
What is DreamOmni2?
DreamOmni2 — это передовая модель для редактирования изображений на основе ИИ с открытым исходным кодом, разработанная командой Цзя Цзяя из Гонконгского университета науки и технологий (HKUST). Она кардинально решает ограничения предыдущих моделей, выходя за рамки простого распознавания физических объектов для достижения истинной мультимодальной, многоконцептуальной интеграции. Эта платформа предоставляет дизайнерам, продавцам электронной коммерции и мировому творческому сообществу возможность выполнять профессиональное, высокоточное редактирование изображений, используя только естественный язык и эталонные изображения.
Ключевые особенности
Архитектура DreamOmni2 разработана для обеспечения глубины и гибкости в творческих рабочих процессах, позволяя выполнять сложные изменения, которые ранее были невозможны только с помощью языка.
🎨 Глубокое понимание абстрактных концепций
Модель распознает не только физические сущности, но и улавливает абстрактные атрибуты, такие как стиль, текстура материала, окружающее освещение и динамика теней. Эта возможность гарантирует, что при указании модели изменить материал объекта или адаптировать настроение сцены, полученное изображение сохраняет фотореалистичную согласованность и нюансы, демонстрируя значительное превосходство в обработке абстрактных атрибутов.
🖼️ Коллективное слияние нескольких изображений
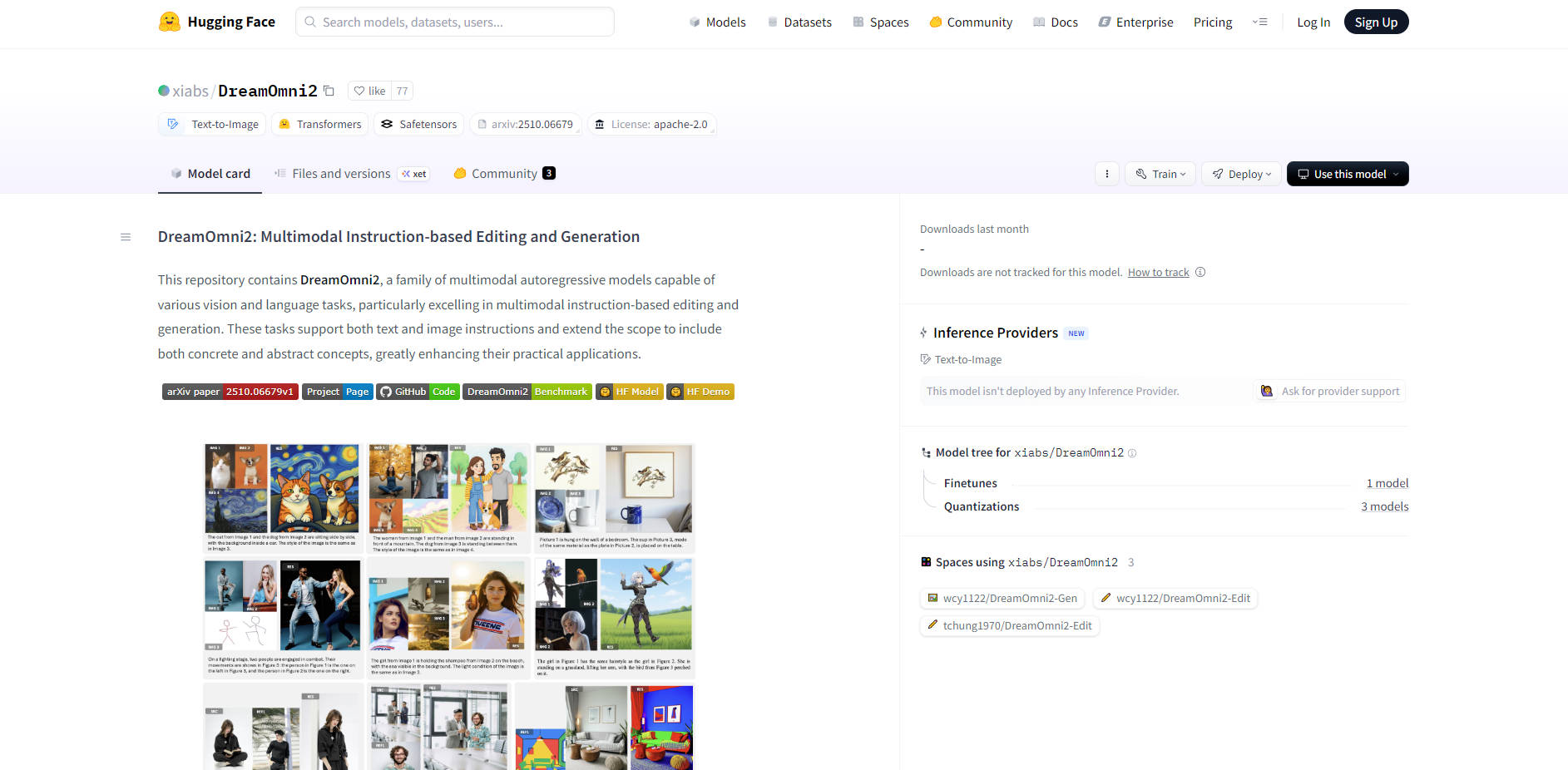
DreamOmni2 инновационно поддерживает от 2 до 4 эталонных изображений одновременно в рамках одной инструкции. Это позволяет осуществлять точное слияние элементов, позволяя объединить объект с Изображения A, стиль с Изображения B и освещение с Изображения C в единый, связный результат. Это достигается благодаря запатентованной технологии Index Encoding и Position Encoding Shift, которая точно различает и объединяет концепции без путаницы пикселей или генерации артефактов.
