
What is DreamOmni2?
DreamOmni2は、香港科技大学(HKUST)Jia Jiayaチームによって開発された、先進的なオープンソースのAI画像編集モデルです。従来のモデルが抱えていた単純な物理オブジェクト認識という限界を超え、真のマルチモーダル・マルチコンセプト融合を実現することで、その課題を根本的に解決します。このプラットフォームは、デザイナー、Eコマース事業者、そして世界中のクリエイティブコミュニティに対し、自然言語と参照画像のみを用いて、プロフェッショナルレベルの非常に精密な画像編集を行う能力を提供します。
主な特徴
DreamOmni2のアーキテクチャは、クリエイティブなワークフローに深みと柔軟性をもたらすよう設計されており、これまで言語のみでは不可能だった複雑な編集を実現します。
🎨 深層的な抽象概念の理解
このモデルは、物理的な実体だけでなく、 スタイル、素材の質感、環境光、影の動きといった抽象的な属性も把握します。この能力により、オブジェクトの素材を変更したり、シーンの雰囲気を調整するようモデルに指示した場合でも、生成される画像は写真のような一貫性とニュアンスを維持し、抽象属性の処理において世代的な優位性を示します。
🖼️ 協調的な複数画像融合
DreamOmni2は、単一の指示内で 2〜4枚の参照画像を同時に サポートするという革新的な機能を備えています。これにより、画像Aのオブジェクト、画像Bのスタイル、画像Cの照明を組み合わせて、単一のまとまった出力へと精密に要素を融合させることが可能になります。これは、独自のIndex EncodingおよびPosition Encoding Shift技術によって実現されており、ピクセルの混同やアーティファクトの生成なしに、コンセプトを正確に区別し融合させます。
✍️ プロフェッショナルな自然言語操作
精密なテキストと画像指示のみによって、プロフェッショナルレベルの画像編集を実現します。このプラットフォームは、Visual Language Model(VLM)コンポーネントを活用し、実行前にユーザーの複雑な意図を深く理解することで、曖昧な指示や多段階の要求に対応しきれなかった従来のツールの課題を解決します。これにより、オブジェクトの置き換えや詳細なスタイル移行といったタスクにおいて、手作業によるレイヤーベースの操作は不要になります。
💡 軽量かつオープンソースのアクセシビリティ
無料のオープンソースモデルであるDreamOmni2は、幅広いアクセシビリティのために設計されています。ベースモデルの持つオリジナルの指示編集機能とテキストから画像への生成機能は維持しつつ、必要なVRAMは 16GB未満 です。これにより、クリエイターや技術愛好家は、一般的なマシン上で強力なマルチモーダル編集をローカルで実行したり、Google Colabなどのサービスを通じて利用したりすることができ、高度なAI画像作成への参入障壁を大幅に下げます。
活用事例
DreamOmni2は、高精度なマルチモーダル制御を提供することで、複数のプロフェッショナルおよびクリエイティブなワークフローを変革します。
Eコマースとデザインワークフローの加速
