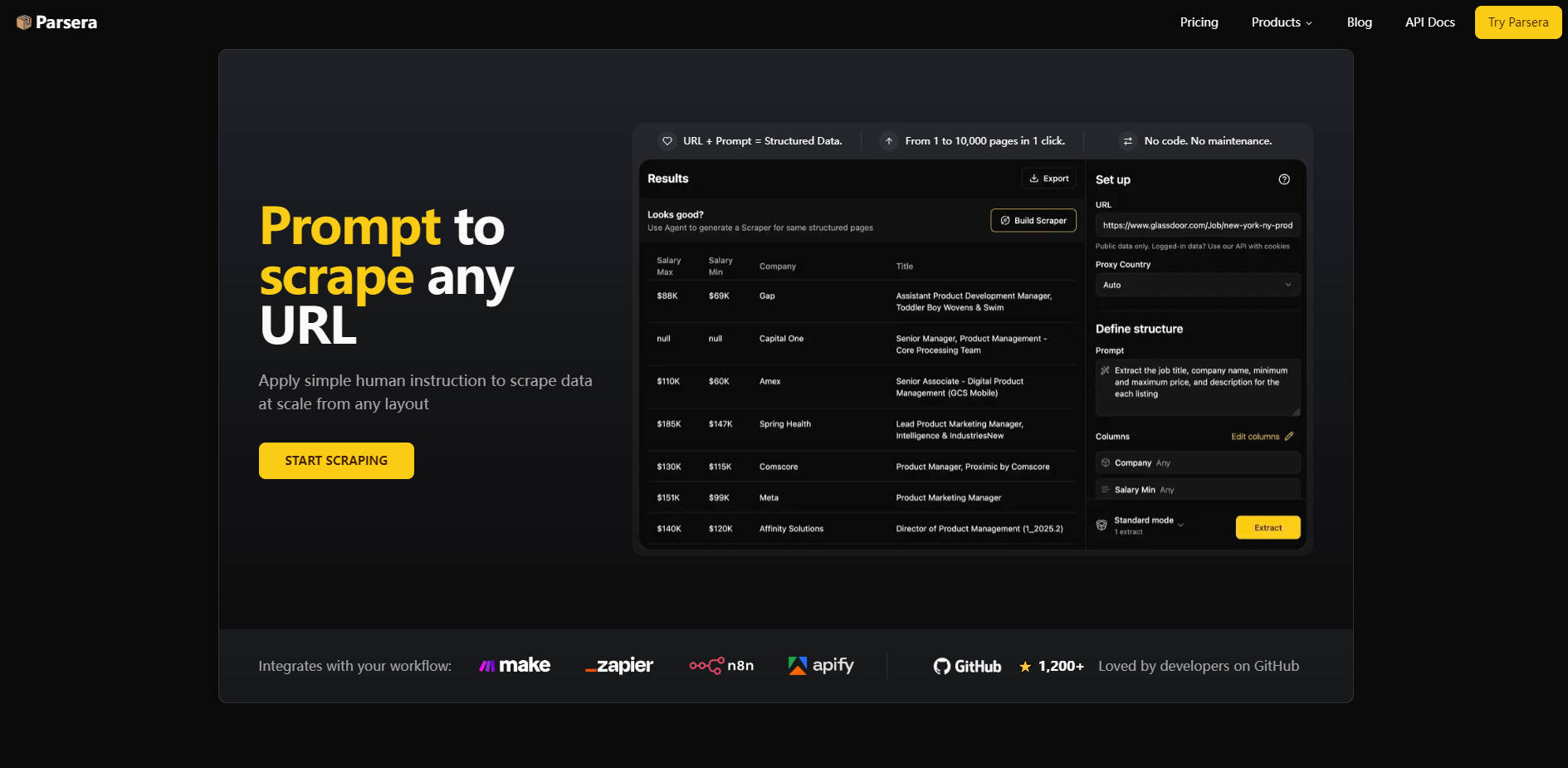
What is Parsera ?
Parseraは、大規模で信頼性の高いクリーンなデータを必要とする開発者向けに特化して設計された、LLMを活用したウェブデータ抽出プラットフォームです。従来のスクレイピングに伴う複雑さやメンテナンスの負担を解消し、精密な自己修復型AIエージェントを用いて、あらゆるウェブサイトのリンクを構造化されたすぐに使えるデータへと変換します。Parseraを導入することで、手作業によるコーディングやダウンタイムなしに、即座に正確な結果が得られるため、インフラの構築や維持ではなく、データの活用に専念できるようになります。
主な機能
Parseraは、現代のウェブが持つ複雑さに対処しつつ、最小限の労力でクリーンかつ構造化されたデータを出力できるように設計されています。
🤖 自己修復型AI抽出
精密な自己修復型AIエージェントを活用することで、ウェブサイトの軽微なレイアウト変更があっても、一貫してクリーンなデータを供給します。頻繁に機能不全に陥る脆弱な手動セレクター(XPath/CSS)とは異なり、ParseraのLLMベースのエクストラクターはページ構造に動的に適応するため、高い信頼性を確保し、継続的なメンテナンスの必要性を削減します。
🚀 生成型スクレイパーで規模を拡大
成功したAI抽出(URLと自然言語プロンプト)を、ワンクリックで再利用可能な高効率スクレイパーへと変換できます。重要なのは、これらの生成型スクレイパーは初期のコード作成時にのみLLMを使用するため、処理コストを劇的に削減し、同一構造の数千ページにわたる信頼性の高い、手頃な価格でのスクレイピングを実現することです。
⚙️ 合理化された3ステップの自動化
シンプルで人間のようなワークフローを用いることで、複雑なデータ抽出を簡単に開始・展開できます。自然言語の指示で必要なデータフィールドを記述し、精度を高めるために特定のコンテキストを調整し、再利用可能なスクレイパーを生成してプロセスを自動化します。この一連のプロセスにより、構想段階から実稼働可能なデータを得るまでの時間を劇的に短縮します。
🔗 シームレスなワークフロー統合
強力なAPIサポートを活用し、Parseraを既存のデータパイプラインに直接統合できます。Zapier, Make, n8n, Apifyといった人気のワークフローオーケストレーションツールとのネイティブコネクターも提供しており、抽出されたデータが必要な場所へ瞬時に流れ、分析やアクションに活用できます。
🍪 認証済みデータアクセス
ログインウォールやペイウォールの奥にあるデータにもアクセス可能です。ParseraのAPIはクッキーの使用をサポートしているため、ユーザー認証が必須となる重要な情報でも抽出できます。
ユースケース
Parseraは、開発者やデータチームが手作業のプロセスや脆弱なスクリプトから脱却し、重要なビジネス機能のために信頼性の高いデータを迅速に取得できるよう支援します。
競合ECインテリジェンス
リアルタイムの価格設定、在庫状況、詳細な仕様を含む競合他社の製品リストを、数千ものユニークな製品ページにわたって自動的に追跡します。Amazon Product Scraperのような事前に生成されたスクレイパーを迅速に展開することで、常に最新かつ正確な市場インテリジェンスを維持できます。
ターゲットリード生成と市場調査
さまざまなウェブソースから連絡先情報や企業詳細を収集することで、高度にターゲットを絞ったリードリストを迅速に構築し、詳細な競合分析を実施できます。LLM Extractorの適応性を活用し、異なる構造を持つURLからもデータをスクレイピングすることで、見込み客の特定や市場規模の把握に必要な包括的なカバレッジを確保します。
不動産・金融市場分析
不動産リストや専門的な金融ニュースサイトから、大量の構造化データを監視・分析します。過去の価格、位置情報、政策変更といった関連性の高い指標のみを抽出することで、投資判断や市場予測に必要な深い洞察を得ることが可能です。
独自の利点
