
What is DreamOmni2?
DreamOmni2 est un modèle d'édition d'images par IA avancé et open source, développé par l'équipe Jia Jiaya de l'Université des Sciences et Technologies de Hong Kong (HKUST). Il résout fondamentalement les limitations des modèles précédents en allant au-delà de la simple reconnaissance d'objets physiques pour réaliser une véritable fusion multimodale et multi-conceptuelle. Cette plateforme permet aux designers, aux commerçants en ligne et à la communauté créative mondiale d'effectuer des modifications d'images de qualité professionnelle et d'une grande précision, en utilisant uniquement le langage naturel et des images de référence.
Caractéristiques Principales
L'architecture de DreamOmni2 est conçue pour offrir profondeur et flexibilité aux processus créatifs, permettant des modifications complexes qui étaient auparavant impossibles avec le langage seul.
🎨 Compréhension Approfondie des Concepts Abstraits
Le modèle reconnaît non seulement les entités physiques, mais saisit également des attributs abstraits tels que le style, la texture des matériaux, la lumière ambiante et la dynamique des ombres. Cette capacité garantit que, lorsque vous donnez au modèle l'instruction de modifier le matériau d'un objet ou d'adapter l'ambiance d'une scène, l'image résultante conserve une cohérence et une nuance photoréalistes, démontrant un avantage générationnel dans la gestion des attributs abstraits.
🖼️ Fusion Collaborative Multi-Images
DreamOmni2 prend en charge de manière innovante 2 à 4 images de référence simultanément au sein d'une seule instruction. Cela permet une fusion précise des éléments, vous permettant de combiner un objet de l'Image A, un style de l'Image B et l'éclairage de l'Image C en un seul rendu cohérent. Ceci est rendu possible grâce à une technologie propriétaire d'encodage d'index et de décalage d'encodage de position, qui distingue et fusionne avec précision les concepts sans confusion de pixels ni génération d'artefacts.
✍️ Opération Professionnelle en Langage Naturel
Réalisez des retouches d'images de qualité professionnelle entièrement grâce à des instructions textuelles et visuelles précises. La plateforme utilise un composant de Modèle de Langage Visuel (VLM) pour comprendre en profondeur l'intention complexe de l'utilisateur avant l'exécution, résolvant les problèmes rencontrés par les outils traditionnels qui peinent avec des demandes ambiguës ou en plusieurs étapes. Ceci élimine le besoin de manipulation manuelle, basée sur des calques, pour des tâches telles que le remplacement d'objets ou la migration détaillée de styles.
💡 Légèreté et Accessibilité Open Source
En tant que modèle gratuit et open source, DreamOmni2 est conçu pour une large accessibilité. Il conserve les capacités d'édition d'instructions et de texte-image de son modèle de base tout en ne nécessitant moins de 16 Go de VRAM. Cela permet aux créateurs et aux passionnés de technologie d'exécuter des modifications multimodales puissantes localement sur des machines ordinaires ou via des services comme Google Colab, abaissant considérablement la barrière à l'entrée pour la création d'images par IA avancée.
Cas d'Utilisation
DreamOmni2 transforme plusieurs flux de travail professionnels et créatifs en offrant un contrôle multimodal de haute précision.
Accélération des Flux de Travail pour l'E-commerce et le Design
Les commerçants Taobao et les designers peuvent générer rapidement des variations de vêtements ou de produits sans avoir recours à des prises de vue coûteuses. Par exemple, un commerçant peut utiliser une image de référence d'un nouveau motif et une image de référence d'un modèle, en demandant à DreamOmni2 d'appliquer le motif de manière transparente sur le vêtement tout en préservant des plis de tissu réalistes, des ombres et une cohérence d'éclairage.
Intégration de Scènes et de Personnages Complexes
Effectuez un remplacement de personnage très détaillé tout en conservant le réalisme environnemental. Vous pouvez remplacer un personnage dans une scène complexe par une nouvelle image de référence, et le modèle migrera précisément l'éclairage du visage, préservera les détails de l'arrière-plan et reproduira des éléments nuancés comme les détails des yeux, les ombres du cou et la cohérence des cheveux, atteignant une précision d'intégration qui surpasse les simples descriptions textuelles.
Mélange de Styles Avancé Multi-Références
Les designers peuvent répondre à des exigences visuelles complexes en mélangeant plusieurs concepts simultanément. Par exemple, combinez un objet spécifique (par exemple, un perroquet) d'une image, faites-lui porter un accessoire spécifique (un chapeau) d'une deuxième image, puis appliquez l'atmosphère artistique et le ton uniques (par exemple, un éclairage à contraste rouge-bleu) d'une troisième image de référence, le tout via une instruction unique et concise.
