
What is Crawlspace?
Crawlspace 是一个面向开发者的平台,旨在简化网页爬取和数据提取。无论您是构建应用程序、训练 AI 模型还是收集见解,Crawlspace 都能帮助您大规模收集新鲜、结构化的数据,而无需费心管理基础设施。
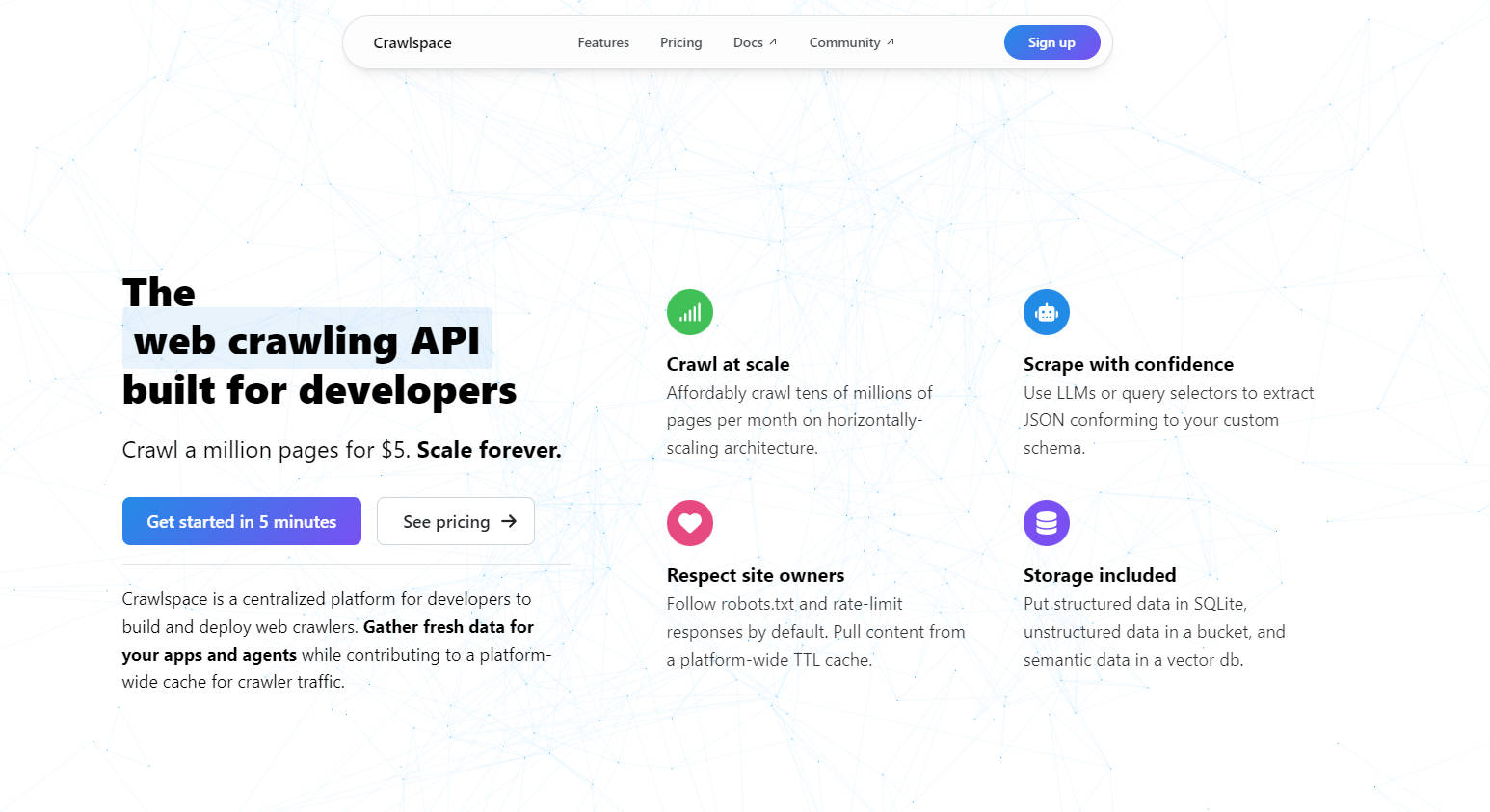
主要功能
? 大规模爬取
每月经济高效地爬取数千万个页面。凭借水平扩展架构,您可以扩展项目规模,而无需担心性能瓶颈。
? 智能数据提取
使用大型语言模型 (LLM) 或查询选择器提取符合您自定义架构的 JSON 数据。无论您是在抓取文本、图像还是元数据,Crawlspace 都能确保您的数据干净可用。
? 尊重网站规则的爬取
默认情况下遵循 robots.txt 并限制请求速率。此外,利用平台范围的 TTL 缓存来减少冗余流量并尊重网站所有者。
?️ 灵活的存储
将结构化数据存储在 SQLite 中,将非结构化数据存储在与 S3 兼容的存储桶中,并将语义数据存储在向量数据库中——所有这些都包含在您的爬虫中。
? 无服务器部署
像部署网站一样轻松地部署网络爬虫。无需管理基础设施,无需维护服务器——只需专注于构建。
使用案例
AI 训练数据收集
收集新鲜的结构化数据来训练机器学习模型。使用大型语言模型 (LLM) 直接将数据提取并格式化为您的首选架构。市场调研
监控竞争对手网站,跟踪价格变化,或大规模抓取产品详细信息——同时尊重速率限制和 robots.txt。内容聚合
为新闻聚合器、招聘网站或研究平台构建动态数据集。将数据存储在 SQLite 或向量数据库中,以便于检索和分析。
为什么选择 Crawlspace?
经济高效:只需 5 美元即可爬取一百万个页面。
开发者友好:优先使用 TypeScript,并支持 JavaScript 和 npm 包。
可观测性:使用 OpenTelemetry 监控流量日志,实现完全透明。
永久免费出站流量:下载您的数据集无需担心额外费用。
常见问题