Parseraは、ウェブデータ抽出において、効率性、信頼性、そして大規模な費用対効果を最優先する、根本的に異なる開発者フレンドリーなアプローチを提供することで他社との差別化を図っています。
自己修復型AIによる信頼性
従来のウェブスクレイパーは、ウェブサイトの変更に応じて絶えずコーディング作業とメンテナンスを必要とします。Parseraの核となる利点は、コンテキストとレイアウトを動的に理解するLLM搭載エクストラクターにあります。この自己修復機能により、セレクターの破損に伴うダウンタイムゼロとメンテナンス不要を実現し、データパイプラインの堅牢性を保証します。
大規模運用におけるコスト最適化
Parseraは、高い適応性を要するステージ(Extractor)と、大規模処理を行うステージ(Generated Scrapers)を分離することで、コンピューティングリソースをインテリジェントに管理します。
エクストラクター(高コスト): すべてのリクエストにLLMを使用します。テスト、新しい構造への適応、またはユニークで多様なURLの処理に最適です。
生成型スクレイパー(低コスト): コード生成時のみLLMを一度使用します。一度構築されると、これらのスクレイパーはごく一部のコスト(1スクレイプあたり1クレジット)で確実に実行され、大量の反復抽出を非常に経済的にします。
倫理的なスクレイピングへのコミットメント
私たちは責任あるデータ抽出を重視しています。Parseraは、ターゲットウェブサイトのrobots.txtファイルを自動的に尊重することで、倫理的なウェブサイトスクレイピングの慣行を厳守します。これにより、お客様がコンプライアンスを維持し、良きデジタル市民としての役割を果たすことを支援します。
結論
Parseraは、脆弱な手動スクレイピングソリューションに代わる、強力でスケーラブルかつ回復力のある選択肢を開発者に提供します。高度なAIエージェントを活用することで、抽出コードのメンテナンスに煩わされることなく、クリーンなデータの活用にエンジニアリングリソースを集中させることが可能です。今すぐ当社のプラットフォームを体験し、複雑なウェブレイアウトを構造化されたデータへと簡単に変換し始めましょう。
More information on Parsera
Launched
2024-07
Pricing Model
Freemium
Starting Price
$29 / month
Global Rank
1355150
Follow
Month Visit
15.6K
Tech used
Top 5 Countries
27.25%
18.5%
11.6%
8.41%
4.89%
United States
India
Indonesia
Vietnam
Russia
Traffic Sources
4.99%
0.89%
0.09%
15.11%
35.61%
43.25%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Parsera was manually vetted by our editorial team and was first featured on 2025-10-31.
Parsera 代替ソフト
もっと見る 代替ソフト-

Scrapeless:AI搭載のウェブスクレイピングツールキット。手間のかからないデータ抽出を実現します。ブロックを回避し、CAPTCHAを解決し、簡単にスケーリングできます。
-

ウェブデータの収集でお困りではありませんか? MrScraperはAIを活用し、ノーコードで手軽にウェブスクレイピングを実現します。 強力なプロキシでアンチボットのブロックを回避しながら、あらゆるサイトからクリーンなデータを抽出可能です。
-

-

ウェブスクレイピングのブロックとの格闘はもうやめましょう。 WebScraping.AI APIは、JavaScript、プロキシ、CAPTCHAの処理に加え、AIを活用してスマートなデータ抽出と分析を可能にします。
-

Parse Extract: LLMパイプライン向けの高度なデータ抽出とOCR。 複雑なドキュメントやウェブデータを、クリーンでLLMに最適なテキストへと変換します。 費用対効果に優れ、高いセキュリティを実現します。