
What is DreamOmni2?
DreamOmni2 是由香港科技大学(HKUST)贾佳亚团队开发的一款先进开源AI图像编辑模型。它从根本上解决了以往模型的局限,不再局限于简单的物理对象识别,而是实现了真正的多模态、多概念融合。该平台赋能设计师、电商商家和全球创意社区,仅凭自然语言和参考图像,即可实现专业级、高精度的图像编辑。
主要特性
DreamOmni2 的架构旨在为创意工作流程提供深度和灵活性,从而能够实现仅凭语言指令无法完成的复杂编辑。
🎨 深入理解抽象概念
该模型不仅识别物理实体,还能理解抽象属性,例如 风格、材质纹理、环境光照和阴影动态。这种能力确保,当您指示模型改变物体的材质或调整场景氛围时,生成的图像仍能保持逼真的连贯性和微妙的细节,这展示了其在处理抽象属性方面的代际领先优势。
🖼️ 协同多图像融合
DreamOmni2 创新性地支持在单个指令中同时使用 2 到 4 张参考图像。这实现了精确的元素融合,让您可以将图像A中的物体、图像B中的风格和图像C中的光照融合到一个连贯的输出中。这是通过专有的 Index Encoding 和 Position Encoding Shift 技术实现的,该技术能准确区分和融合概念,避免像素混淆或伪影生成。
✍️ 专业级自然语言操作
完全通过 精确的文本和图像指令 实现专业级图像编辑。该平台利用视觉语言模型(VLM)组件,在执行前深度理解复杂的`用户意图`,解决了传统工具难以处理模糊或多步骤需求的痛点。这消除了针对物体替换或详细风格迁移等任务进行手动、基于图层操作的需要。
💡 轻量级与开源可及性
作为一款免费的开源模型,DreamOmni2 旨在实现广泛的可及性。它保留了其基础模型的原始指令编辑和文本到图像功能,同时仅需要 不到 16GB 的显存。这使得创作者和技术爱好者能够在普通机器上本地运行强大的多模态编辑,或通过 Google Colab 等服务使用,显著降低了高级 AI 图像创作的门槛。
应用场景
DreamOmni2 通过提供高精度、多模态的控制,变革了多个专业和创意工作流程。
加速电商和设计工作流程
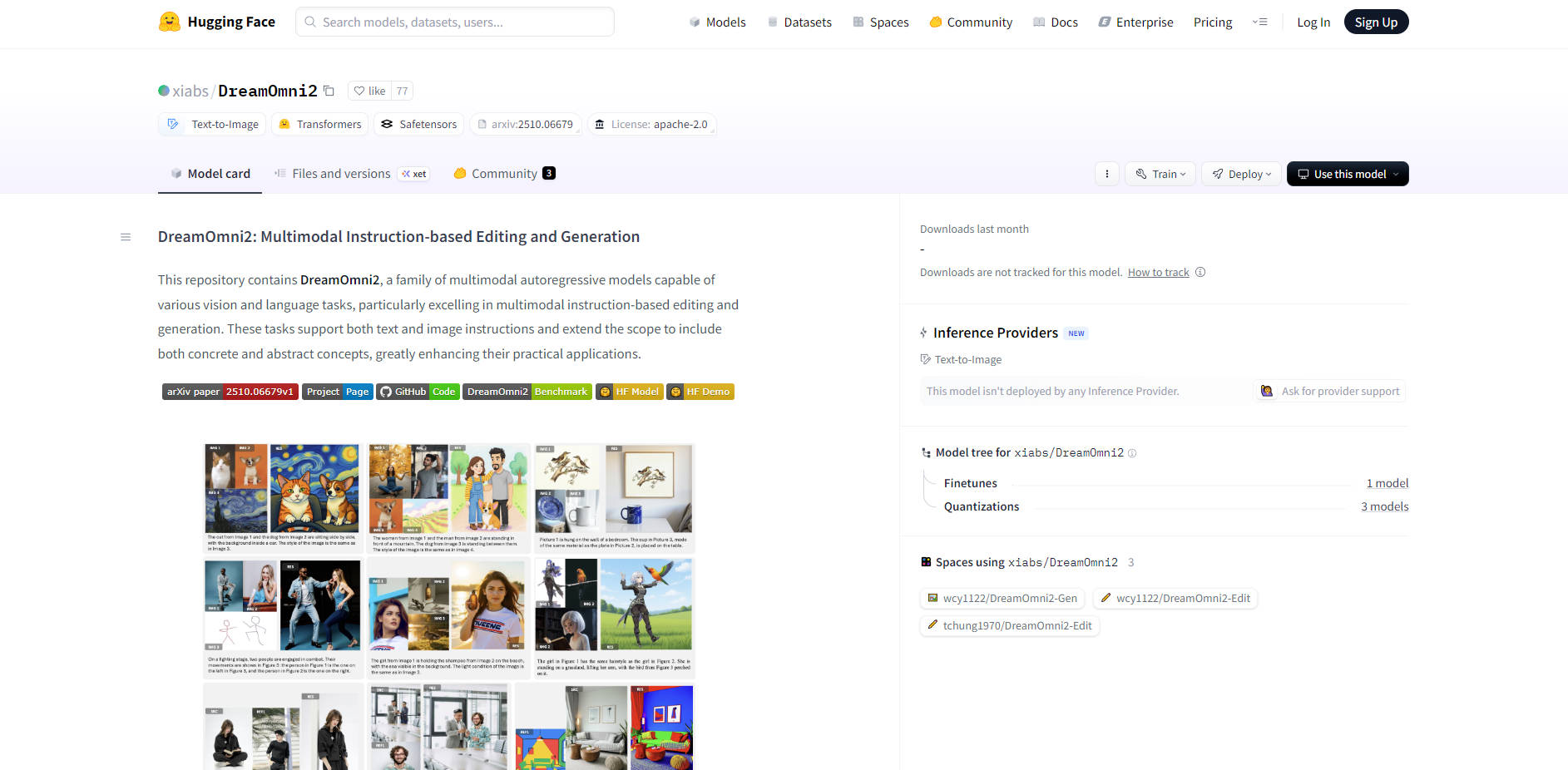
淘宝商家和设计师可以快速生成 服装或产品变体,而无需昂贵的重新拍摄。例如,商家可以使用新图案的参考图像和模特的参考图像,指示 DreamOmni2 将图案无缝应用到服装上,同时保留逼真的布料褶皱、阴影和光照一致性。
复杂场景与角色融合
在保持环境真实感的同时,执行高度详细的角色替换。您可以用新的参考图像替换复杂场景中的角色,模型将精确地 迁移面部光照、保留背景细节,并复制细微元素,例如眼睛细节、颈部阴影和头发一致性,从而实现超越简单语言描述的融合精度。
高级多参考风格融合
设计师可以通过同时融合多个概念来满足复杂的视觉需求。例如,可以从一张图像中选取一个特定物体(例如一只鹦鹉),让它佩戴第二张图像中的特定配饰(一顶帽子),然后应用第三张参考图像中独特的艺术氛围和色调(例如红蓝对比光照),所有这些都可以通过一条简洁的指令完成。
独特优势
DreamOmni2 凭借其在复杂细致任务中的卓越性能和创新的多模态指令执行方法脱颖而出,为认真的创作者带来了实实在在的利益。
抽象处理的经验证卓越性
