What is Neuronpedia?
理解複雜 AI 模型內部的運作機制,是當今該領域中最重大的挑戰之一。隨著模型變得越來越龐大且功能更強大,深入了解這個「黑盒子」對於安全性、對齊(alignment)以及推進 AI 科學至關重要。Neuronpedia 提供一個開源平台,專門用於加速您的機制可解釋性研究,提供您取得突破所需的資料、工具和協作環境。我們負責處理基礎設施——視覺化、工具、擴展和託管——讓您可以純粹專注於研究。
主要特色
🔍 探索龐大的資料集: 存取和分析超過 4TB 的預先計算資料,包括神經元激活、特徵解釋(例如 Sparse Autoencoders - SAEs 所產生的解釋)以及各種模型中的相關中繼資料。該平台支援多樣化的可解釋性方法,包括 probes、latents/features、概念和自定義向量。
🧭 引導模型行為: 透過修改推論過程中的激活,直接對模型內部進行實驗。使用已識別的 latents/features 或自定義向量來影響 instruct (chat) 和推理模型中的模型輸出。微調 steering 參數,例如溫度、強度和 seed,以進行受控實驗。
🔎 進階搜尋功能: 有效篩選超過 5000 萬個 latents、features 和向量。使用自然語言描述進行語義搜尋,或透過推論在模型中執行自定義文字提示,以精確找出激活最強烈的內部組件。
🔬 檢查神經組件: 深入研究個別的 probes、latents 或 features。檢查最活躍的資料集範例,分析對輸出 logits 的影響,視覺化激活密度,並直接在介面中執行即時推論測試。建立可分享的清單或嵌入儀表板以進行協作。
💻 全面的 API & 函式庫: 將 Neuronpedia 的功能直接整合到您的研究工作流程中。透過完善的文件化 API(具有 OpenAPI 規範)和方便的 Python/TypeScript 函式庫,以程式化的方式存取所有平台功能,包括資料探索、引導和搜尋。
🌐 開源基礎: 建立在一個透明且社群驅動的平台上。核心 Neuronpedia 代碼庫和廣泛的資料集可在 GitHub 上取得,鼓勵研究社群貢獻、驗證和擴展。
使用案例
模型內的概念映射: 假設您正在研究像 Llama 3.1 這樣的模型如何表示抽象概念,例如「樂觀」或「Python 程式碼」。您可以使用 Neuronpedia 的 Search 功能,透過語義描述或相關的文字提示來識別潛在相關的 features/latents。然後,使用 Inspect 工具來分析它們最活躍的激活和下游效應,驗證它們是否一致地編碼目標概念。
