
What is Crawlspace?
Crawlspace 是一個以開發者為中心的平台,旨在簡化網頁爬蟲和數據提取。無論您是構建應用程式、訓練 AI 模型還是收集洞察,Crawlspace 都能讓您大規模收集新鮮、結構化的數據,而無需費心管理基礎設施。
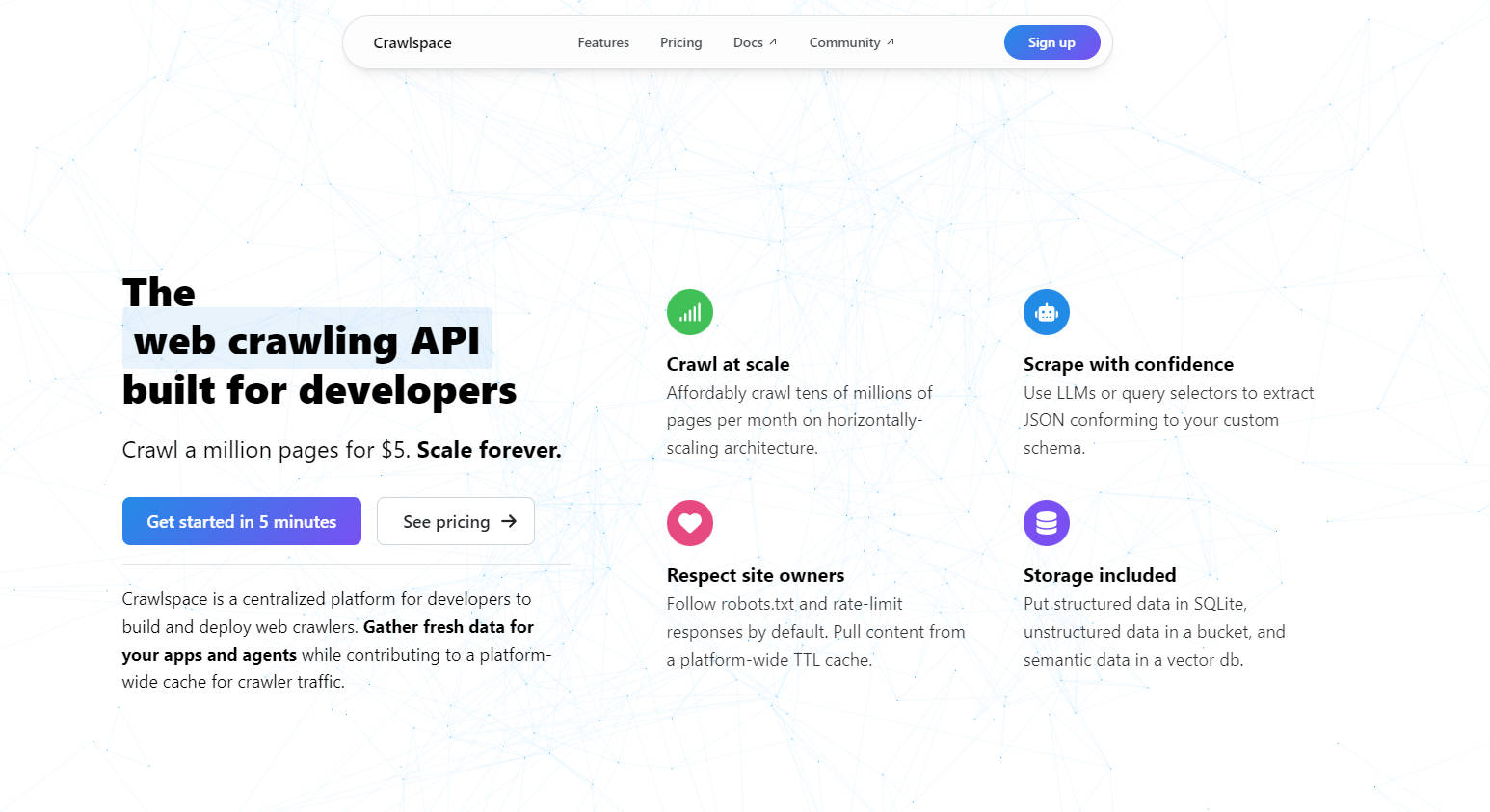
主要功能
? 大規模爬取
每月以經濟實惠的價格爬取數千萬個網頁。透過水平擴展架構,您可以擴展專案規模,而無需擔心效能瓶頸。
? 智慧型數據提取
使用大型語言模型 (LLM) 或查詢選擇器來提取符合您自訂架構的 JSON 數據。無論您是在抓取文字、圖片還是元數據,Crawlspace 都能確保您的數據乾淨且可用。
? 尊重網站規則的爬取
預設遵循 robots.txt 並限制請求速率。此外,利用平台級的 TTL 快取來減少冗餘流量並尊重網站所有者。
?️ 彈性儲存
將結構化數據儲存在 SQLite 中,將非結構化數據儲存在與 S3 相容的儲存桶中,以及將語義數據儲存在向量數據庫中——所有這些都包含在您的爬蟲中。
? 無伺服器部署
像部署網站一樣輕鬆地部署網頁爬蟲。無需管理基礎設施,無需維護伺服器——只需專注於構建。
使用案例
AI 訓練數據收集
收集新鮮、結構化的數據來訓練機器學習模型。使用大型語言模型 (LLM) 直接將數據提取並格式化到您偏好的架構中。市場研究
監控競爭對手的網站,追蹤價格變動,或大規模抓取產品詳情——同時遵守速率限制和 robots.txt。內容聚合
為新聞聚合器、求職網站或研究平台構建動態數據集。將數據儲存在 SQLite 或向量數據庫中,以便輕鬆檢索和分析。
為什麼選擇 Crawlspace?
經濟實惠:爬取一百萬個網頁只需 5 美元。
開發者友善:優先使用 TypeScript,並支援 JavaScript 和 npm 套件。
可觀察性:使用 OpenTelemetry 監控流量日誌,實現完全透明。
免費數據傳出:下載您的數據集,無需擔心額外費用。
常見問題