淘宝(タオバオ)の事業者やデザイナーは、高価な再撮影なしに 衣料品や製品のバリエーション を迅速に生成できます。例えば、事業者は新しいパターンの参照画像とモデルの参照画像を使用し、DreamOmni2に、リアルな生地のしわ、影、照明の一貫性を保ちながら、そのパターンを衣料品にシームレスに適用するよう指示できます。
複雑なシーンとキャラクターの統合
環境のリアリズムを維持しながら、非常に詳細なキャラクター置き換えを実行します。複雑なシーンのキャラクターを新しい参照画像で置き換えることができ、モデルは正確に 顔の照明を移行させ、背景の細部を保持し、目の細部、首の影、髪の一貫性といった微妙な要素を再現 します。これにより、単純な言語記述を超える統合精度を実現します。
高度な複数参照スタイルブレンド
デザイナーは、複数のコンセプトを同時にブレンドすることで、複雑な視覚的要件を満たすことができます。例えば、ある画像から特定のオブジェクト(例:オウム)、別の画像から特定のアクセサリー(例:帽子)を組み合わせ、さらに3つ目の参照画像から独自の芸術的な雰囲気と色調(例:赤と青の対比照明)を適用するといったことが、すべて単一の簡潔な指示で行えます。
独自の利点
DreamOmni2は、複雑でニュアンスの要求されるタスクにおける優れたパフォーマンスと、マルチモーダルな指示実行への革新的なアプローチにより、他のモデルとの差別化を図り、本格的なクリエイターに具体的なメリットを提供します。
抽象処理における実証済みの優位性
DreamOmni2は、GoogleのNano BananaやOpenAIのGPT-4oを含む競合モデルと比較して、特に抽象概念の処理と一貫性の確保において、実証可能なパフォーマンス上の優位性を示しています。ベンチマークテストでは、DreamOmni2は他の主要なオープンソースモデルと比較して 37%高い生成精度 と 29%高いオブジェクト一貫性 を達成し、複雑な編集シナリオにおいて高忠実度かつ一貫性のある結果を提供する能力を証明しました。
VLM共同学習による深層的な指示理解
DreamOmni2の核となる競争力は、Generative ModelとVisual Language Model(VLM、例:Qwen2.5-VL 7B)を共同で学習させる革新的なアーキテクチャにあります。VLMは、インテリジェントな翻訳者として機能し、ユーザーのマルチモーダルな指示(テキスト+画像)の完全なコンテキストを深く理解してから、実行のためにGenerative Modelに渡します。この「理解」と「生成」の分離により、モデルは非常に正確で詳細な処理を実行する能力を大幅に向上させます。
オープンソースの自由とコミュニティへの貢献
主要な大学の研究チームによるオープンソースプロジェクトとして、DreamOmni2は完全な透明性と柔軟性を提供します。その軽量なデプロイ要件(16GB未満のVRAM)により、世界中の研究者、開発者、クリエイターがこの強力なツールにアクセスし、ワークフローに統合することが可能となり、クリエイティブコミュニティ内での迅速なイテレーションと二次開発を促進します。
結論
DreamOmni2は、オープンソースAI画像編集における大きな進歩を意味し、マルチモーダル入力の強力な機能と、プロフェッショナルレベルの結果に必要な精度を提供します。抽象属性の理解と複雑な複数参照融合に焦点を当てることで、DreamOmni2は、これまでにない容易さと正確さで洗練されたクリエイティブなビジョンを実現する力をあなたに与えます。
