
What is Crawlspace?
Crawlspace — это платформа, разработанная для разработчиков, призванная упростить веб-сканирование и извлечение данных. Независимо от того, создаёте ли вы приложения, обучаете модели ИИ или собираете аналитические данные, Crawlspace предоставляет вам возможность собирать свежие, структурированные данные в масштабе — без головной боли, связанной с управлением инфраструктурой.
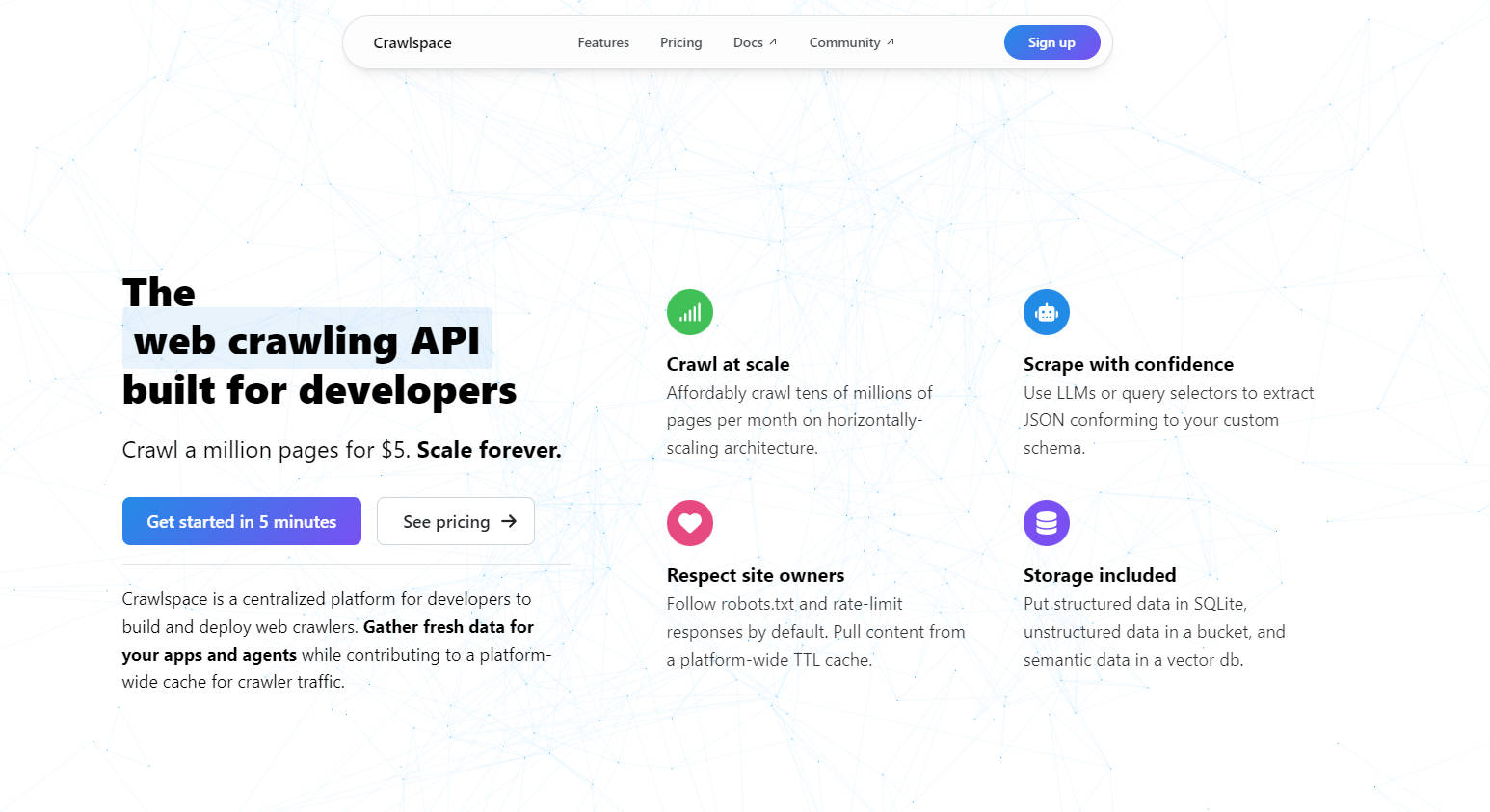
Ключевые возможности
? Масштабируемое сканирование
Доступно сканируйте десятки миллионов страниц в месяц. Благодаря горизонтально масштабируемой архитектуре вы можете расширять свои проекты, не беспокоясь о узких местах производительности.
? Интеллектуальное извлечение данных
Используйте большие языковые модели (LLM) или селекторы запросов для извлечения данных JSON, соответствующих вашей пользовательской схеме. Независимо от того, извлекаете ли вы текст, изображения или метаданные, Crawlspace гарантирует чистоту и пригодность ваших данных.
? Бережное сканирование
По умолчанию соблюдаются правила robots.txt и ограничения скорости ответов. Кроме того, используйте кэш TTL на всей платформе, чтобы уменьшить избыточный трафик и уважать владельцев веб-сайтов.
?️ Гибкое хранилище
Храните структурированные данные в SQLite, неструктурированные данные — в совместимом с S3 хранилище, а семантические данные — в базе данных векторов — всё это включено в ваш сканер.
? Бессерверное развертывание
Развертывайте веб-сканеры так же легко, как и веб-сайты. Вам не нужно управлять инфраструктурой, обслуживать серверы — просто сосредоточьтесь на разработке.
Варианты использования
Сбор данных для обучения ИИ
Собирайте свежие, структурированные данные для обучения моделей машинного обучения. Используйте большие языковые модели для извлечения и форматирования данных непосредственно в вашу предпочитаемую схему.Маркетинговые исследования
Мониторьте сайты конкурентов, отслеживайте изменения цен или собирайте информацию о продуктах в масштабе — всё это с соблюдением ограничений скорости и robots.txt.Агрегация контента
Создавайте динамические наборы данных для агрегаторов новостей, досок объявлений или исследовательских платформ. Храните данные в SQLite или базах данных векторов для удобного поиска и анализа.
Почему стоит выбрать Crawlspace?