Avantages Uniques
DreamOmni2 se distingue par ses performances supérieures dans les tâches complexes et nuancées, ainsi que par son approche innovante de l'exécution d'instructions multimodales, offrant des avantages tangibles aux créateurs exigeants.
Supériorité Vérifiée dans le Traitement des Concepts Abstraits
DreamOmni2 démontre un avantage de performance vérifiable par rapport à des modèles comparables, notamment Google Nano Banana et GPT-4o d'OpenAI, en particulier dans la gestion des concepts abstraits et l'assurance de la cohérence. Lors des tests de référence, DreamOmni2 a obtenu une précision de génération 37 % plus élevée et une cohérence d'objet 29 % plus élevée que d'autres modèles open source de premier plan, prouvant sa capacité à fournir des résultats haute fidélité et cohérents dans des scénarios d'édition complexes.
Compréhension Approfondie des Instructions grâce à l'Entraînement Conjoint VLM
La compétitivité fondamentale de DreamOmni2 réside dans son architecture innovante, qui entraîne conjointement un Modèle de Langage Visuel (VLM, tel que Qwen2.5-VL 7B) avec le modèle génératif. Le VLM agit comme un traducteur intelligent, comprenant d'abord en profondeur le contexte complet de l'instruction multimodale de l'utilisateur (texte + images) avant de la transmettre au modèle génératif pour exécution. Cette séparation de la compréhension et de la génération améliore considérablement la capacité du modèle à exécuter un traitement très précis et détaillé.
Liberté Open Source et Orientation Communautaire
En tant que projet open source issu d'une équipe de recherche universitaire majeure, DreamOmni2 offre une transparence et une flexibilité totales. Ses exigences de déploiement légères (moins de 16 Go de VRAM) garantissent que les chercheurs, développeurs et créateurs du monde entier peuvent accéder à cet outil puissant et l'intégrer dans leurs flux de travail, favorisant une itération rapide et un développement secondaire au sein de la communauté créative.
Conclusion
DreamOmni2 représente une avancée majeure dans l'édition d'images par IA open source, offrant la puissance de l'entrée multimodale et la précision nécessaire pour des résultats de qualité professionnelle. En se concentrant sur la compréhension des attributs abstraits et la fusion complexe multi-références, DreamOmni2 vous permet de concrétiser des visions créatives sophistiquées avec une facilité et une précision sans précédent.
Explorez dès aujourd'hui la page du projet open source et le référentiel de code pour découvrir la prochaine génération d'édition d'images par langage naturel.
FAQ
Q : Qu'est-ce qui distingue DreamOmni2 des modèles texte-vers-image standards ? R : Les modèles traditionnels reposent principalement sur des invites textuelles, qui peinent à exprimer avec précision des concepts abstraits (comme un éclairage spécifique ou la texture d'un matériau) ou à combiner précisément des éléments de plusieurs images. L'architecture multimodale de DreamOmni2 vous permet de fournir 1 à 4 images de référence en plus du texte, permettant au modèle de reproduire précisément des attributs non-verbaux et d'exécuter des tâches de fusion complexes avec une grande fidélité et cohérence.
Q : Quelles sont les exigences matérielles minimales pour exécuter DreamOmni2 localement ? R : DreamOmni2 est conçu pour être léger et accessible. Il nécessite moins de 16 Go de VRAM, ce qui signifie qu'il peut être exécuté efficacement sur de nombreuses machines locales ordinaires ou accessible via des environnements de cloud computing comme Google Colab, sans nécessiter de configurations matérielles haut de gamme et spécialisées.
Q : Qui a développé DreamOmni2, et pourquoi sa performance aux benchmarks est-elle significative ? R : DreamOmni2 a été développé par l'équipe Jia Jiaya de l'Université des Sciences et Technologies de Hong Kong (HKUST). Sa performance aux benchmarks est significative car l'équipe a créé un nouvel ensemble de tests complet (le « benchmark DreamOmni2 ») couvrant les attributs abstraits et l'édition d'objets concrets. Lors de ces tests rigoureux, DreamOmni2 a démontré une précision et une cohérence supérieures dans le traitement des concepts abstraits par rapport à des modèles propriétaires établis comme Google Nano Banana et GPT-4o.
