
What is NuExtract?
NuExtract is a specialized family of Large Language Models (LLMs) engineered specifically for high-accuracy, structured information extraction from documents. It directly addresses the costly, manual challenge of processing unstructured and semi-structured data by automating the classification, summarization, and capture of complex entities and relationships from documents at scale. Designed for companies across all industries, NuExtract delivers the reliability needed to automate critical data-entry and decision-making workflows.
Key Features
NuExtract combines advanced AI architecture with robust data handling to ensure precise and actionable output from complex source materials.
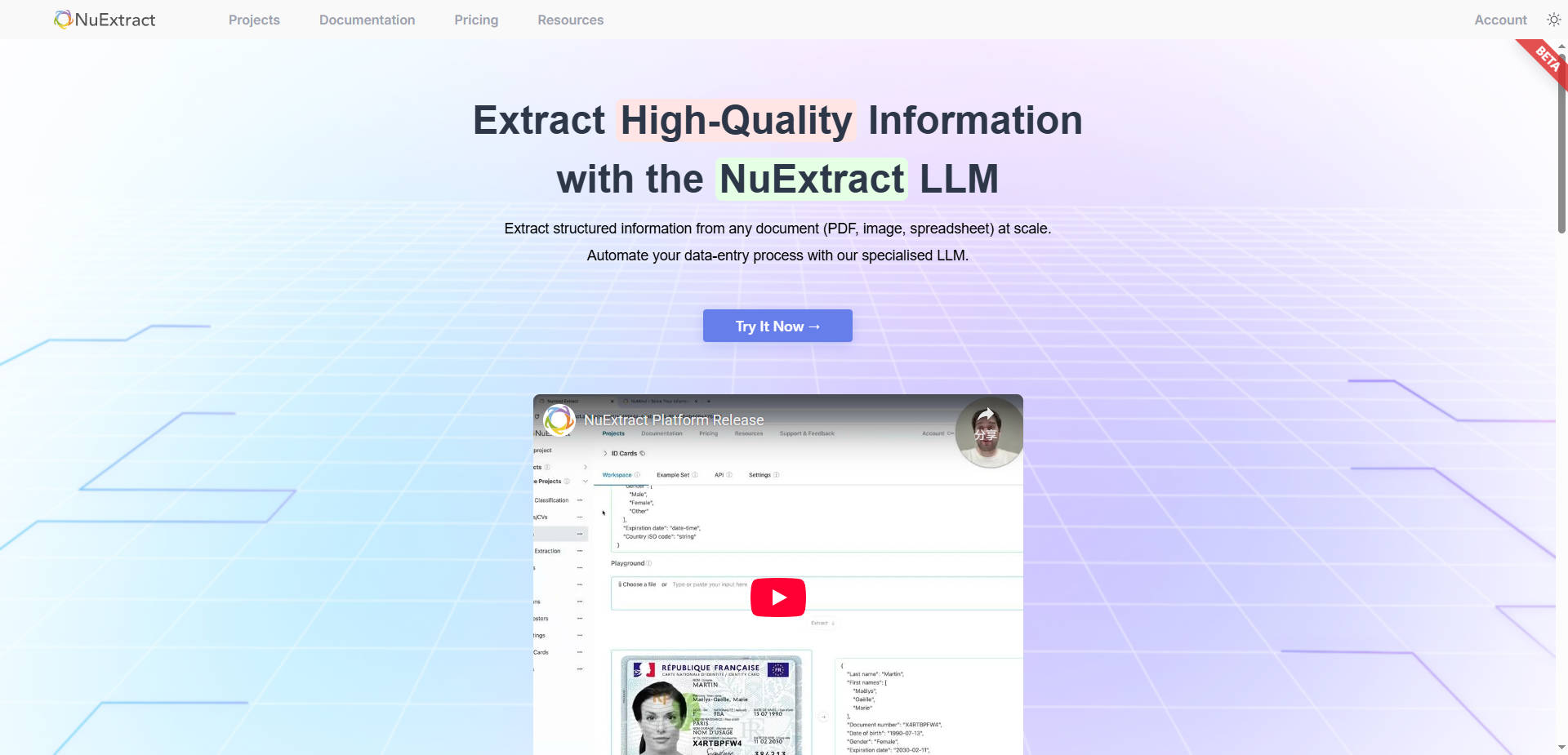
📄 Multimodal and Versatile Document Processing NuExtract processes virtually any document type, including raw text, scanned images, and formatted files such as PDFs, spreadsheets, and PowerPoints. To ensure fidelity, formatted documents are converted to images internally, retaining crucial spatial information necessary for accurately parsing tables, headers, and layout-dependent data points.
⚙️ Template-Driven Structured Output You define exactly what information to extract using a customizable template, which dictates the required entities, relationships, and output structure. The extracted information is always returned in a reliable JSON format, and when utilized through the NuExtract platform, programmatic verification guarantees the output strictly adheres to the defined template.
🛡️ Specialized Training for Low Hallucination Unlike generic LLMs, NuExtract is specifically trained for information extraction, resulting in superior reliability. Crucially, the model is designed to recognize uncertainty and explicitly return a "null value" or "I don't know" when information is genuinely absent from the document, drastically minimizing the risk of fabricating (hallucinating) data.
⚡ Rapid Performance Improvement via Examples Achieve production-ready accuracy faster by providing customized examples. Extraction performance can be substantially improved by supplying even a single input-output example of a correct extraction, allowing you to quickly adapt the model to the nuances of your specific document types and data requirements.
Use Cases
NuExtract enables organizations to transform complex, document-driven processes into fully automated workflows, reducing operational costs and accelerating decision-making.
Database Filling and Entity Extraction
Automate the tedious process of populating internal databases. Use NuExtract to parse high volumes of documents—such as commercial contracts, invoices, or maintenance reports—to extract specific entities (e.g., item prices, quantities, clause terms, dates) and relationships, ensuring structured data is immediately ready for storage and analysis without manual input.
Regulatory Compliance and Identity Verification (KYC/KYB)
