
What is DreamOmni2?
DreamOmni2 es un modelo avanzado de edición de imágenes por IA de código abierto, desarrollado por el equipo de Jia Jiaya de la Universidad de Ciencia y Tecnología de Hong Kong (HKUST). Resuelve de forma fundamental las limitaciones de los modelos anteriores al trascender el mero reconocimiento de objetos físicos para lograr una verdadera fusión multimodal y multiconceptual. Esta plataforma permite a diseñadores, comerciantes electrónicos y a la comunidad creativa global realizar ediciones de imágenes con calidad profesional y alta precisión, utilizando únicamente lenguaje natural e imágenes de referencia.
Características Clave
La arquitectura de DreamOmni2 está diseñada para ofrecer profundidad y flexibilidad en los flujos de trabajo creativos, haciendo posibles ediciones complejas que antes eran inalcanzables solo con el lenguaje.
🎨 Comprensión Profunda de Conceptos Abstractos
El modelo no solo reconoce entidades físicas, sino que también capta atributos abstractos como el estilo, la textura del material, la luz ambiental y la dinámica de las sombras. Esta capacidad asegura que, al instruir al modelo para cambiar el material de un objeto o adaptar el ambiente de una escena, la imagen resultante mantiene una consistencia y un matiz fotorrealistas, demostrando una ventaja generacional en el manejo de atributos abstractos.
🖼️ Fusión Colaborativa de Múltiples Imágenes
DreamOmni2 soporta de forma innovadora entre 2 y 4 imágenes de referencia simultáneamente dentro de una única instrucción. Esto permite una fusión precisa de elementos, posibilitando combinar un objeto de la Imagen A, un estilo de la Imagen B y la iluminación de la Imagen C en una única salida cohesiva. Esto se logra mediante la tecnología propietaria Index Encoding y Position Encoding Shift, que distingue y fusiona conceptos con precisión, sin confusión de píxeles ni generación de artefactos.
✍️ Operación Profesional con Lenguaje Natural
Logre una edición de imágenes de nivel profesional utilizando únicamente instrucciones precisas de texto e imagen. La plataforma utiliza un componente de Modelo de Lenguaje Visual (VLM) para comprender a fondo la compleja intención del usuario antes de la ejecución, resolviendo los puntos débiles de las herramientas tradicionales que tienen dificultades con demandas ambiguas o de varios pasos. Esto elimina la necesidad de manipulación manual basada en capas para tareas como la sustitución de objetos o la migración detallada de estilos.
💡 Accesibilidad Ligera y de Código Abierto
Como modelo gratuito y de código abierto, DreamOmni2 está diseñado para una amplia accesibilidad. Conserva las capacidades originales de edición de instrucciones y de texto a imagen de su modelo base, requiriendo menos de 16GB de VRAM. Esto permite a creadores y entusiastas de la tecnología ejecutar potentes ediciones multimodales localmente en máquinas ordinarias o a través de servicios como Google Colab, reduciendo significativamente la barrera de entrada para la creación avanzada de imágenes por IA.
Casos de Uso
DreamOmni2 transforma diversos flujos de trabajo profesionales y creativos al ofrecer un control multimodal de alta precisión.
Aceleración de Flujos de Trabajo de Comercio Electrónico y Diseño
Los comerciantes y diseñadores de Taobao pueden generar rápidamente variaciones de ropa o productos sin costosos retoques o nuevas sesiones fotográficas. Por ejemplo, un comerciante puede utilizar una imagen de referencia de un nuevo patrón y una imagen de referencia de un modelo, instruyendo a DreamOmni2 para que aplique el patrón a la prenda de forma impecable, conservando los pliegues realistas de la tela, las sombras y la consistencia de la iluminación.
Integración de Escenas y Personajes Complejos
Realice una sustitución de personajes altamente detallada, manteniendo el realismo ambiental. Puede reemplazar un personaje en una escena compleja con una nueva imagen de referencia, y el modelo migrará con precisión la iluminación facial, conservará los detalles del fondo y replicará elementos matizados como los detalles de los ojos, las sombras del cuello y la consistencia del cabello, logrando una precisión de integración que supera las descripciones lingüísticas simples.
Fusión Avanzada de Estilos Multirreferencia
Los diseñadores pueden satisfacer demandas visuales complejas al fusionar múltiples conceptos simultáneamente. Por ejemplo, combine un objeto específico (p. ej., un loro) de una imagen, haga que use un accesorio específico (un sombrero) de una segunda imagen, y luego aplique la atmósfera y el tono artístico únicos (p. ej., iluminación de contraste rojo-azul) de una tercera imagen de referencia, todo a través de una única y concisa instrucción.