问:Crawlspace 如何减少冗余的机器人流量?
答:Crawlspace 使用平台范围的 TTL 缓存。当多个爬虫在设定的时间窗口内请求相同的 URL 时,响应将从缓存中提取,从而减少了对源服务器的流量。
问:我可以爬取社交媒体网站吗?
答:不可以。像 LinkedIn 和 X 这样的社交媒体平台在其 robots.txt 文件中明确禁止爬取。对于社交媒体数据,请考虑使用数据丰富平台。
问:我可以使用 GPT-4 等第三方 AI 模型吗?
答:可以!将您的 API 密钥放在爬虫的 .env 文件中,并使用来自 OpenAI 或 Anthropic 等提供商的模型进行抓取和嵌入。
问:Crawlspace 是否符合网站策略?
答:当然。Crawlspace 默认情况下遵守 robots.txt 和速率限制,确保您的爬虫礼貌且符合规定。
构建更智能,爬取更出色
Crawlspace 不仅仅是一个网页爬取平台,更是您下一个突破性想法的基础。凭借经济实惠的价格、开发者友好的工具以及对尊重网站规则的爬取的承诺,它是扩展数据收集工作的终极解决方案。
准备好开始了吗?立即部署您的第一个爬虫,体验网络爬取的未来。
More information on Crawlspace
Launched
2024-09
Pricing Model
Freemium
Starting Price
$29/ month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Gzip,OpenGraph
Crawlspace was manually vetted by our editorial team and was first featured on 2025-01-22.
Related Searches
Crawlspace 替代方案
更多 替代方案-

-

-

-

轻松提取网络数据!Webcrawlerapi 可处理 JavaScript、代理和扩展等问题。获取结构化数据,用于 AI、分析及其他用途。
-