In regulated industries like Banking and Finance, NuExtract rapidly processes identity documents, financial statements, and complex forms. It can extract and verify specific information from scanned ID cards or financial reports, drastically accelerating Identity Verification (KYC/KYB) processes while maintaining strict data integrity and audit trails.
Enterprise Document Triage and Classification
Streamline internal operations by automatically classifying incoming documents, such as customer emails, legal filings, or insurance claims. NuExtract can immediately categorize documents based on their content and intent, ensuring they are routed to the correct department or trigger the appropriate automatic action, significantly improving response times and operational efficiency.
Unique Advantages
NuExtract is not a general-purpose LLM; it is a specialized tool built for extraction reliability and performance, offering distinct advantages over generic solutions.
Superior Extraction Performance: NuExtract consistently outperforms frontier LLMs in information extraction benchmarks. Our specialized training ensures a deeper, more reliable understanding of document structure and content.
Proven Reliability: The NuExtract 2.0 PRO model has been shown to outperform GPT-4.1 by over 9 F-Score points on extraction benchmarks covering both text and image documents, demonstrating a verifiable lead in precision and recall.
Guaranteed Structure Adherence: Through the NuExtract platform, the output structure is programmatically verified and corrected against your template, ensuring that the JSON you receive is always usable for downstream systems—a critical reliability feature often missing in general-purpose models.
Conclusion
NuExtract delivers the specialized intelligence and robust reliability required for high-stakes document automation. By focusing exclusively on structured extraction and offering verifiable performance advantages, we empower your organization to unlock critical data trapped within documents at scale.
More information on NuExtract
Launched
2025-01
Pricing Model
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Top 5 Countries
100%
India
Traffic Sources
100%
direct
Source: Similarweb (Oct 29, 2025)
NuExtract was manually vetted by our editorial team and was first featured on 2025-10-29.
NuExtract Alternatives
Load more Alternatives-

LangExtract: Python library for verifiable LLM data extraction. Turn unstructured text into precise, source-grounded, structured data you can trust.
-

-

Parse Extract: Advanced data extraction & OCR for LLM pipelines. Transform complex documents & web data into clean, LLM-ready text. Cost-efficient & secure.
-

Extractor API: Get clean, structured data from any webpage, PDF, or news with AI. Automate complex web scraping & leverage LLMs for deep insights.
-

DocExtractor uses AI to extract data from unstructured documents accurately and quickly, saving time, minimizing errors, and enabling data-driven decisions. It processes various formats, integrates easily, and has multiple use cases in different industries.