
What is DreamOmni2?
DreamOmni2 是一個先進的開源人工智慧圖像編輯模型,由香港科技大學 (HKUST) 賈佳亞團隊開發。它透過超越單純的實體物件識別,實現真正的多模態、多概念融合,從根本上解決了先前模型的侷限。這個平台賦能設計師、電商業者以及全球創意社群,僅需透過自然語言和參考圖像,即可執行專業級、高度精確的圖像編輯。
主要特色
DreamOmni2 的架構旨在為創意工作流程提供深度與彈性,實現了以往單憑語言難以完成的複雜編輯。
🎨 深度抽象概念理解
此模型不僅能識別實體物件,更能掌握諸如 風格、材質紋理、環境光照和陰影動態 等抽象屬性。這項能力確保,當您指示模型改變物件材質或調整場景氛圍時,生成的圖像仍能保持照片級的真實感和細膩度,展現了處理抽象屬性上的世代優勢。
🖼️ 協同多圖像融合
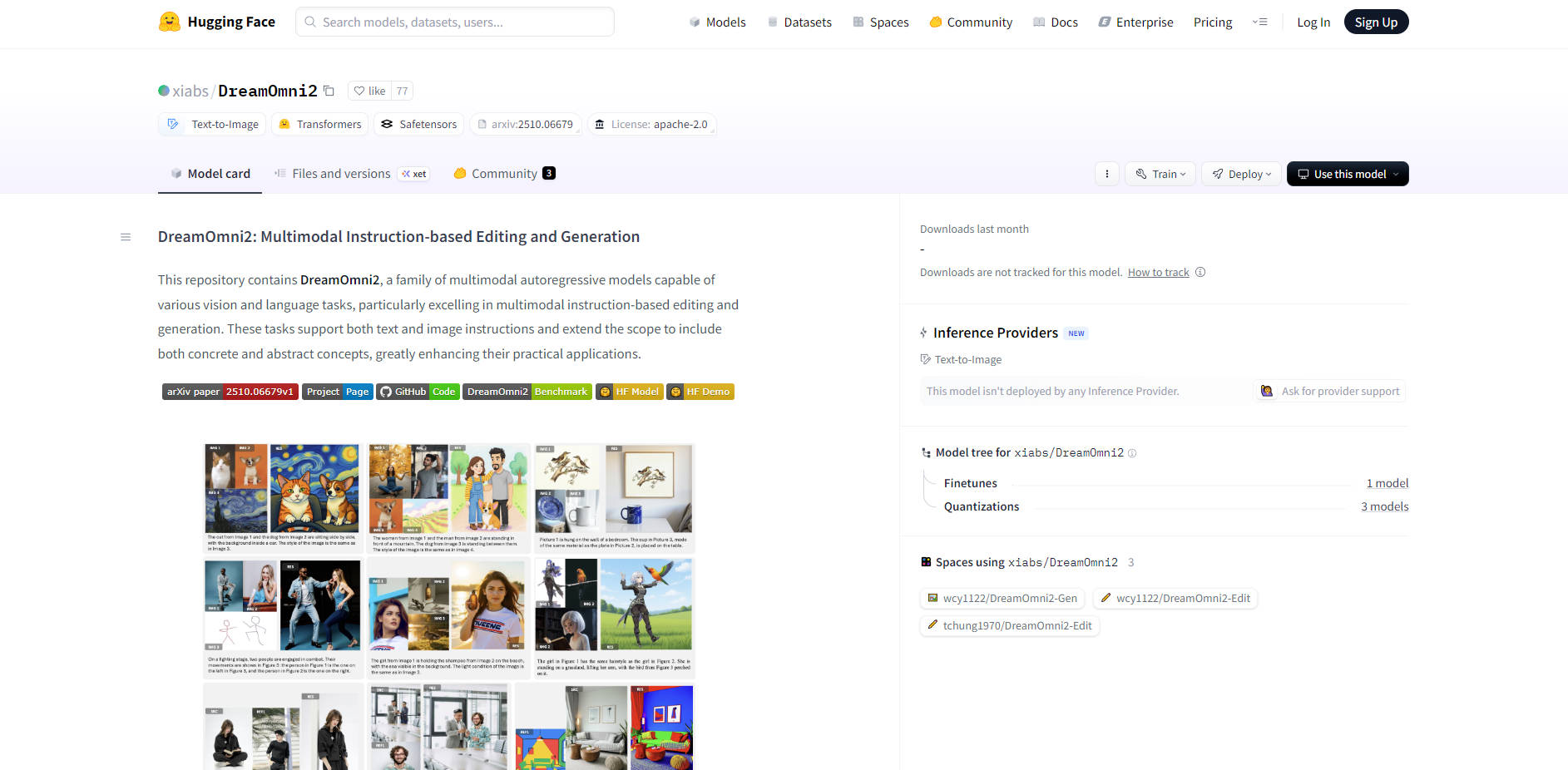
DreamOmni2 創新性地支援在單一指令中同時處理 2至4張參考圖像。這使得精確的元素融合成為可能,您可以將圖像A的物件、圖像B的風格以及圖像C的光照融合成一個連貫的輸出。此功能透過專有的索引編碼 (Index Encoding) 和位置編碼偏移 (Position Encoding Shift) 技術實現,能精確區分並融合概念,避免了像素混淆或生成偽影。
✍️ 專業自然語言操作
完全透過 精確的文字與圖像指令,實現專業級的圖像編輯。該平台運用視覺語言模型 (VLM) 組件,在執行前深度理解複雜的使用者意圖,解決了傳統工具難以處理模糊或多步驟指令的痛點。這消除了對手動、基於圖層操作的需求,例如物件替換或細緻風格遷移等任務。
💡 輕量化與開源可及性
作為一個免費、開源的模型,DreamOmni2 旨在提供廣泛的可及性。它保留了基礎模型的原始指令編輯和文字轉圖像功能,同時僅需 少於16GB的視訊記憶體 (VRAM)。這使得創作者和科技愛好者能夠在普通機器上本地運行強大的多模態編輯,或透過 Google Colab 等服務使用,大幅降低了進階人工智慧圖像創作的門檻。
應用案例
透過提供高精準度的多模態控制,DreamOmni2 革新了多個專業和創意工作流程。
加速電商與設計工作流程
Taobao 商家和設計師可以快速生成 服裝或產品變體,無需昂貴的重新拍攝。例如,商家可以使用一個新圖案的參考圖像和一個模特兒的參考圖像,指示 DreamOmni2 將圖案無縫應用於服裝,同時保留真實的布料褶皺、陰影和光照一致性。
複雜場景與角色整合
執行高度精細的角色替換,同時保持環境的真實感。您可以用新的參考圖像替換複雜場景中的角色,模型將精確地 遷移面部光照、保留背景細節,並複製細微元素,例如眼睛細節、頸部陰影和頭髮一致性,實現超越簡單語言描述的整合精準度。
進階多參考風格融合
設計師可以透過同時融合多個概念,實現複雜的視覺需求。例如,將第一張圖像中的特定物件(例如,一隻鸚鵡),讓它戴上第二張圖像中的特定配飾(一頂帽子),然後應用第三張參考圖像中獨特的藝術氛圍和色調(例如,紅藍對比光照),所有這些都透過一個簡潔的指令完成。
獨特優勢
DreamOmni2 透過在複雜、細微任務中的卓越性能,以及其多模態指令執行的創新方法,為專業創作者帶來了實質性利益,從而脫穎而出。
經證實的抽象處理卓越性
DreamOmni2 展現了超越 Google Nano Banana 和 OpenAI GPT-4o 等可比模型的經證實性能優勢,特別是在處理抽象概念和確保一致性方面。在基準測試中,DreamOmni2 的 生成準確度 比其他領先的開源模型高出 37%, 物件一致性 高出 29%,證明其在複雜編輯情境中提供高傳真、一致性結果的能力。
