
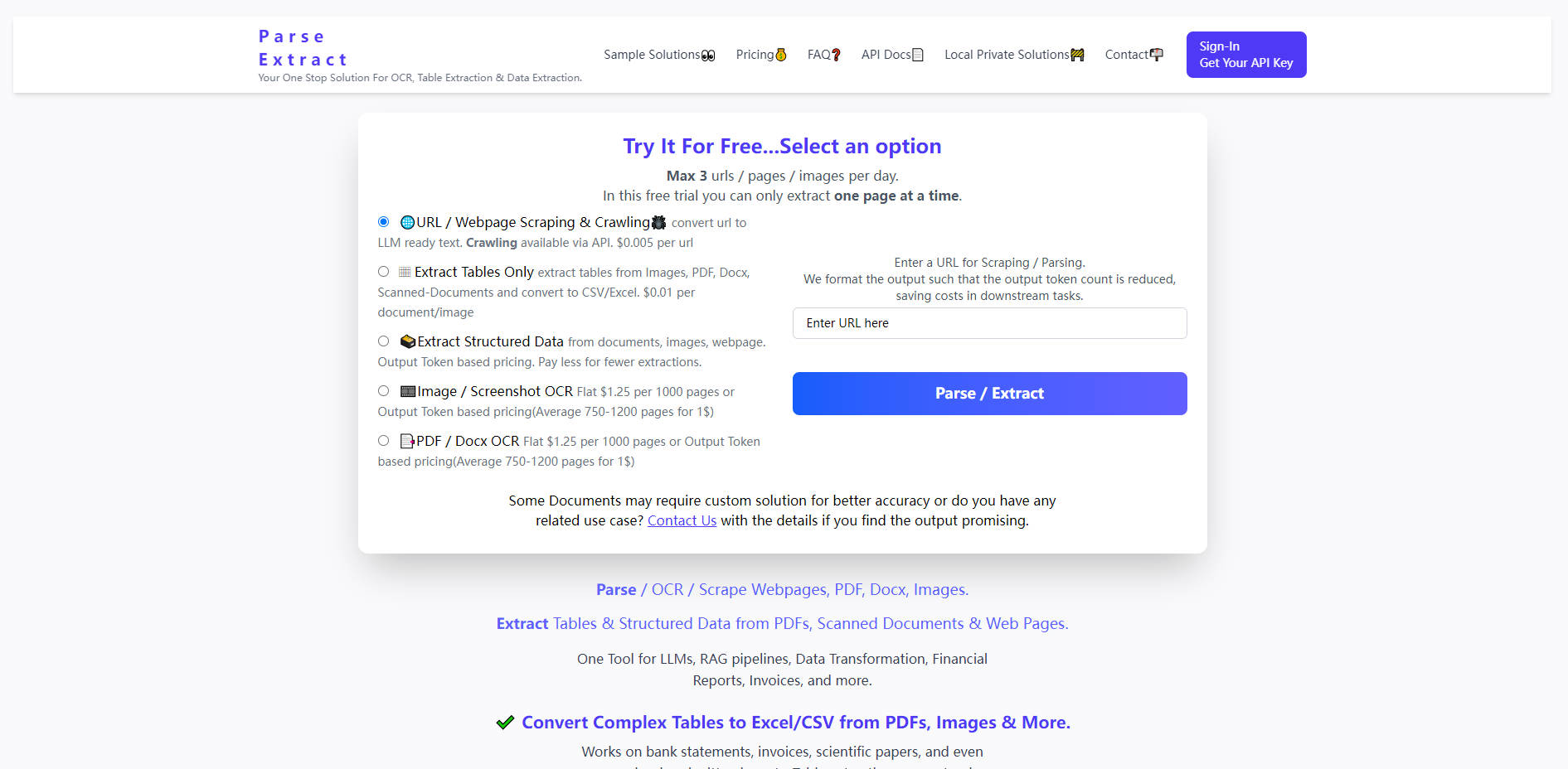
What is Parse Extract?
Los datos no estructurados —desde complejos archivos PDF y documentos escaneados hasta páginas web dinámicas— representan un cuello de botella considerable para el desarrollo de la IA y la automatización de datos. Parse Extract es una plataforma especializada de alta eficiencia para la preparación de datos, diseñada para superar este desafío. Ofrece una API unificada para el reconocimiento óptico de caracteres (OCR), la extracción de datos estructurados y el análisis web, garantizando que las entradas complejas y de medios mixtos se transformen en texto limpio, listo para LLM, y en formatos estructurados como CSV y Excel. Si está desarrollando pipelines RAG, automatizando análisis financieros o necesita una transformación de datos fiable y de alto volumen, Parse Extract ofrece precisión y una eficiencia de costes inigualable.
Características Clave
Parse Extract dota a desarrolladores y equipos de datos de potentes herramientas para desvelar al instante los conocimientos ocultos en documentos desordenados y sitios web.
📊 Extracción de Tablas con Precisión
Vaya más allá del reconocimiento de texto básico. Parse Extract identifica y convierte con precisión tablas complejas —incluidas las que se encuentran en imágenes de baja resolución, extractos bancarios, artículos científicos y diseños financieros manuscritos o escaneados— directamente en archivos CSV o Excel utilizables. Esta capacidad es fundamental para los pipelines de transformación de datos donde la integridad estructural es primordial.
🌐 Extracción y Rastreo Web Optimizados para LLM
Convierta sin esfuerzo cualquier URL o página web en texto limpio y estructurado, listo para grandes modelos de lenguaje. El servicio formatea inteligentemente la salida para minimizar el recuento de tokens, reduciendo directamente sus costes operativos en tareas LLM posteriores (como la elaboración de resúmenes o el análisis), a la vez que proporciona los datos necesarios para el rastreo de sitios web impulsado por API.
📄 OCR de Documentos e Imágenes de Alto Volumen
Emplee sólidas capacidades de OCR en una variedad de formatos, incluyendo PDF, Docx y diversos tipos de imágenes. Ya sea procesando densos manuales técnicos o lotes de facturas escaneadas, Parse Extract asegura una conversión de texto de alta fidelidad, admitiendo documentos de hasta 100 MB de tamaño, lo que lo hace idóneo para proyectos de digitalización a gran escala.
🤖 Soluciones RAG y de Chatbot Integradas
Parse Extract ofrece servicios de Generación Aumentada por Recuperación (RAG) listos para implementar y chatbots personalizados que gestionan las complejidades de los datos del mundo real. Estas soluciones están diseñadas para procesar y razonar eficientemente sobre documentos que contienen elementos diversos, incluyendo imágenes, tablas y expresiones matemáticas, proporcionando una base altamente competente para la recuperación de conocimiento empresarial.