驗證因果干預: 在識別出似乎代表特定安全問題(例如,產生有害內容)的 feature 之後,您可以使用 Steer 功能。透過在相關提示的推論過程中主動抑制或放大此 feature 的激活,您可以測試關於其在模型行為中的因果角色的假設,並可能開發出減輕相關風險的方法。
跨架構的比較分析: 研究不同的模型(例如,Gemma-2 與 GPT2-Small)如何表示相似的資訊?使用 Explore 和 Inspect 工具來瀏覽和比較兩個模型中等效層或概念之間的激活或已學習的 features(例如 SAEs),從而闡明架構差異和表示策略。
結論
Neuronpedia 是 AI 可解釋性社群的一個基礎資源。透過在開源框架內提供大規模資料集、強大的互動工具和程式化存取,它旨在顯著降低入門門檻,並加速在理解神經網路方面的進展。無論您是探索現有模型、開發新的可解釋性技術,還是試驗模型控制,Neuronpedia 都提供了支援您工作的基礎設施。
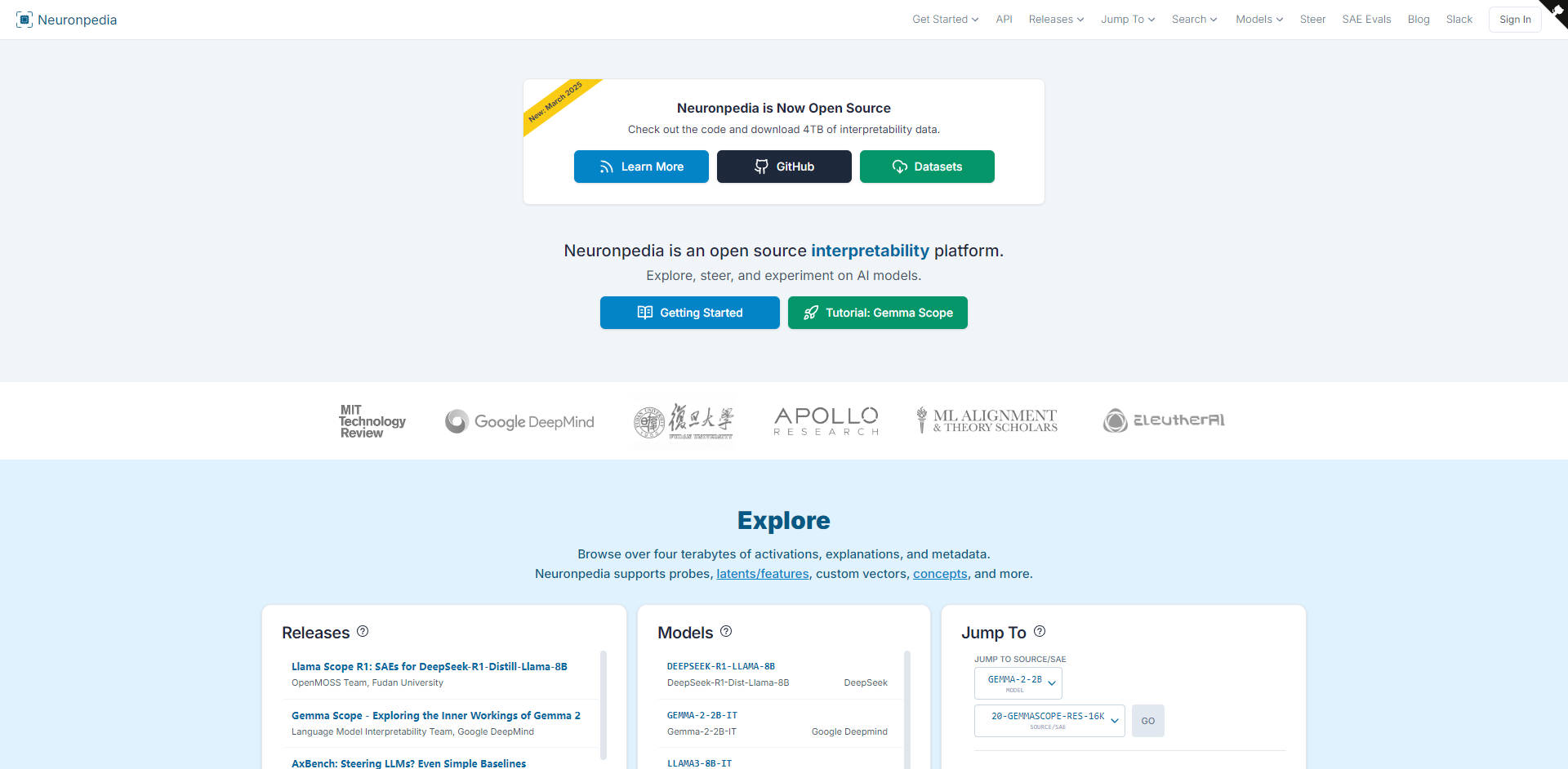
More information on Neuronpedia
Launched
2023-06
Pricing Model
Starting Price
Global Rank
871499
Follow
Month Visit
29.2K
Tech used
Next.js,Vercel,Gzip,OpenGraph,Progressive Web App,Webpack,HSTS
Top 5 Countries
54.4%
22.21%
9.82%
5.73%
2.89%
United States
United Kingdom
India
Germany
Italy
Traffic Sources
8.95%
0.83%
0.1%
7.94%
33.24%
48.88%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Neuronpedia was manually vetted by our editorial team and was first featured on 2025-04-01.
Related Searches