Ventajas Únicas
DreamOmni2 se diferencia por su rendimiento superior en tareas complejas y matizadas, y por su enfoque innovador en la ejecución de instrucciones multimodales, proporcionando beneficios tangibles a los creadores más exigentes.
Superioridad Verificada en el Procesamiento Abstracto
DreamOmni2 demuestra una ventaja de rendimiento verificable sobre modelos comparables, incluyendo Google Nano Banana y GPT-4o de OpenAI, específicamente al manejar conceptos abstractos y garantizar la coherencia. En pruebas de rendimiento, DreamOmni2 logró una precisión de generación un 37% mayor y una coherencia de objetos un 29% superior a la de otros modelos de código abierto líderes, lo que demuestra su capacidad para ofrecer resultados de alta fidelidad y consistentes en escenarios de edición complejos.
Comprensión Profunda de Instrucciones mediante Entrenamiento Conjunto de VLM
La competitividad central de DreamOmni2 reside en su innovadora arquitectura, que entrena conjuntamente un Modelo de Lenguaje Visual (VLM, como Qwen2.5-VL 7B) con el modelo generativo. El VLM actúa como un traductor inteligente, comprendiendo a fondo el contexto completo de la instrucción multimodal del usuario (texto + imágenes) antes de pasarlo al modelo generativo para su ejecución. Esta separación entre comprensión y generación mejora significativamente la capacidad del modelo para ejecutar un procesamiento altamente preciso y detallado.
Libertad de Código Abierto y Enfoque Comunitario
Como proyecto de código abierto de un importante equipo de investigación universitario, DreamOmni2 ofrece total transparencia y flexibilidad. Sus requisitos de despliegue ligeros (menos de 16GB de VRAM) garantizan que investigadores, desarrolladores y creadores de todo el mundo puedan acceder e integrar esta potente herramienta en sus flujos de trabajo, fomentando una rápida iteración y el desarrollo secundario dentro de la comunidad creativa.
Conclusión
DreamOmni2 representa un avance significativo en la edición de imágenes por IA de código abierto, ofreciendo la potencia de la entrada multimodal y la precisión necesaria para resultados de calidad profesional. Al centrarse en la comprensión de atributos abstractos y en la fusión compleja de múltiples referencias, DreamOmni2 le permite alcanzar visiones creativas sofisticadas con una facilidad y precisión sin precedentes.
Explore hoy mismo la página del proyecto abierto y el repositorio de código para experimentar la próxima generación de edición de imágenes mediante lenguaje natural.
Preguntas Frecuentes
P: ¿Qué diferencia a DreamOmni2 de los modelos estándar de texto a imagen? R: Los modelos tradicionales se basan principalmente en indicaciones de texto, que tienen dificultades para transmitir con precisión conceptos abstractos (como una iluminación específica o la textura de un material) o combinar elementos de varias imágenes con exactitud. La arquitectura multimodal de DreamOmni2 permite proporcionar de 1 a 4 imágenes de referencia junto con texto, lo que capacita al modelo para replicar con precisión atributos no verbales y ejecutar tareas de fusión complejas con alta fidelidad y coherencia.
P: ¿Cuáles son los requisitos mínimos de hardware para ejecutar DreamOmni2 localmente? R: DreamOmni2 está diseñado para ser ligero y accesible. Requiere menos de 16GB de VRAM, lo que significa que puede ejecutarse eficazmente en muchas máquinas locales comunes o accederse a través de entornos de computación en la nube como Google Colab, sin necesidad de configuraciones de hardware especializadas de alta gama.
P: ¿Quién desarrolló DreamOmni2 y por qué es significativo su rendimiento en los benchmarks? R: DreamOmni2 fue desarrollado por el equipo de Jia Jiaya en la Universidad de Ciencia y Tecnología de Hong Kong (HKUST). Su rendimiento en los benchmarks es significativo porque el equipo creó un nuevo y exhaustivo conjunto de pruebas (el "DreamOmni2 benchmark") que cubre atributos abstractos y la edición de objetos concretos. En estas rigurosas pruebas, DreamOmni2 demostró una mayor precisión y coherencia en el procesamiento de conceptos abstractos en comparación con modelos de código cerrado establecidos como Google Nano Banana y GPT-4o.
