
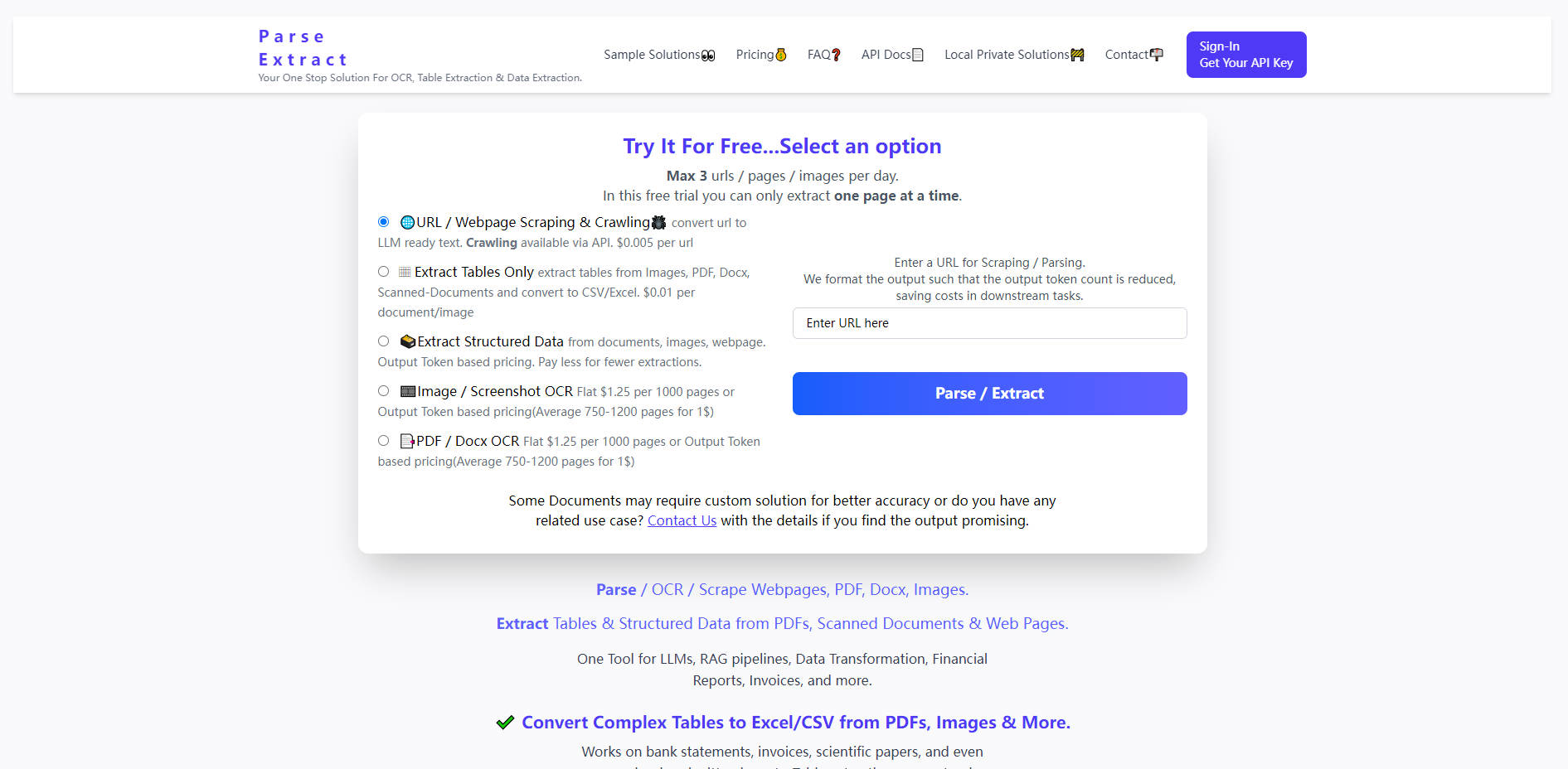
What is Parse Extract?
Les données non structurées, qu'il s'agisse de PDF complexes, de documents numérisés ou de pages web dynamiques, constituent un goulot d'étranglement majeur pour le développement de l'IA et l'automatisation des données. Parse Extract est une plateforme de préparation de données spécialisée et hautement efficace, conçue pour relever ce défi. Elle offre une API unifiée pour la reconnaissance optique de caractères (OCR), l'extraction de données structurées et l'analyse de pages web, garantissant que les entrées complexes et multimédias sont converties en texte propre, prêt pour les LLM, et en formats structurés comme CSV et Excel. Que vous développiez des pipelines RAG, automatisiez l'analyse financière, ou ayez besoin d'une transformation de données fiable et à haut volume, Parse Extract offre une précision et une rentabilité inégalées.
Fonctionnalités Clés
Parse Extract dote les développeurs et les équipes de données d'outils puissants pour débloquer instantanément les informations cachées dans les documents et sites web complexes.
📊 Extraction de tableaux de précision
Allez au-delà de la reconnaissance de texte basique. Parse Extract identifie et convertit avec précision les tableaux complexes, y compris ceux trouvés dans des images basse résolution, des relevés bancaires, des articles scientifiques et des mises en page financières manuscrites ou numérisées, directement en fichiers CSV ou Excel utilisables. Cette capacité est essentielle pour les pipelines de transformation de données où l'intégrité structurelle est primordiale.
🌐 Web scraping et crawling optimisés pour les LLM
Convertissez de manière transparente n'importe quelle URL ou page web en texte propre et structuré, prêt pour les grands modèles de langage. Le service formate intelligemment la sortie pour minimiser le nombre de jetons, réduisant directement vos coûts opérationnels dans les tâches LLM en aval (telles que la synthèse ou l'analyse) tout en fournissant les données nécessaires au crawling de sites web piloté par API.
📄 OCR de documents et d'images à grand volume
Utilisez des capacités OCR robustes pour une gamme de formats, y compris PDF, Docx et divers types d'images. Qu'il s'agisse de traiter des manuels techniques denses ou des lots de factures numérisées, Parse Extract assure une conversion de texte de haute fidélité, prenant en charge des documents allant jusqu'à 100 Mo, ce qui le rend adapté aux projets de numérisation à grande échelle.
🤖 Solutions RAG et chatbot intégrées
Parse Extract propose des services de Génération Augmentée par la Récupération (RAG) prêts à être déployés et des chatbots personnalisés qui gèrent les complexités des données du monde réel. Ces solutions sont conçues pour traiter et raisonner efficacement sur des documents contenant des éléments divers, y compris des images, des tableaux et des expressions mathématiques, fournissant une base très performante pour la récupération des connaissances en entreprise.
Cas d'utilisation
