
What is DreamOmni2?
DreamOmni2 is an advanced, open-source AI image editing model developed by the Hong Kong University of Science and Technology (HKUST) Jia Jiaya team. It fundamentally solves the limitations of previous models by moving beyond simple physical object recognition to achieve true multi-modal, multi-concept fusion. This platform empowers designers, e-commerce merchants, and the global creative community to execute professional-grade, highly precise image edits using only natural language and reference images.
Key Features
DreamOmni2’s architecture is engineered to provide depth and flexibility in creative workflows, enabling complex edits that were previously impossible through language alone.
🎨 Deep Abstract Concept Understanding
The model recognizes not only physical entities but also grasps abstract attributes like style, material texture, ambient light, and shadow dynamics. This capability ensures that when you instruct the model to change an object's material or adapt the scene's mood, the resulting image maintains photorealistic consistency and nuance, demonstrating a generational advantage in handling abstract attributes.
🖼️ Collaborative Multi-Image Fusion
DreamOmni2 innovatively supports 2 to 4 reference images simultaneously within a single instruction. This allows for precise element fusion, enabling you to combine an object from Image A, a style from Image B, and lighting from Image C into a single, cohesive output. This is achieved through proprietary Index Encoding and Position Encoding Shift technology, which accurately distinguishes and fuses concepts without pixel confusion or artifact generation.
✍️ Professional Natural Language Operation
Achieve professional-grade image editing entirely through precise text and image instructions. The platform utilizes a Visual Language Model (VLM) component to deeply understand complex user intent before execution, solving the pain points of traditional tools that struggle with ambiguous or multi-step demands. This eliminates the need for manual, layer-based manipulation for tasks like object replacement or detailed style migration.
💡 Lightweight and Open-Source Accessibility
As a free, open-source model, DreamOmni2 is designed for broad accessibility. It retains the original instruction editing and text-to-image capabilities of its base model while requiring less than 16GB VRAM. This allows creators and tech enthusiasts to run powerful multi-modal editing locally on ordinary machines or through services like Google Colab, significantly lowering the barrier to entry for advanced AI image creation.
Use Cases
DreamOmni2 transforms several professional and creative workflows by providing high-precision, multi-modal control.
Accelerating E-commerce and Design Workflows
Taobao merchants and designers can rapidly generate clothing or product variations without expensive reshoots. For example, a merchant can use a reference image of a new pattern and a reference image of a model, instructing DreamOmni2 to seamlessly apply the pattern to the garment while preserving realistic fabric folds, shadows, and lighting consistency.
Complex Scene and Character Integration
Execute highly detailed character replacement while maintaining environmental realism. You can replace a character in a complex scene with a new reference image, and the model will accurately migrate facial lighting, preserve background details, and replicate nuanced elements like eye details, neck shadows, and hair consistency, achieving integration precision that surpasses simple language descriptions.
Advanced Multi-Reference Style Blending
Designers can achieve complex visual demands by blending multiple concepts simultaneously. For instance, combine a specific object (e.g., a parrot) from one image, make it wear a specific accessory (a hat) from a second image, and then apply the unique artistic atmosphere and tone (e.g., red-blue contrast lighting) from a third reference image, all through a single, concise instruction.
Unique Advantages
DreamOmni2 differentiates itself through superior performance in complex, nuanced tasks and its innovative approach to multi-modal instruction execution, providing tangible benefits to serious creators.
Verified Superiority in Abstract Processing