✍️ Профессиональная работа с естественным языком
Достигайте профессионального уровня редактирования изображений исключительно с помощью точных текстовых и графических инструкций. Платформа использует компонент Visual Language Model (VLM) для глубокого понимания сложных намерений пользователя перед выполнением, решая болевые точки традиционных инструментов, которые сталкиваются с неясными или многошаговыми запросами. Это исключает необходимость ручного, послойного манипулирования для таких задач, как замена объектов или детальная миграция стиля.
💡 Легковесность и доступность с открытым исходным кодом
Будучи бесплатной моделью с открытым исходным кодом, DreamOmni2 разработана для широкой доступности. Она сохраняет оригинальные возможности своего базового шаблона по редактированию инструкций и преобразованию текста в изображение, при этом требуя менее 16 ГБ видеопамяти (VRAM). Это позволяет создателям и техническим энтузиастам запускать мощное мультимодальное редактирование локально на обычных машинах или через такие сервисы, как Google Colab, значительно снижая порог вхождения для продвинутого создания изображений с помощью ИИ.
Примеры использования
DreamOmni2 преобразует ряд профессиональных и творческих рабочих процессов, обеспечивая высокоточный, мультимодальный контроль.
Ускорение рабочих процессов в электронной коммерции и дизайне
Продавцы Taobao и дизайнеры могут быстро генерировать вариации одежды или товаров без дорогостоящих повторных съемок. Например, продавец может использовать эталонное изображение нового узора и эталонное изображение модели, поручив DreamOmni2 плавно нанести узор на одежду, сохраняя при этом реалистичные складки ткани, тени и согласованность освещения.
Интеграция сложных сцен и персонажей
Выполняйте высокодетализированную замену персонажей, сохраняя при этом реализм окружающей среды. Вы можете заменить персонажа в сложной сцене новым эталонным изображением, и модель точно перенесет освещение лица, сохранит детали фона и воспроизведет тонкие элементы, такие как детали глаз, тени на шее и согласованность волос, достигая точности интеграции, превосходящей простые языковые описания.
Расширенное смешивание стилей из нескольких источников
Дизайнеры могут реализовать сложные визуальные запросы, одновременно смешивая несколько концепций. Например, объедините конкретный объект (например, попугая) из одного изображения, наденьте на него конкретный аксессуар (шляпу) со второго изображения, а затем примените уникальную художественную атмосферу и тон (например, красно-синее контрастное освещение) с третьего эталонного изображения — и все это с помощью одной, лаконичной инструкции.
Уникальные преимущества
DreamOmni2 выделяется превосходной производительностью в сложных, тонких задачах и инновационным подходом к выполнению мультимодальных инструкций, предоставляя ощутимые преимущества серьезным творцам.
Подтвержденное превосходство в обработке абстрактных концепций
DreamOmni2 демонстрирует подтвержденное превосходство в производительности над сопоставимыми моделями, включая Google Nano Banana и GPT-4o от OpenAI, особенно при работе с абстрактными концепциями и обеспечении согласованности. В контрольных тестах DreamOmni2 достигла на 37% более высокой точности генерации и на 29% более высокой согласованности объектов по сравнению с другими ведущими моделями с открытым исходным кодом, доказывая свою способность обеспечивать высокоточное и согласованное качество результатов в сложных сценариях редактирования.