今すぐオープンプロジェクトページとコードリポジトリをご覧いただき、次世代の自然言語画像編集を体験してください。
よくある質問
Q: DreamOmni2は標準的なテキストから画像生成モデルと何が異なりますか? A: 従来のモデルは主にテキストプロンプトに依存しており、特定の照明や素材の質感といった抽象概念を正確に伝えたり、複数の画像からの要素を精密に組み合わせることに苦慮していました。DreamOmni2のマルチモーダルアーキテクチャでは、テキストとともに1〜4枚の参照画像を提供できるため、非言語的な属性を正確に再現し、複雑な融合タスクを高忠実度かつ一貫性をもって実行することが可能です。
Q: DreamOmni2をローカルで実行するための最小ハードウェア要件は何ですか? A: DreamOmni2は、軽量かつアクセシブルに設計されています。16GB未満のVRAMで動作するため、ハイエンドな専門的ハードウェア構成を必要とせず、多くの一般的なローカルマシンで効果的に実行したり、Google Colabなどのクラウドコンピューティング環境を通じてアクセスしたりすることができます。
Q: DreamOmni2は誰が開発し、そのベンチマーク性能がなぜ重要なのでしょうか? A: DreamOmni2は、香港科技大学(HKUST)のJia Jiayaチームによって開発されました。そのベンチマーク性能が重要である理由は、チームが抽象属性と具体的なオブジェクト編集を網羅する新しい包括的なテストセット(「DreamOmni2ベンチマーク」)を作成したためです。これらの厳密なテストにおいて、DreamOmni2は、Google Nano BananaやGPT-4oといった確立されたクローズドソースモデルと比較して、抽象概念処理においてより高い精度と一貫性を示しました。
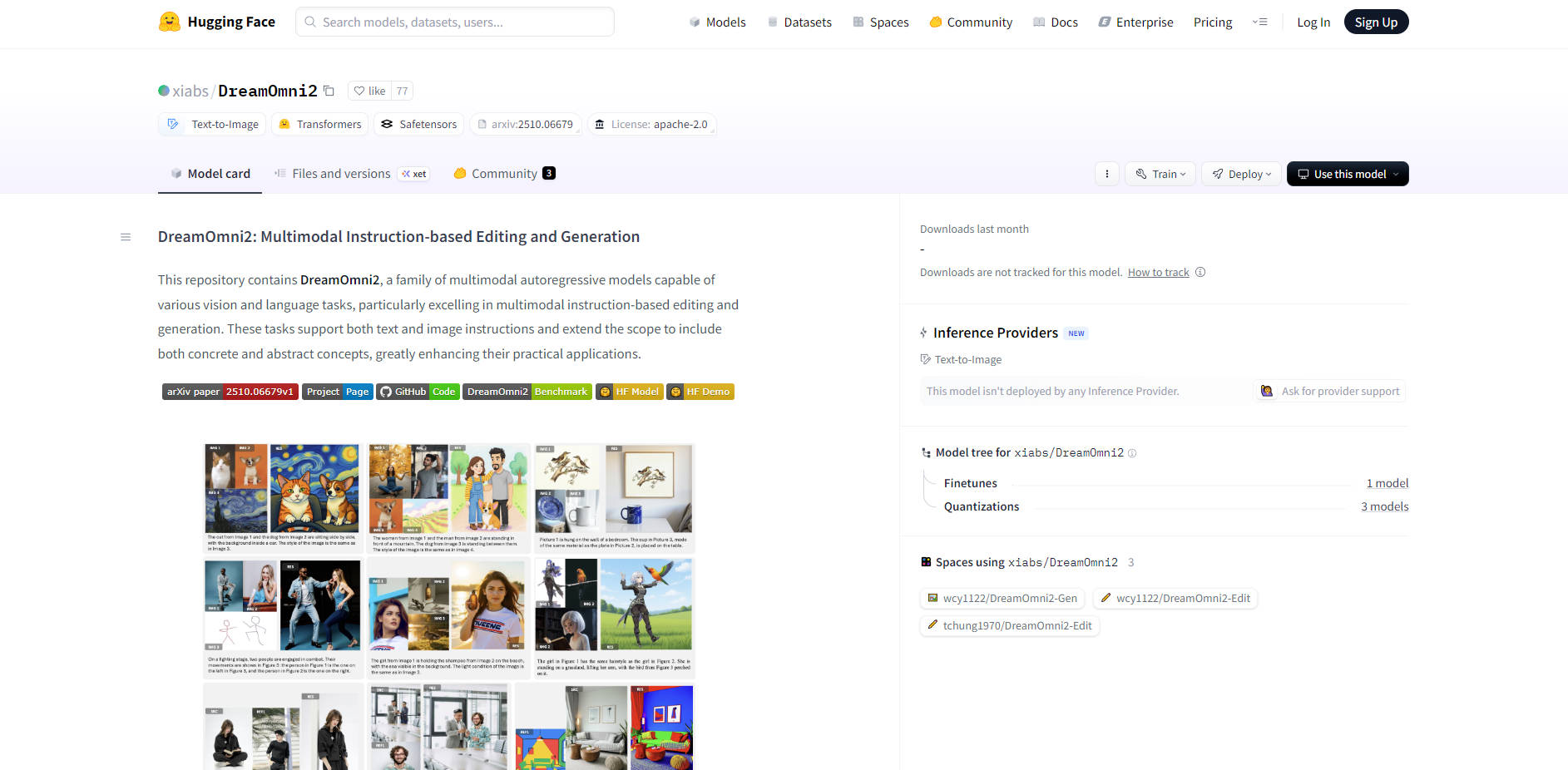
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 代替ソフト
もっと見る 代替ソフト-
Nano Banana: Gemini 2.5 Flashを活用したAI画像編集・生成。テキスト指示による精密な変形と、比類なきキャラクターの一貫性を高速に実現。
-

BAAI製のOmniGen AIは、最先端のテキストから画像生成モデルです。シームレスな創作のための統合フレームワーク。テキストと画像を変換します。アーティスト、マーケター、研究者にとって理想的なツールです。創造性を解き放ちましょう!
-

OLMo 2 32B:GPT-3.5に匹敵するオープンソースLLM!コード、データ、重みを無償で提供。研究、カスタマイズ、そしてよりスマートなAIの構築に。
-
Nano BananaがAI画像編集を再定義します。Geminiを搭載し、比類ないキャラクターの一貫性と、精密なクリエイティブビジョンを実現する10倍高速なワークフローを提供します。
-

DeepSeek-OCR で LLM の効率を飛躍的に向上させます。 97%の高精度を維持しつつ、視覚文書のデータ量を10分の1に圧縮。 AIトレーニングや企業のDX(デジタルトランスフォーメーション)に向けた膨大なデータ処理を実現します。