問:Crawlspace 如何減少冗餘機器人流量?
答:Crawlspace 使用平台級的 TTL 快取。當多個爬蟲在設定的時間窗口內請求相同的 URL 時,響應會從快取中提取,從而減少到原始伺服器的流量。
問:我可以爬取社群媒體網站嗎?
答:不可以。像 LinkedIn 和 X 這樣的社群媒體平台在其 robots.txt 檔案中明確禁止爬取。對於社群媒體數據,請考慮使用數據增強平台。
問:我可以使用 GPT-4 等第三方 AI 模型嗎?
答:可以!將您的 API 金鑰放在爬蟲的 .env 檔案中,並使用來自 OpenAI 或 Anthropic 等提供商的模型進行抓取和嵌入。
問:Crawlspace 是否符合網站政策?
答:絕對符合。Crawlspace 預設遵守 robots.txt 和速率限制,確保您的爬蟲禮貌且符合規定。
更聰明地構建,更好地爬取
Crawlspace 不僅僅是一個網頁爬蟲平台,更是您下一個突破性想法的基礎。憑藉經濟實惠的價格、開發者友好的工具以及對尊重網站規則爬取的承諾,它是擴展數據收集工作的終極解決方案。
準備開始了嗎?立即部署您的第一個爬蟲,體驗網頁爬取的未來。
More information on Crawlspace
Launched
2024-09
Pricing Model
Freemium
Starting Price
$29/ month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Gzip,OpenGraph
Crawlspace was manually vetted by our editorial team and was first featured on 2025-01-22.
Related Searches
Crawlspace 替代方案
更多 替代方案-

-

-

-

輕鬆擷取網路資料!Webcrawlerapi 處理 JavaScript、代理伺服器與擴展性。取得結構化資料,用於 AI、分析及其他用途。
-
