
What is Future X?
대규모 언어 모델(LLM)은 복잡한 계획 수립과 실제 세계 상호작용이 가능한 자율 에이전트로 빠르게 진화하고 있습니다. 하지만 이들의 진정한 핵심 지능, 특히 미지의 미래 사건을 예측하는 능력을 정확하게 평가하는 것은 상당한 난제였습니다. FutureX는 정적이고 쉽게 오염될 수 있는 벤치마크의 한계를 넘어, 진정으로 새롭고 불확실한 환경에서 에이전트의 역량을 시험하도록 설계된 동적 실시간 벤치마크를 제공함으로써 이러한 문제에 답합니다.
핵심 기능
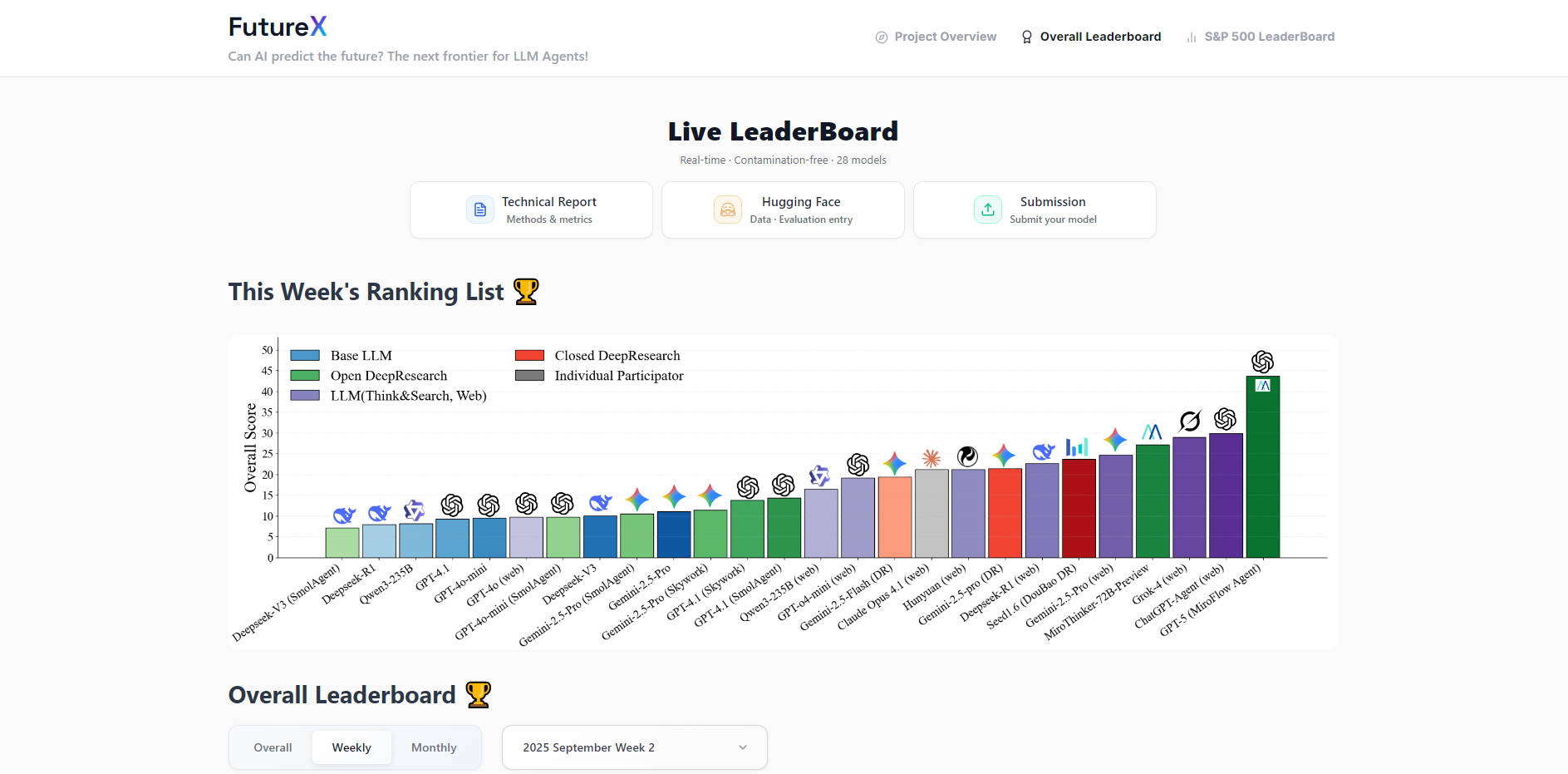
🛡️ 데이터 오염 방지: FutureX는 미래 사건에 대한 예측을 요구함으로써 평가의 무결성을 보장합니다. 이러한 중요한 설계는 에이전트의 훈련 데이터 내에 답이 존재할 수 없음을 의미하며, 매주 약 500개의 새로운 이벤트를 통해 진정한 예측 능력을 오염되지 않은 상태로 공정하게 평가할 수 있도록 합니다.
🌎 실제 세계 난제: 시뮬레이션 환경과 달리, FutureX는 에이전트가 실시간 실제 정보를 분석하여 실제 미래 사건을 예측하도록 합니다. 이 접근 방식은 에이전트가 역동적이고 불확실한 조건에서 정보를 수집하고, 트렌드를 분석하며, 의사결정을 내리도록 유도하여 인간 전문가 분석의 복잡성을 그대로 반영합니다.
📚 광범위한 데이터 출처: 풍부하고 다양한 정보 환경을 제공하기 위해 FutureX는 여러 도메인의 2,000개 이상의 웹사이트에서 엄선된 195개의 고품질 실시간 소스로부터 데이터를 통합합니다. 이러한 정보의 폭은 강력한 트렌드 분석과 정보에 기반한 예측에 매우 중요합니다.
⚙️ 완전 자동화된 파이프라인: FutureX는 폐쇄 루프형 자동화 평가 시스템으로 작동합니다. 매일 새로운 질문을 자율적으로 수집하고, 최대 27개의 다양한 에이전트를 실행하여 예측을 수행하며, 이벤트가 종료되면 자동으로 결과를 검색하고 점수를 매깁니다. 이러한 자동화는 지속적이고 확장 가능하며 편향되지 않은 평가를 보장합니다.
📊 세분화된 난이도 단계: 에이전트의 역량을 정밀하게 측정하기 위해 FutureX는 예측 작업을 네 가지 상승하는 난이도 수준으로 분류합니다. 몇 가지 선택지만 필요한 기본 작업부터 변동성이 크고 개방형인 예측에 이르기까지, 이러한 난이도 단계는 연구자들이 계획, 추론 및 정보 검색의 다양한 요구 사항에 따른 에이전트의 성능을 이해할 수 있도록 돕습니다.
활용 사례
새로운 에이전트 아키텍처 벤치마킹: 연구자와 개발자는 동적이고 실제적인 표준에 대해 새로운 LLM 에이전트 설계를 엄격하게 테스트하여, 진정한 선견지명과 적응성이 요구되는 작업에서의 성능에 대한 명확한 통찰력을 얻을 수 있습니다.
동적 환경에서 에이전트 성능 검증: 팀은 FutureX를 사용하여 정적 지식으로는 불충분한 시나리오에서 변화하는 정보를 처리하고, 불확실성 속에서 의사결정을 내리며, 결과를 예측하는 에이전트의 능력을 검증하여 견고한 실제 배포를 보장할 수 있습니다.