Экономичность:Сканирование миллиона страниц всего за $5.
Удобство для разработчиков:В первую очередь TypeScript, с поддержкой JavaScript и пакетов npm.
Наблюдаемость:Мониторинг журналов трафика с помощью OpenTelemetry для полной прозрачности.
Бесплатный вывод данных:Загружайте свои наборы данных, не беспокоясь о дополнительных расходах.
Часто задаваемые вопросы
В: Как Crawlspace уменьшает избыточный трафик ботов?
О: Crawlspace использует кэш TTL на всей платформе. Когда несколько сканеров запрашивают один и тот же URL в течение заданного временного интервала, ответ извлекается из кэша, что уменьшает трафик на исходный сервер.
В: Можно ли сканировать сайты социальных сетей?
О: Нет. Платформы социальных сетей, такие как LinkedIn и X, прямо запрещают сканирование в своих файлах robots.txt. Для данных социальных сетей рассмотрите возможность использования платформ обогащения данных.
В: Можно ли использовать сторонние модели ИИ, такие как GPT-4?
О: Да! Поместите свои токены API в файл .env вашего сканера и используйте модели от таких поставщиков, как OpenAI или Anthropic, для извлечения и встраивания данных.
В: Соответствует ли Crawlspace политике веб-сайтов?
О: Безусловно. Crawlspace по умолчанию соблюдает robots.txt и ограничения скорости, гарантируя вежливое и корректное поведение ваших сканеров.
Стройте умнее, сканируйте лучше
Crawlspace — это больше, чем просто платформа для веб-сканирования; это основа для вашей следующей революционной идеи. Благодаря доступным ценам, удобным для разработчиков инструментам и стремлению к бережному сканированию, это оптимальное решение для масштабирования ваших усилий по сбору данных.
Готовы начать? Разверните свой первый сканер сегодня и испытайте будущее веб-сканирования.
More information on Crawlspace
Launched
2024-09
Pricing Model
Freemium
Starting Price
$29/ month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Gzip,OpenGraph
Crawlspace was manually vetted by our editorial team and was first featured on 2025-01-22.
Related Searches
Crawlspace Альтернативи
Больше Альтернативи-

-

-

-

Извлекайте веб-данные без усилий! Webcrawlerapi обрабатывает JavaScript, прокси и масштабирование. Получайте структурированные данные для искусственного интеллекта, анализа и многого другого.
-