Casos de Uso
Parse Extract agiliza los flujos de trabajo en diversos dominios críticos de uso intensivo de datos, transformando el esfuerzo en información automatizada.
1. Mejora del Rendimiento de los Pipelines RAG
Los desarrolladores utilizan Parse Extract para preprocesar documentos fuente (manuales, bases de conocimiento, informes internos) antes de la indexación. Al extraer tablas con precisión y optimizar la estructura del texto, los embeddings resultantes son de mayor calidad, lo que conduce a resultados más precisos, contextualmente relevantes y menos propensos a alucinaciones cuando los usuarios consultan el sistema RAG.
2. Procesamiento Automatizado de Datos Financieros
Las instituciones financieras o las empresas de contabilidad pueden automatizar la extracción de puntos de datos críticos de documentos estructurados pero variados. Por ejemplo, al introducir miles de facturas escaneadas, extractos bancarios e informes trimestrales en Parse Extract, se logra una conversión instantánea de tablas y campos clave (fechas, importes, nombres de proveedores) a un formato Excel estructurado, acelerando drásticamente los procesos de conciliación y auditoría.
3. Construcción de Agentes de IA Altamente Especializados
Los ingenieros de IA aprovechan las capacidades de extracción de datos estructurados de Parse Extract para impulsar agentes de IA sofisticados. Al proporcionar a los agentes datos limpios y fiables, extraídos de páginas web específicas o documentos complejos, se garantiza que los agentes dispongan de las entradas precisas necesarias para ejecutar tareas complejas y de varios pasos, como la monitorización del mercado, el análisis competitivo o las comprobaciones automatizadas de cumplimiento normativo.
Conclusión
Parse Extract proporciona la base esencial y de alta precisión necesaria para salvar la brecha entre los datos complejos y no estructurados y las aplicaciones de IA modernas. Al priorizar la eficiencia de costes, la extracción precisa de tablas y la optimización de la salida, capacita a desarrolladores y empresas para construir pipelines de datos más rápidos, inteligentes y significativamente más asequibles.
More information on Parse Extract
Launched
2025-06
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Parse Extract was manually vetted by our editorial team and was first featured on 2025-10-31.
Parse Extract Alternativas
Más Alternativas-

-

-

Extractor API: Obtén datos limpios y estructurados de cualquier página web, PDF o noticia con IA. Automatiza el web scraping complejo y aprovecha los LLMs para generar perspectivas profundas.
-

Extrae sin esfuerzo datos web estructurados de cualquier sitio web utilizando IA. ¡No hace falta código! Define con precisión lo que necesitas mediante prompts y esquemas.
-

Extrae datos de cualquier documento no estructurado usando Extracta.ai. Analiza automáticamente documentos escaneados y recupera la información que necesitas.