Parse Extract rationalise les flux de travail dans plusieurs domaines critiques gourmands en données, transformant l'effort en informations automatisées.
1. Améliorer la performance des pipelines RAG
Les développeurs utilisent Parse Extract pour prétraiter les documents sources (manuels, bases de connaissances, rapports internes) avant l'indexation. En extrayant avec précision les tableaux et en optimisant la structure du texte, les embeddings résultants sont de meilleure qualité, ce qui conduit à des résultats plus précis, plus pertinents sur le plan contextuel et moins sujets aux hallucinations lorsque les utilisateurs interrogent le système RAG.
2. Traitement automatisé des données financières
Les institutions financières ou les cabinets comptables peuvent automatiser l'extraction de points de données critiques à partir de documents structurés mais variés. Par exemple, l'alimentation de milliers de factures numérisées, de relevés bancaires et de rapports trimestriels dans Parse Extract permet la conversion instantanée des tableaux et des champs clés (dates, montants, noms de fournisseurs) en un format Excel structuré, accélérant considérablement les processus de rapprochement et d'audit.
3. Création d'agents IA hautement spécialisés
Les ingénieurs en IA tirent parti des capacités d'extraction de données structurées de Parse Extract pour alimenter des agents IA sophistiqués. En fournissant aux agents des données propres et fiables extraites de pages web spécifiques ou de documents complexes, vous vous assurez que les agents disposent des entrées précises nécessaires pour exécuter des tâches complexes et multi-étapes, telles que la surveillance du marché, l'analyse concurrentielle ou les contrôles automatisés de conformité réglementaire.
Conclusion
Parse Extract fournit la base essentielle de haute précision nécessaire pour combler le fossé entre les données complexes et non structurées et les applications d'IA modernes. En privilégiant la rentabilité, l'extraction de tableaux de précision et l'optimisation des sorties, il permet aux développeurs et aux entreprises de construire des pipelines de données plus rapides, plus intelligents et nettement plus abordables.
More information on Parse Extract
Launched
2025-06
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Parse Extract was manually vetted by our editorial team and was first featured on 2025-10-31.
Parse Extract Alternatives
Plus Alternatives-

-

-

Extractor API : Obtenez des données propres et structurées depuis n'importe quelle page web, PDF ou source d'actualités, grâce à l'IA. Automatisez le web scraping complexe et tirez parti des LLMs pour des analyses approfondies.
-

Extrayez les données web structurées de n'importe quel site en toute simplicité, grâce à l'IA. Aucun code requis ! Définissez précisément vos besoins à l'aide de prompts et de schémas.
-

Avec Extracta.ai, extrayez des données depuis n'importe quel document non structuré. Analysez automatiquement les documents numérisés et récupérez les informations dont vous avez besoin.