透過 VLM 聯合訓練實現深度指令理解
DreamOmni2 的核心競爭力在於其創新的架構,該架構將視覺語言模型 (VLM,例如 Qwen2.5-VL 7B) 與生成模型聯合訓練。VLM 充當智慧翻譯器,首先深度理解使用者多模態指令(文字 + 圖像)的完整上下文,然後再將其傳遞給生成模型執行。這種理解與生成的區分,大幅提升了模型執行高度精準、細緻處理的能力。
開源自由與社群焦點
作為一個來自頂尖大學研究團隊的開源專案,DreamOmni2 提供了完全的透明度和彈性。其輕量級部署要求(低於 16GB VRAM)確保全世界的研發人員、開發者和創作者都能夠存取並將這個強大的工具整合到他們的工作流程中,促進了創意社群內的快速迭代和二次開發。
結論
DreamOmni2 代表了開源人工智慧圖像編輯領域的一大進步,提供了多模態輸入的強大功能以及專業級成果所需的精確度。透過專注於抽象屬性理解和複雜的多參考融合,DreamOmni2 讓您以前所未有的輕鬆與精準度實現精密的創意願景。
立即探索開放專案頁面和程式碼儲存庫,體驗下一代自然語言圖像編輯。
常見問題
問:DreamOmni2 與標準的文字轉圖像模型有何不同? 答:傳統模型主要依賴文字提示,難以準確傳達抽象概念(例如特定光照或材質紋理),或精確結合來自多個圖像的元素。DreamOmni2 的多模態架構允許您在文字旁提供 1-4 張參考圖像,使模型能夠精確複製非語言屬性,並以高傳真度和一致性執行複雜的融合任務。
問:在本地執行 DreamOmni2 的最低硬體要求是什麼? 答:DreamOmni2 旨在輕量化且易於存取。它需要少於 16GB 的視訊記憶體 (VRAM),這意味著它可以在許多普通的本地機器上有效運行,或透過像 Google Colab 這樣的雲端運算環境存取,而無需高階、專業的硬體配置。
問:DreamOmni2 是由誰開發的,以及其基準性能為何重要? 答:DreamOmni2 是由香港科技大學 (HKUST) 賈佳亞團隊開發的。其基準性能之所以重要,是因為該團隊創建了一個新的、全面的測試集(「DreamOmni2 基準」),涵蓋了抽象屬性和具體物件編輯。在這些嚴格的測試中,與 Google Nano Banana 和 GPT-4o 等已建立的閉源模型相比,DreamOmni2 在抽象概念處理方面展現了更高的準確性和一致性。
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 替代方案
更多 替代方案-
Nano Banana: 搭載 Gemini 2.5 Flash,提供 AI 圖像編輯與創作功能。快速實現精準的文字指令轉換與無與倫比的角色一致性。
-

由 BAAI 研發的 OmniGen AI 是一款尖端的文字轉圖像模型。統一的框架,實現無縫創作。轉換文字和圖像。非常適合藝術家、行銷人員和研究人員。釋放您的創意!
-

-
Nano Banana 重新定義了 AI 圖像編輯的標準,帶來無與倫比的角色一致性,並讓工作流程效率提升 10 倍。這一切都由 Gemini 提供強大技術支援,助您精準實現每個創意願景。
-

運用 DeepSeek-OCR,大幅提升大型語言模型 (LLM) 的運作效率。將視覺文件壓縮達十倍,並維持高達 97% 的準確性。協助處理海量數據,為人工智慧 (AI) 訓練及企業數位轉型提供強大支援。