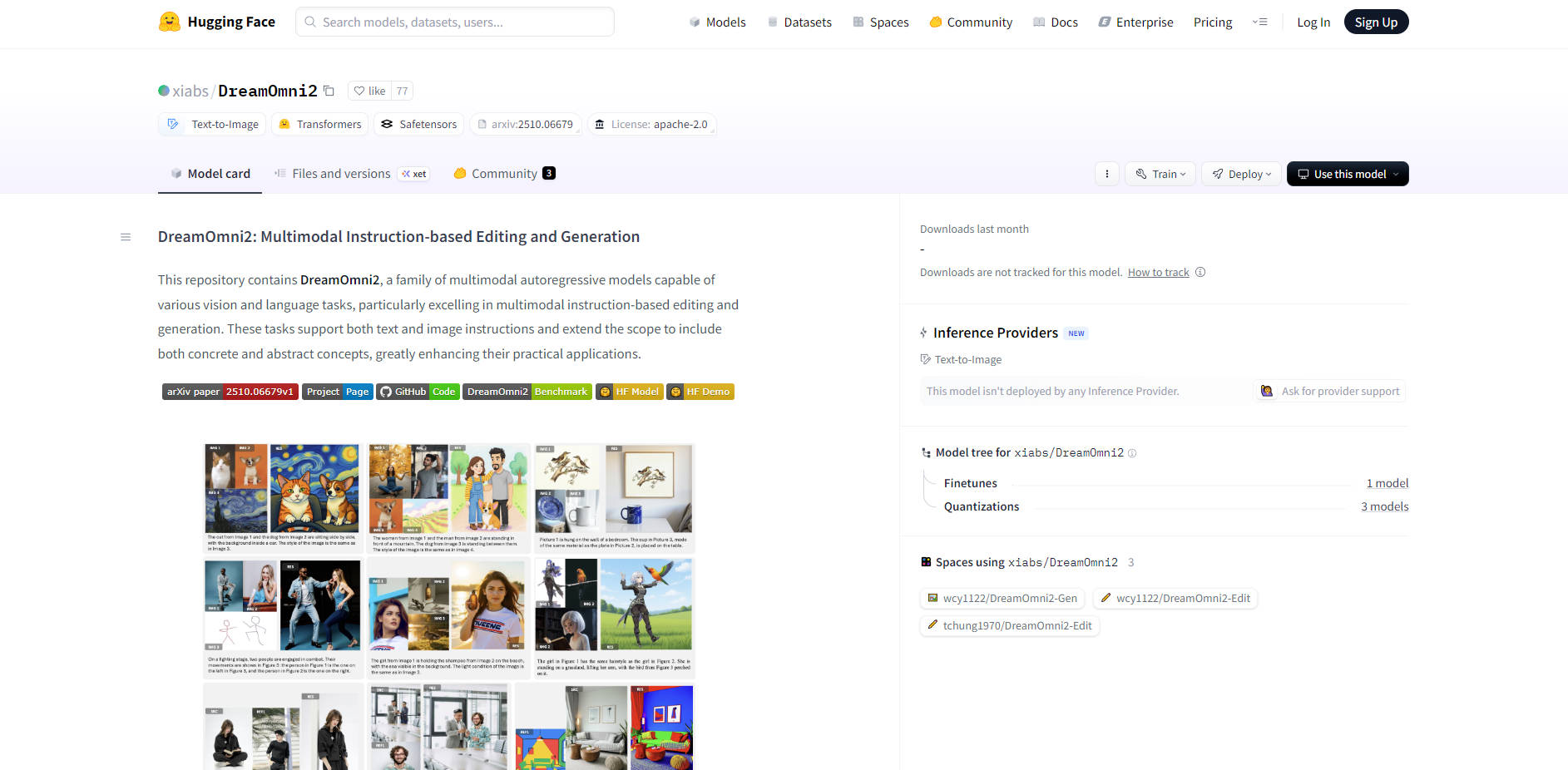
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 Alternativas
Más Alternativas-
Nano Banana: edición y creación de imágenes con IA, impulsada por Gemini 2.5 Flash. Logra transformaciones precisas basadas en texto y una consistencia de personajes inigualable, todo ello con gran rapidez.
-

OmniGen AI de BAAI es un modelo de última generación de texto a imagen. Marco unificado para una creación fluida. Transforma texto e imágenes. Ideal para artistas, mercadólogos e investigadores. ¡Potencia tu creatividad!
-

¡OLMo 2 32B: El LLM de código abierto que desafía a GPT-3.5! Código, datos y pesos gratuitos. Investiga, personaliza y crea una IA más inteligente.
-
Nano Banana redefine la edición de imágenes con IA. Obtén una coherencia de personajes inigualable y flujos de trabajo 10 veces más rápidos, todo ello potenciado por Gemini para una visión creativa de gran precisión.
-

Potencie la eficiencia de los LLM con DeepSeek-OCR. Comprima documentos visuales 10 veces con una precisión del 97%. Procese grandes volúmenes de datos para el entrenamiento de IA y la digitalización empresarial.