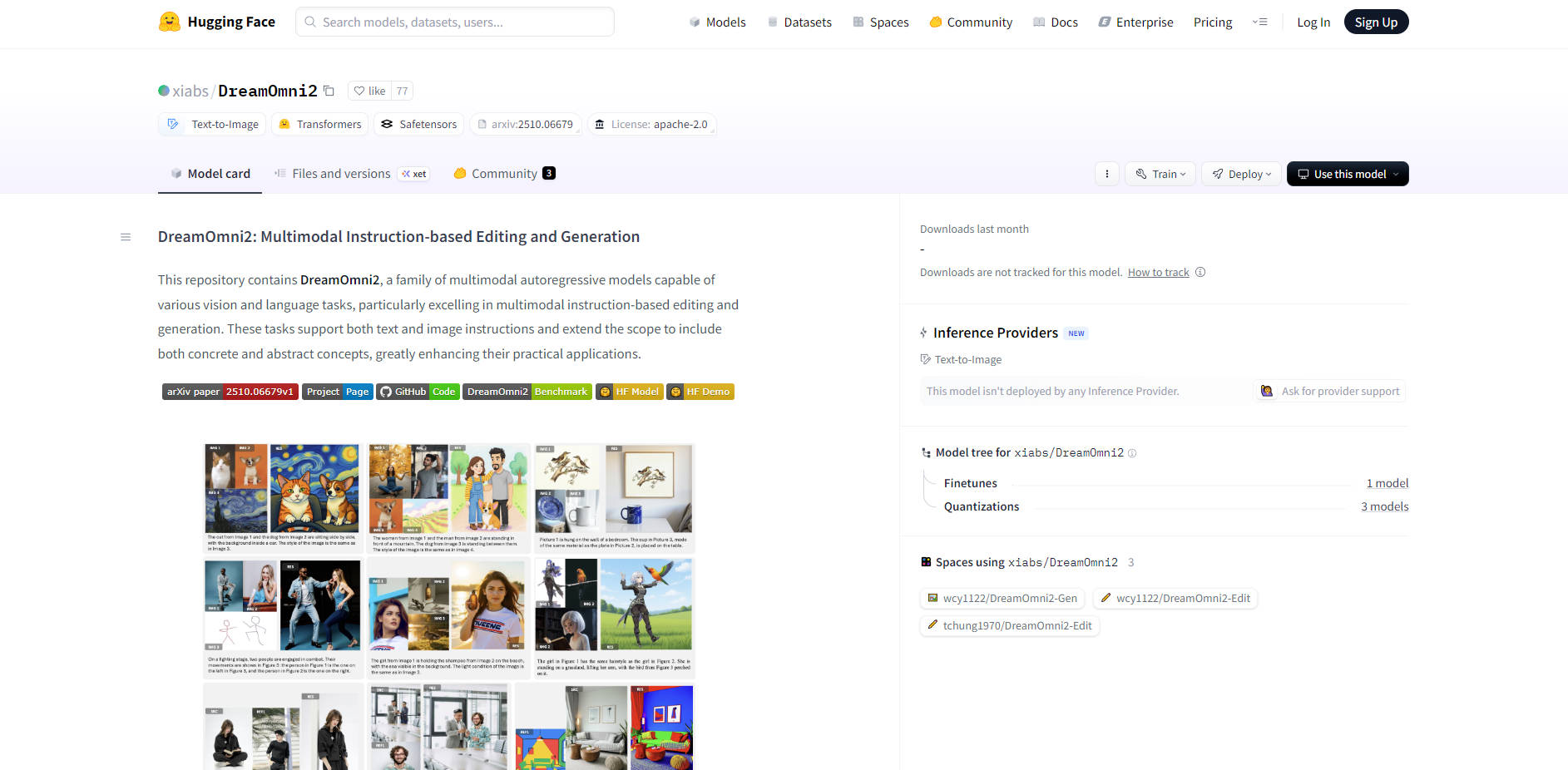
More information on DreamOmni2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DreamOmni2 was manually vetted by our editorial team and was first featured on 2025-11-03.
DreamOmni2 Alternatives
Plus Alternatives-
Nano Banana : Édition et création d'images par IA avec Gemini 2.5 Flash. Obtenez des transformations précises, pilotées par le texte, et une cohérence des sujets inégalée, le tout avec une rapidité fulgurante.
-

OmniGen AI par BAAI est un modèle de pointe de texte à image. Cadre unifié pour une création transparente. Transforme le texte et les images. Idéal pour les artistes, les marketeurs et les chercheurs. Libérez votre créativité !
-

OLMo 2 32B : Un LLM open source qui rivalise avec GPT-3.5 ! Code, données et pondérations gratuits. Faites de la recherche, personnalisez et développez une IA plus intelligente.
-
Nano Banana réinvente la retouche d'images par IA. Profitez d'une cohérence des personnages inégalée et de flux de travail 10 fois plus rapides, le tout optimisé par Gemini pour concrétiser votre vision créative avec une précision chirurgicale.
-

Optimisez l'efficacité des LLM avec DeepSeek-OCR. Compressez les documents visuels jusqu'à 10 fois avec une précision de 97 %. Traitez des volumes massifs de données pour l'entraînement des IA et la transformation numérique des entreprises.