Click outside to close
What is Influxdata?
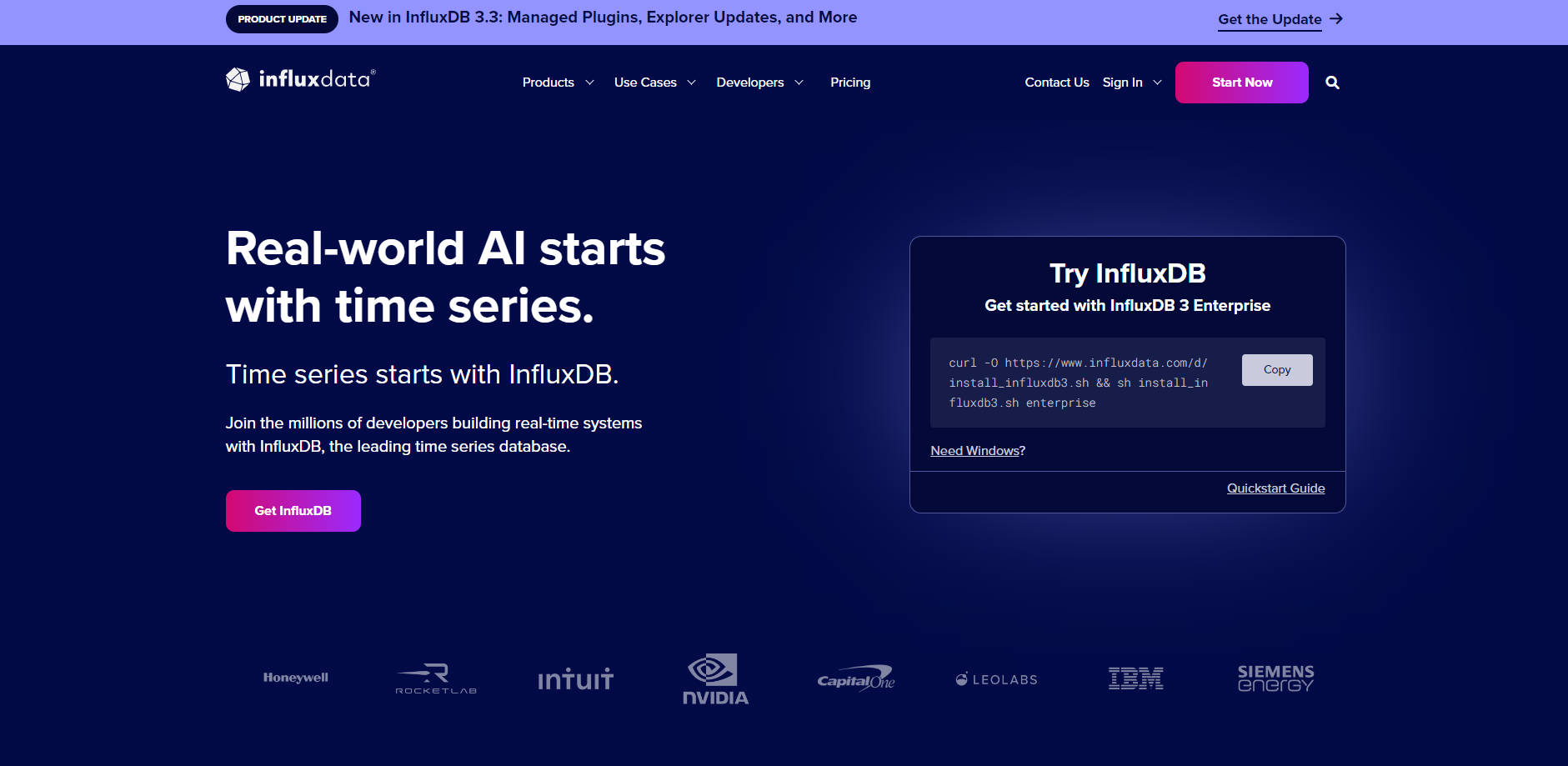
InfluxDB — это специализированная платформа для временных рядов данных, разработанная для разработчиков и организаций, которым необходимо управлять огромными объемами данных с временными метками с исключительной производительностью. Она напрямую решает задачу приема, хранения и анализа высокоскоростных данных из таких источников, как IoT-устройства, приложения и инфраструктура, без ущерба для скорости или эффективности. Будь то создание AI-моделей реального времени или мониторинг критически важных систем, InfluxDB предоставляет специализированный движок, необходимый для успеха в любом масштабе.
Ключевые особенности
🚀 Высокоскоростной, безлимитный прием данных: Принимайте миллионы точек данных временных рядов в секунду без снижения производительности или искусственных ограничений. InfluxDB спроектирована для работы с высококардинальными и высокоскоростными потоками данных, обеспечивая, что ваша система сможет справляться даже с самыми требовательными нагрузками.
🗃️ Значительное снижение затрат на хранение: Сократите объем занимаемого данными дискового пространства до 90%. InfluxDB использует высокоэффективный колоночный формат Parquet и лучшую в своем классе компрессию, что позволяет дольше хранить данные высокого разрешения за небольшую часть стоимости традиционных решений.
📊 Аналитика в реальном времени с SQL: Преобразуйте и анализируйте неограниченные ряды данных в реальном времени, используя уже знакомые вам инструменты и языки. С полной поддержкой SQL вы можете выполнять сложные аналитические запросы и получать мгновенные инсайты без крутой кривой обучения.