Глубокое понимание инструкций через совместное обучение VLM
Основная конкурентоспособность DreamOmni2 заключается в ее инновационной архитектуре, которая совместно обучает Visual Language Model (VLM, например, Qwen2.5-VL 7B) с генеративной моделью. VLM выступает в роли интеллектуального переводчика, сначала глубоко понимая полный контекст мультимодальной инструкции пользователя (текст + изображения), прежде чем передать ее генеративной модели для выполнения. Такое разделение понимания и генерации значительно повышает способность модели выполнять высокоточное, детализированное редактирование.
Свобода открытого исходного кода и ориентация на сообщество
Будучи проектом с открытым исходным кодом от крупной университетской исследовательской команды, DreamOmni2 предлагает полную прозрачность и гибкость. Ее легкие требования к развертыванию (менее 16 ГБ VRAM) гарантируют, что исследователи, разработчики и создатели по всему миру могут получить доступ к этому мощному инструменту и интегрировать его в свои рабочие процессы, способствуя быстрой итерации и вторичному развитию в рамках творческого сообщества.
Заключение
DreamOmni2 представляет собой значительный шаг вперед в редактировании изображений на основе ИИ с открытым исходным кодом, предлагая мощь мультимодального ввода и точность, необходимую для результатов профессионального уровня. Сосредоточившись на понимании абстрактных атрибутов и сложном слиянии из нескольких источников, DreamOmni2 позволяет воплощать сложные творческие замыслы с беспрецедентной легкостью и точностью.
Изучите открытую страницу проекта и репозиторий кода сегодня, чтобы испытать новое поколение редактирования изображений на естественном языке.
Часто задаваемые вопросы
В: Чем DreamOmni2 отличается от стандартных моделей преобразования текста в изображение? О: Традиционные модели в основном полагаются на текстовые подсказки, которые с трудом точно передают абстрактные концепции (например, специфическое освещение или текстуру материала) или точно объединяют элементы из нескольких изображений. Мультимодальная архитектура DreamOmni2 позволяет вам предоставлять от 1 до 4 эталонных изображений наряду с текстом, что дает модели возможность точно воспроизводить невербальные атрибуты и выполнять сложные задачи слияния с высокой точностью и согласованностью.
В: Каковы минимальные аппаратные требования для локального запуска DreamOmni2? О: DreamOmni2 разработан как легкий и доступный инструмент. Он требует менее 16 ГБ VRAM, что означает, что его можно эффективно запускать на многих обычных локальных машинах или получать к нему доступ через облачные вычислительные среды, такие как Google Colab, без необходимости в высокопроизводительных, специализированных аппаратных конфигурациях.
В: Кто разработал DreamOmni2, и почему его производительность в бенчмарках так значима? О: DreamOmni2 был разработан командой Цзя Цзяя из Гонконгского университета науки и технологий (HKUST). Его производительность в бенчмарках значима, потому что команда создала новый, всеобъемлющий тестовый набор ("бенчмарк DreamOmni2"), охватывающий абстрактные атрибуты и редактирование конкретных объектов. В этих строгих тестах DreamOmni2 продемонстрировал более высокую точность и согласованность в обработке абстрактных концепций по сравнению с устоявшимися закрытыми моделями, такими как Google Nano Banana и GPT-4o.
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 Альтернативи
Больше Альтернативи-
Nano Banana: Редактирование и создание изображений с ИИ на базе Gemini 2.5 Flash. Достигайте точных трансформаций по текстовому описанию и беспрецедентного единообразия персонажей — быстро.
-

OmniGen AI от BAAI - это передовая модель преобразования текста в изображение. Единая платформа для бесшовного создания. Преобразует текст и изображения. Идеально подходит для художников, маркетологов и исследователей. Дайте волю своему творчеству!
-

OLMo 2 32B: LLM с открытым исходным кодом, способная потягаться с GPT-3.5! Бесплатный код, данные и веса. Исследуйте, настраивайте и создавайте более совершенный ИИ.
-
Nano Banana переосмысливает редактирование изображений с ИИ. Получите непревзойденную согласованность персонажей и в 10 раз ускоренные рабочие процессы благодаря Gemini для точного воплощения творческого замысла.
-

Повысьте эффективность LLM с помощью DeepSeek-OCR. Сжимайте визуальные документы в 10 раз с точностью 97%. Обрабатывайте огромные объемы данных для обучения ИИ и цифровизации предприятий.