
What is Crawlspace?
Crawlspaceは、ウェブクローリングとデータ抽出を簡素化するために設計された、開発者向けのプラットフォームです。アプリケーションの構築、AIモデルのトレーニング、インサイトの収集など、どのような目的であっても、Crawlspaceはインフラストラクチャ管理の煩わしさなく、最新で構造化されたデータを大規模に収集することを可能にします。
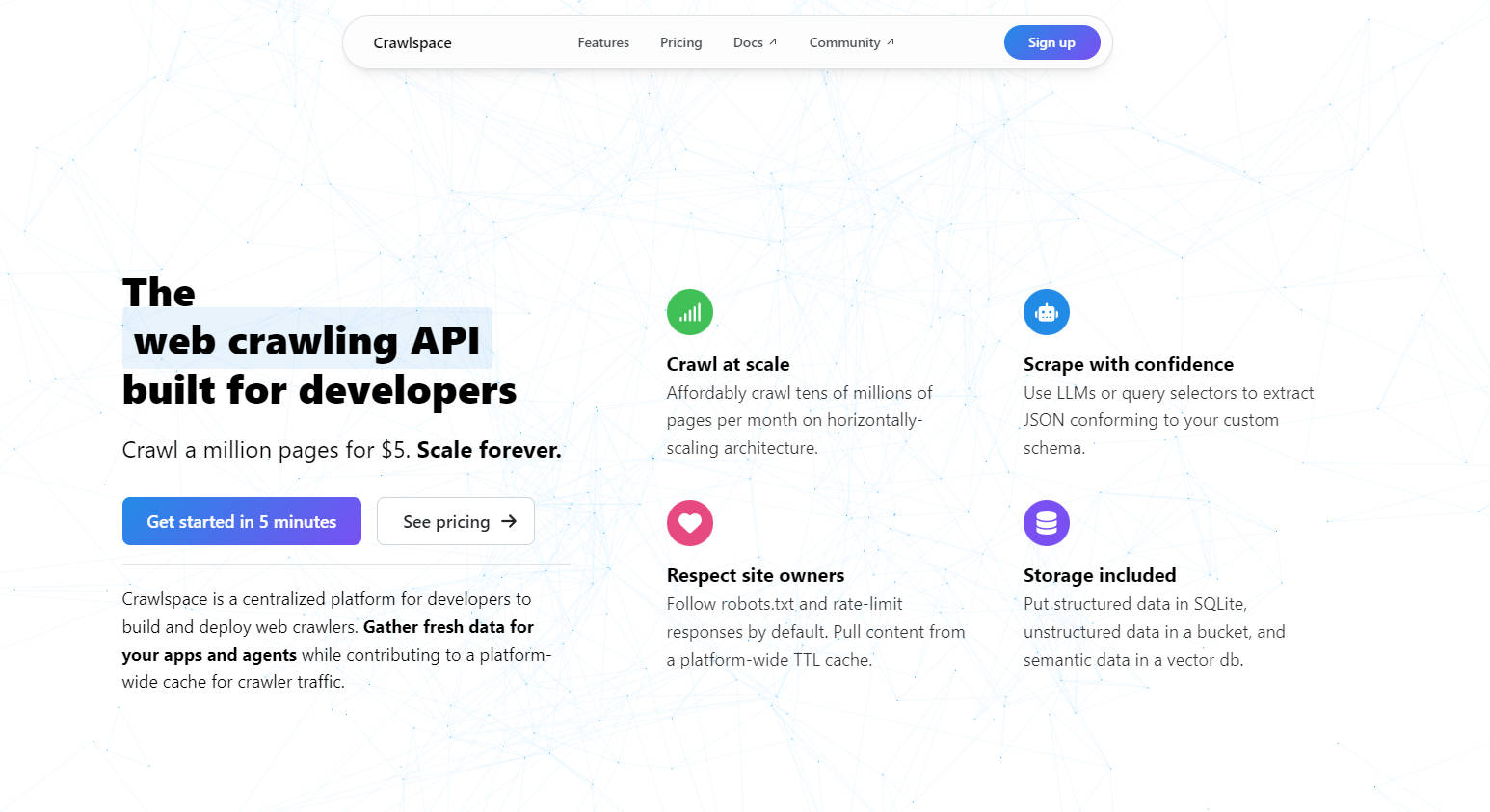
主な機能
? 大規模クローリング
月間数千万ページを低価格でクローリングできます。水平スケーリングアーキテクチャにより、パフォーマンスのボトルネックを心配することなく、プロジェクトを拡大できます。
? スマートデータ抽出
LLMまたはクエリセレクタを使用して、カスタムスキーマに適合するJSONデータを抽出します。テキスト、画像、メタデータのスクレイピングに関わらず、Crawlspaceはデータがきれいで使用可能な状態であることを保証します。
? 丁寧なクローリング
デフォルトでrobots.txtに従い、応答レートを制限します。さらに、プラットフォーム全体のTTLキャッシュを活用して、冗長なトラフィックを削減し、ウェブサイト所有者を尊重します。
?️ 柔軟なストレージ
構造化データはSQLiteに、非構造化データはS3互換のバケットに、セマンティックデータはベクターデータベースに保存できます。これらはすべて、クラウラーに含まれています。
? サーバーレスデプロイ
ウェブサイトをデプロイするのと同じくらい簡単にウェブクラウラーをデプロイできます。管理するインフラストラクチャはなく、維持するサーバーもありません。構築に集中できます。
ユースケース
AIトレーニングデータ収集
機械学習モデルをトレーニングするための最新で構造化されたデータを収集します。LLMを使用して、データを直接好みのスキーマに抽出し、フォーマットします。市場調査
競合他社のウェブサイトを監視し、価格変更を追跡したり、製品の詳細を大規模にスクレイピングしたりできます。レート制限とrobots.txtを遵守しながら行えます。コンテンツ集約
ニュースアグリゲーター、求人情報サイト、またはリサーチプラットフォーム向けの動的なデータセットを構築します。SQLiteまたはベクターデータベースにデータを保存して、容易に検索および分析できます。
Crawlspaceを選ぶ理由
費用対効果が高い:100万ページのクローリングはわずか5ドルです。
開発者フレンドリー:TypeScriptファーストで、JavaScriptとnpmパッケージをサポートしています。
可観測性:OpenTelemetryを使用してトラフィックログを監視し、完全な透明性を確保します。