DreamOmni2 在处理抽象概念和确保一致性方面,相较于包括 Google Nano Banana 和 GPT-4o 在内的同类模型,展现出可验证的性能优势。在基准测试中,DreamOmni2 的 生成精度比其他领先的开源模型高出 37%, 物体一致性高出 29%,这证明了它在复杂编辑场景中提供高保真、一致结果的能力。
通过 VLM 联合训练实现深度指令理解
DreamOmni2 的核心竞争力在于其创新架构,它将视觉语言模型(VLM,例如 Qwen2.5-VL 7B)与生成模型进行联合训练。VLM 充当智能翻译器,首先深入理解用户多模态指令(文本 + 图像)的完整上下文,然后将其传递给生成模型执行。这种理解与生成的分离显著增强了模型执行高精度、详细处理的能力。
开源自由与社区导向
作为一项来自顶尖大学研究团队的开源项目,DreamOmni2 提供了完全的透明度和灵活性。其轻量级的部署要求(低于 16GB 显存)确保了全球的研究人员、开发者和创作者都能访问并将这一强大工具集成到他们的工作流程中,从而促进创意社区内的快速迭代和二次开发。
总结
DreamOmni2 代表着开源 AI 图像编辑领域的一个重大进步,它提供了多模态输入的强大功能以及专业级成果所需的精度。通过专注于抽象属性理解和复杂的多参考融合,DreamOmni2 赋能您以前所未有的便捷性和准确性实现复杂的创意构想。
立即访问开源项目页面和代码仓库,体验下一代自然语言图像编辑技术。
常见问题
问:DreamOmni2 与标准文本到图像模型有何不同? 答:传统模型主要依赖文本提示,它们难以准确传达抽象概念(例如特定的光照或材质纹理),也难以精确组合来自多张图像的元素。DreamOmni2 的多模态架构允许您在文本之外提供 1-4 张参考图像,使模型能够精确复制非语言属性,并以高保真度和一致性执行复杂的融合任务。
问:在本地运行 DreamOmni2 的最低硬件要求是什么? 答:DreamOmni2 设计为轻量级且易于访问。它需要不到 16GB 的显存,这意味着它可以在许多普通的本地机器上有效运行,或通过 Google Colab 等云计算环境访问,而无需高端、专业的硬件配置。
问:DreamOmni2 由谁开发,其基准性能为何如此重要? 答:DreamOmni2 由香港科技大学(HKUST)贾佳亚团队开发。其基准性能之所以重要,是因为该团队创建了一个新的、全面的测试集(“DreamOmni2 基准”),涵盖了抽象属性和具体物体编辑。在这些严苛的测试中,与 Google Nano Banana 和 GPT-4o 等成熟的闭源模型相比,DreamOmni2 在抽象概念处理方面展现出更高的准确性和一致性。
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 替代方案
更多 替代方案-
Nano Banana: 搭载 Gemini 2.5 Flash 的 AI 图像编辑与创作。实现精准的文本指令转换,以及无与伦比的形象一致性,极速达成。
-

BAAI 推出的 OmniGen AI 是一款尖端的文本到图像模型。它提供统一的框架,实现无缝创作。可以将文本和图像进行转换。非常适合艺术家、营销人员和研究人员使用。释放您的创造力!
-

-
Nano Banana 彻底革新AI图像编辑,助您实现无与伦比的角色一致性,并将工作流效率提升10倍,这一切都得益于Gemini的强大支持,精准呈现您的创意构想。
-

DeepSeek-OCR 助力 LLM 效率跃升。视觉文档可实现 10 倍压缩,准确率高达 97%。处理海量数据,赋能 AI 训练与企业数字化。