🌐 Развертывание где угодно, интеграция со всем: Запускайте InfluxDB там, где это удобно для вас — в облаке, локально или на периферии. Благодаря огромной экосистеме из более чем 300 плагинов Telegraf, обширным клиентским библиотекам (Python, Go, JavaScript и другие), а также бесшовной интеграции с Lakehouse, она легко вписывается в ваш существующий технологический стек.
Варианты использования
Предиктивное обслуживание: Отслеживайте состояние и режимы использования промышленного оборудования в реальном времени. Анализируя данные датчиков высокого разрешения, вы можете прогнозировать потенциальные сбои и заблаговременно планировать обслуживание, предотвращая дорогостоящие простои до их возникновения.
Обнаружение аномалий в реальном времени: Находите и реагируйте на проблемы в момент их возникновения. InfluxDB позволяет запрашивать потоковые данные для выявления аномалий в производительности приложений, сетевом трафике или финансовых транзакциях, мгновенно запуская автоматические оповещения и ответные действия.
Автономные системы и ИИ: Обеспечьте ваши модели ИИ и машинного обучения точными данными высокого разрешения, которые им требуются. InfluxDB фиксирует подробный исторический контекст, необходимый для вывода причинно-следственных связей, позволяя системам постоянно обучаться, адаптироваться и оптимизировать себя.
Почему стоит выбрать InfluxDB?
InfluxDB — это не просто очередная база данных; это движок, построенный на современном, открытом стеке данных, разработанный специально для решения задач, связанных с данными временных рядов. Эта архитектурная основа обеспечивает явные и измеримые преимущества.
1. Превосходная техническая основа (стек FDAP) InfluxDB 3 разработан на Rust и использует набор мощных технологий, поддерживаемых Apache, для обеспечения своей производительности и интероперабельности:
Apache Arrow: Предоставляет стандартизированный, высокопроизводительный колоночный формат в оперативной памяти для молниеносной аналитики.
Apache Parquet: Обеспечивает высокоэффективное, сжатое колоночное хранение, что является ключом к его огромной экономии затрат.
Apache DataFusion: Высокопроизводительный движок запросов, который позволяет выполнять мощные SQL-запросы в реальном времени к вашим данным.
Arrow Flight: Оптимизированный протокол передачи данных для эффективного перемещения больших наборов данных между процессами и системами.
2. Интеллектуальная, экономически эффективная архитектура Разделяя вычисления и хранение, InfluxDB позволяет независимо и экономично масштабировать оба ресурса. Активные данные остаются доступными для высокоскоростных запросов, в то время как более старые исторические данные автоматически вытесняются и передаются в объектное хранилище или напрямую интегрируются с озерами данных и хранилищами, оптимизируя затраты без ущерба для доступа.
3. Крупнейшая экосистема разработчиков временных рядов Имея более миллиона активных инстансов с открытым исходным кодом, миллиарды загрузок Docker и тысячи участников сообщества, InfluxDB является самой надежной и широко используемой базой данных временных рядов. Это активное сообщество обеспечивает надежную поддержку, богатую экосистему интеграций и постоянные инновации.
Заключение
InfluxDB — это оптимальная платформа для разработчиков, которым требуется надежное, масштабируемое и эффективное решение для данных временных рядов. Сочетая исключительную производительность с гибкой, открытой архитектурой, она дает вам возможность создавать следующее поколение систем мониторинга, аналитики и ИИ-управляемых систем в реальном времени.
Узнайте, как InfluxDB может стать движком для вашего конвейера данных в реальном времени.
Часто задаваемые вопросы (FAQ)
1. Чем InfluxDB отличается от стандартной SQL-базы данных, такой как PostgreSQL? В то время как стандартные SQL-базы данных могут хранить данные с временными метками, они не оптимизированы для этого. InfluxDB — это специализированная колоночная база данных, разработанная для конкретной рабочей нагрузки временных рядов данных: чрезвычайно высокоскоростной прием, эффективное долгосрочное хранение за счет сжатия и быстрые аналитические запросы по временным диапазонам. Эта специализация приводит к значительно лучшей производительности и более низким затратам в масштабе.
2. Каковы варианты развертывания InfluxDB? InfluxDB предлагает полную гибкость. Вы можете запускать ее как полностью управляемый бессерверный или выделенный сервис в облаке (InfluxDB Cloud), развернуть ее на собственной инфраструктуре для полного контроля (InfluxDB Enterprise или InfluxDB Clustered), или начать с версии с открытым исходным кодом (InfluxDB 3 Core) для одноузловых развертываний.
3. Как InfluxDB интегрируется с озерами данных или BI-инструментами? InfluxDB разработан для интероперабельности. Он использует открытые стандарты данных, такие как Apache Parquet и Iceberg, что обеспечивает передачу данных без копирования и без ETL с основными озерами данных, хранилищами и BI-платформами. Это означает, что вы можете запрашивать свои данные временных рядов непосредственно из других систем без сложного и дорогостоящего перемещения данных.
More information on Influxdata
Top 5 Countries
16.1%
13.65%
5.41%
3.31%
3.14%
United States
Germany
United Kingdom
Russia
Vietnam
Traffic Sources
1.92%
1.39%
0.1%
6.33%
55.71%
34.56%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Influxdata was manually vetted by our editorial team and was first featured on 2025-08-21.
Related Searches