常時無料のデータ送出:追加費用を心配することなく、データセットをダウンロードできます。
FAQ
Q: Crawlspaceはどのように冗長なボットトラフィックを削減しますか?
A: Crawlspaceはプラットフォーム全体のTTLキャッシュを使用します。複数のクラウラーが設定された時間枠内に同じURLを要求した場合、応答はキャッシュから取得され、オリジンサーバーへのトラフィックが削減されます。
Q: ソーシャルメディアウェブサイトをクローリングできますか?
A: いいえ。LinkedInやXなどのソーシャルメディアプラットフォームは、robots.txtファイルでクローリングを明示的に禁止しています。ソーシャルメディアデータの場合は、データエンリッチメントプラットフォームの使用を検討してください。
Q: GPT-4などのサードパーティのAIモデルを使用できますか?
A: はい!クラウラーの.envファイルにAPIトークンを配置し、OpenAIやAnthropicなどのプロバイダーからのモデルをスクレイピングと埋め込みに使用できます。
Q: Crawlspaceはウェブサイトポリシーに準拠していますか?
A: はい、もちろん。Crawlspaceは、デフォルトでrobots.txtとレート制限を尊重し、クラウラーが丁寧でコンプライアンスを遵守していることを保証します。
よりスマートに構築し、より良くクローリングする
Crawlspaceは単なるウェブクローリングプラットフォームではありません。それは、あなたの次の画期的なアイデアの基盤です。手頃な価格、開発者フレンドリーなツール、そして丁寧なクローリングへのコミットメントにより、データ収集の取り組みを拡大するための究極のソリューションです。
始めましょう。今日、最初のクラウラーをデプロイして、ウェブクローリングの未来を体験してください。
More information on Crawlspace
Launched
2024-09
Pricing Model
Freemium
Starting Price
$29/ month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Gzip,OpenGraph
Crawlspace was manually vetted by our editorial team and was first featured on 2025-01-22.
Related Searches
Crawlspace 代替ソフト
もっと見る 代替ソフト-

-

-

-

Webcrawlerapiを使えば、ウェブデータ抽出が簡単になります! JavaScriptの処理、プロキシ、スケーリングに対応。AIや分析などに必要な構造化データを取得できます。
-