DreamOmni2 shows a verifiable performance advantage over comparable models, including Google’s Nano Banana and OpenAI’s GPT-4o, specifically when handling abstract concepts and ensuring consistency. In benchmark tests, DreamOmni2 achieved 37% higher generation accuracy and 29% higher object consistency than other leading open-source models, proving its ability to deliver high-fidelity, consistent results in complex editing scenarios.
Deep Instruction Understanding via VLM Joint Training
The core competitiveness of DreamOmni2 lies in its innovative architecture, which jointly trains a Visual Language Model (VLM, such as Qwen2.5-VL 7B) with the generative model. The VLM acts as an intelligent translator, first deeply understanding the full context of the user’s multi-modal instruction (text + images) before passing it to the generative model for execution. This separation of understanding and generation significantly enhances the model’s ability to execute highly accurate, detailed processing.
Open-Source Freedom and Community Focus
As an open-source project from a major university research team, DreamOmni2 offers full transparency and flexibility. Its lightweight deployment requirements (under 16GB VRAM) ensure that researchers, developers, and creators worldwide can access and integrate this powerful tool into their workflows, fostering rapid iteration and secondary development within the creative community.
Conclusion
DreamOmni2 represents a significant step forward in open-source AI image editing, offering the power of multi-modal input and the precision necessary for professional-grade results. By focusing on abstract attribute understanding and complex, multi-reference fusion, DreamOmni2 empowers you to achieve sophisticated creative visions with unprecedented ease and accuracy.
Explore the open project page and code repository today to experience the next generation of natural language image editing.
FAQ
Q: What makes DreamOmni2 different from standard text-to-image models? A: Traditional models primarily rely on text prompts, which struggle to accurately convey abstract concepts (like specific lighting or material texture) or precisely combine elements from multiple images. DreamOmni2’s multi-modal architecture allows you to provide 1-4 reference images alongside text, enabling the model to precisely replicate non-verbal attributes and execute complex fusion tasks with high fidelity and consistency.
Q: What are the minimum hardware requirements for running DreamOmni2 locally? A: DreamOmni2 is designed to be lightweight and accessible. It requires less than 16GB of VRAM, meaning it can be run effectively on many ordinary local machines or accessed via cloud computing environments like Google Colab, without needing high-end, specialized hardware configurations.
Q: Who developed DreamOmni2, and why is its benchmark performance significant? A: DreamOmni2 was developed by the Jia Jiaya team at the Hong Kong University of Science and Technology (HKUST). Its benchmark performance is significant because the team created a new, comprehensive test set (the "DreamOmni2 benchmark") covering abstract attributes and concrete object editing. In these rigorous tests, DreamOmni2 demonstrated higher accuracy and consistency in abstract concept processing compared to established closed-source models like Google Nano Banana and GPT-4o.
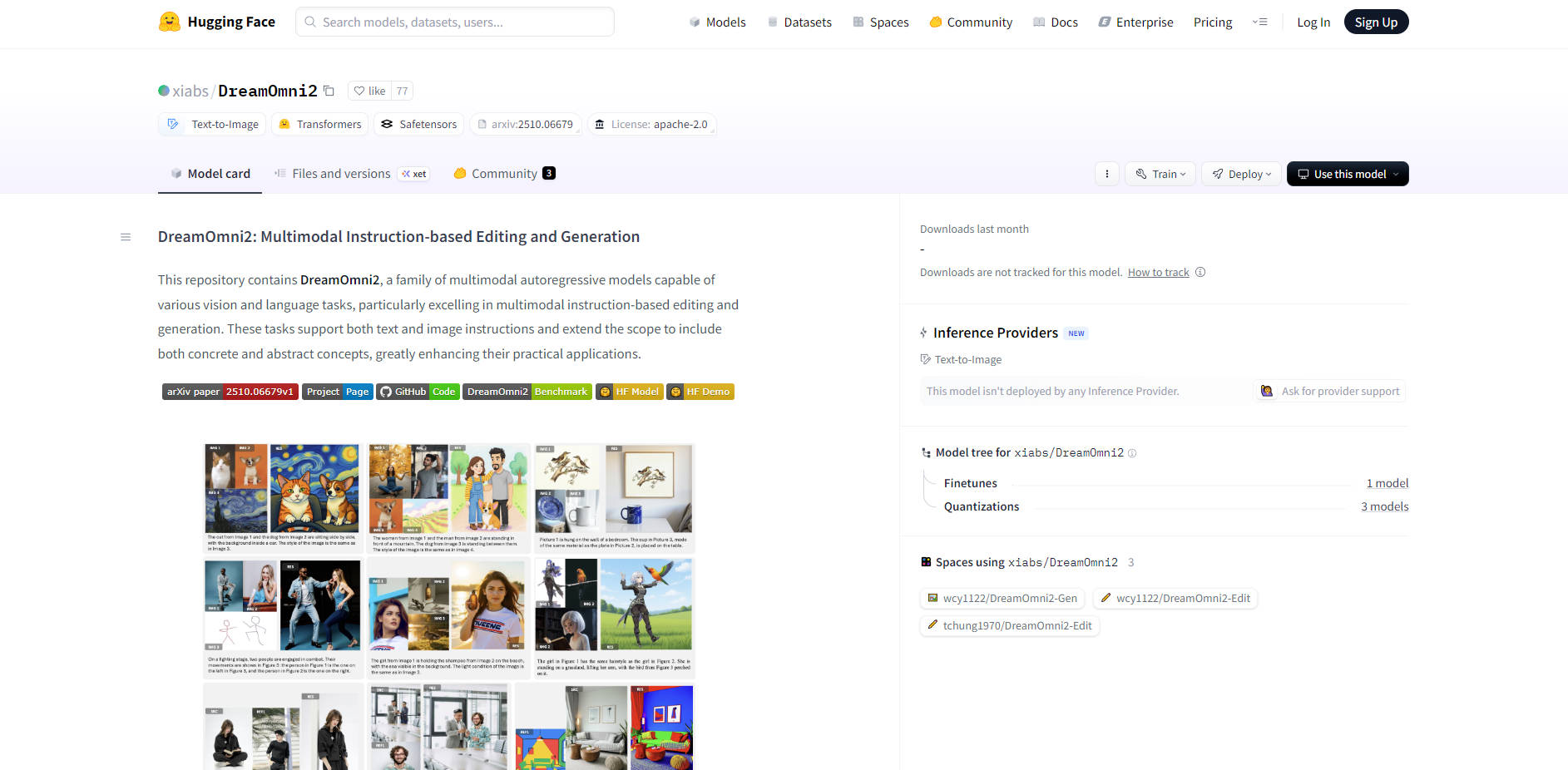
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 Alternatives
Load more Alternatives-
Nano Banana: AI image editing & creation with Gemini 2.5 Flash. Achieve precise, text-based transformations & unmatched character consistency, fast.
-

OmniGen AI by BAAI is a cutting-edge text-to-image model. Unified framework for seamless creation. Transforms text & images. Ideal for artists, marketers & researchers. Empower your creativity!
-

OLMo 2 32B: Open-source LLM rivals GPT-3.5! Free code, data & weights. Research, customize, & build smarter AI.
-
Nano Banana redefines AI image editing. Get unmatched character consistency & 10x faster workflows, powered by Gemini for precise creative vision.
-

Boost LLM efficiency with DeepSeek-OCR. Compress visual documents 10x with 97% accuracy. Process vast data for AI training & enterprise digitization.