차세대 AI 개발 촉진: 도전적이고 공정한 평가 플랫폼을 제공함으로써 FutureX는 복잡하고 위험 부담이 큰 영역에서 정교한 분석 및 예측 능력이 요구되는, 인간 전문가 수준에 근접하거나 심지어 능가할 수 있는 AI 에이전트 개발을 고취하고 안내합니다.
차별화된 강점
FutureX는 진정한 AI 지능 평가를 저해하는 핵심적인 한계점을 직접적으로 다룸으로써 기존 벤치마크와 차별화됩니다.
오염되지 않은 동적 평가: 질문과 답이 훈련 데이터에 흡수될 수 있는 정적 벤치마크와 달리, FutureX는 미래 사건에 중점을 두어 본질적으로 데이터 오염을 방지합니다. 이는 에이전트의 성능이 단순히 암기된 정보가 아닌, 진정한 추론 능력과 예측력을 반영하도록 보장합니다.
"미지의 미래" 예측의 진정한 시험: FutureX는 AI에게 이미 알려진 문제를 해결하도록 요구하는 것에서 벗어나, 진정으로 미지의 결과에 도전하게 함으로써 패러다임을 전환합니다. 이는 에이전트가 실시간 정보를 적극적으로 수집하고 종합하며, 트렌드를 분석하고, 동적 환경에서 의사결정을 내림으로써 인간 전문가를 모방하도록 요구하며, 이는 우리가 AI에서 추구하는 궁극적인 능력입니다.
에이전트 지능에 대한 세분화된 통찰: 세심하게 설계된 네 가지 난이도 단계를 통해 FutureX는 에이전트 역량 평가에 있어 비할 데 없는 세분화를 제공합니다. 이는 단순한 회상 능력에 뛰어난 모델과 심층적인 불확실성 속에서 고급 계획, 상호작용 검색 및 강력한 추론을 보여주는 모델을 효과적으로 구별하여, 개선을 위한 명확한 로드맵을 제시합니다.
연구 개발 가속화: 지속적으로 업데이트되고 자동화되며 도전적인 플랫폼을 제공함으로써 FutureX는 학술 및 산업 연구 모두에 강력한 촉매 역할을 합니다. 이는 현재의 한계를 부각하고 차세대 AI 에이전트가 발전해야 할 특정 영역을 제시함으로써 혁신을 촉진합니다.
결론
FutureX는 실제적이고 불확실한 환경에서 LLM 에이전트의 예측 능력을 평가하기 위한 필수적이고 동적인 벤치마크를 제공합니다. 오염되지 않은 실시간 평가를 세분화된 난이도 단계별로 제공함으로써, 이는 인간 전문가 수준에 필적하는 AI 에이전트 개발을 촉진하는 데 필요한 중요한 통찰력을 제공합니다. FutureX가 AI 지능의 경계를 확장하는 데 어떻게 도움이 될 수 있는지 알아보십시오.
More information on Future X
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Future X was manually vetted by our editorial team and was first featured on 2025-09-24.
Future X 대체품
더보기 대체품-

신뢰하기 어려운 생성형 AI 때문에 어려움을 겪고 계십니까? Future AGI는 평가, 최적화는 물론 실시간 안전까지 책임지는 완벽한 엔드투엔드 플랫폼입니다. 더욱 신뢰할 수 있는 AI를 신속하게 구축하십시오.
-

-

Agent Leaderboard를 통해 귀사의 요구사항에 가장 적합한 AI 에이전트를 선택하십시오. 14개의 벤치마크 전반에 걸쳐 편향 없는 실제 성능 통찰력을 제공합니다.
-

-
