
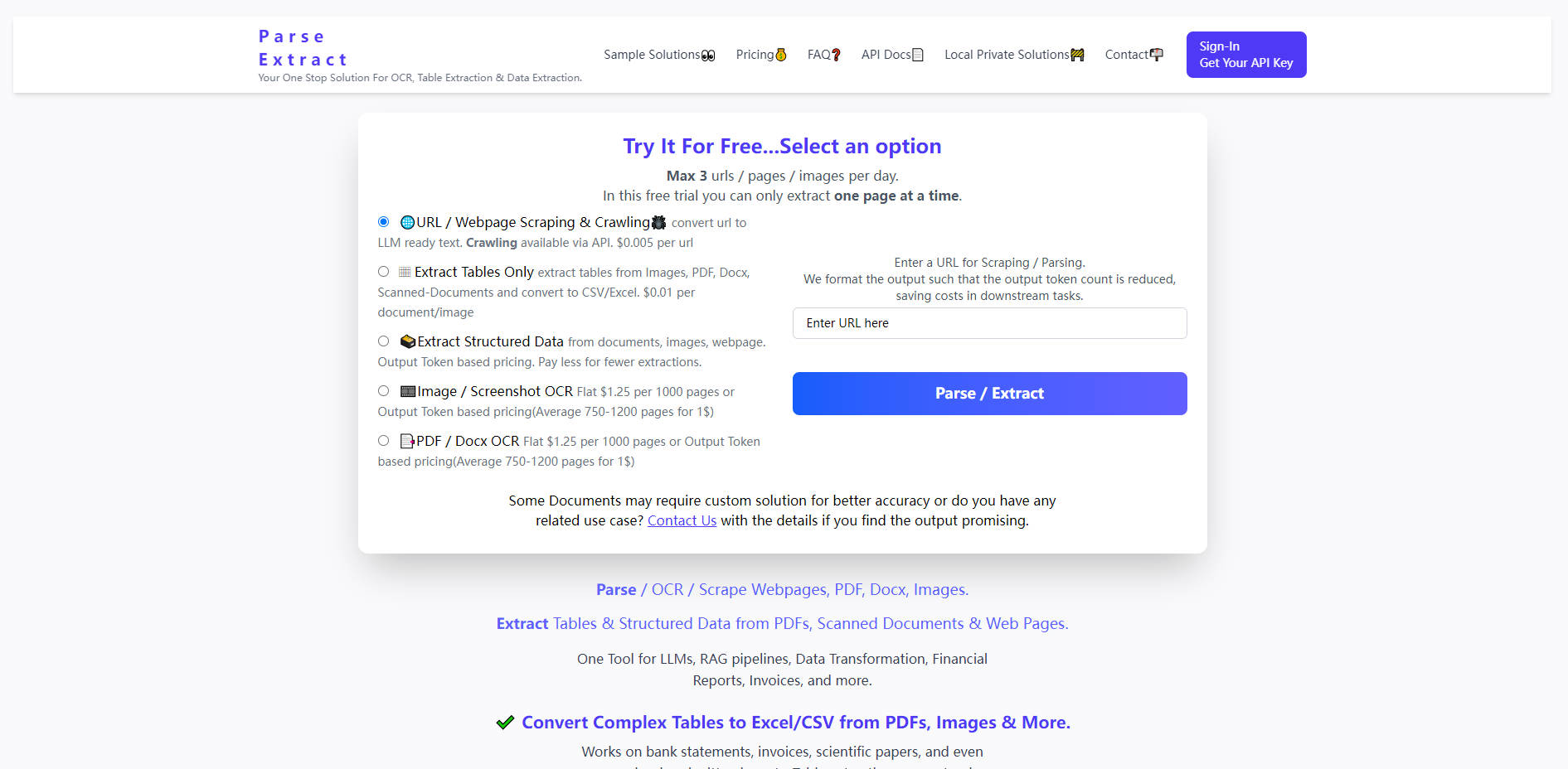
What is Parse Extract?
Неструктурированные данные — от сложных PDF-файлов и сканированных документов до динамических веб-страниц — являются серьёзным препятствием для развития ИИ и автоматизации данных. Parse Extract — это специализированная высокоэффективная платформа для подготовки данных, разработанная для решения этой задачи. Она предоставляет унифицированный API для оптического распознавания символов (OCR), извлечения структурированных данных и веб-парсинга, гарантируя преобразование сложных смешанных входных данных в чистый текст, готовый для LLM, и структурированные форматы, такие как CSV и Excel. Если вы создаёте конвейеры RAG, автоматизируете финансовый анализ или нуждаетесь в надёжной высокообъёмной трансформации данных, Parse Extract обеспечивает точность и беспрецедентную экономическую эффективность.
Ключевые особенности
Parse Extract предоставляет разработчикам и командам по работе с данными мощные инструменты для мгновенного извлечения ценной информации, скрытой в неструктурированных документах и на веб-сайтах.
📊 Точное извлечение таблиц
Выйдите за рамки базового распознавания текста. Parse Extract точно идентифицирует и преобразует сложные таблицы, включая те, что содержатся в изображениях низкого разрешения, банковских выписках, научных статьях, а также в рукописных или сканированных финансовых отчётах, — непосредственно в пригодные для использования файлы CSV или Excel. Эта возможность незаменима для конвейеров трансформации данных, где структурная целостность имеет первостепенное значение.
🌐 Оптимизированный для LLM веб-скрейпинг и краулинг
Легко преобразуйте любой URL-адрес или веб-страницу в чистый структурированный текст, готовый для больших языковых моделей. Сервис интеллектуально форматирует вывод, чтобы минимизировать количество токенов, напрямую снижая ваши операционные расходы при выполнении последующих задач LLM (таких как суммаризация или анализ), одновременно предоставляя необходимые данные для краулинга веб-сайтов через API.
📄 Высокообъёмное OCR документов и изображений
Используйте надёжные возможности OCR для широкого спектра форматов, включая PDF, Docx и различные типы изображений. Будь то обработка объёмных технических руководств или партий сканированных счетов, Parse Extract обеспечивает высокоточную конвертацию текста, поддерживая документы размером до 100 МБ, что делает его пригодным для крупномасштабных проектов по оцифровке.
🤖 Интегрированные решения RAG и чат-ботов
Parse Extract предлагает готовые к развёртыванию сервисы Retrieval-Augmented Generation (RAG) и кастомизированные чат-боты, которые справляются со сложностями реальных данных. Эти решения разработаны для эффективной обработки и анализа документов, содержащих разнообразные элементы, включая изображения, таблицы и математические выражения, создавая высокоэффективную основу для извлечения корпоративных знаний.
Сценарии использования
Parse Extract оптимизирует рабочие процессы в нескольких критически важных областях с интенсивной обработкой данных, превращая ручной труд в автоматизированные инсайты.
1. Повышение производительности конвейеров RAG
Разработчики используют Parse Extract для предварительной обработки исходных документов (руководств, баз знаний, внутренних отчётов) перед индексацией. Благодаря точному извлечению таблиц и оптимизации структуры текста, результирующие эмбеддинги становятся более качественными, что приводит к более точным, контекстуально релевантным и менее склонным к галлюцинациям результатам при запросах пользователей к системе RAG.
2. Автоматизированная обработка финансовых данных
Финансовые учреждения или бухгалтерские фирмы могут автоматизировать извлечение критически важных данных из структурированных, но разнообразных документов. Например, загрузка тысяч сканированных счетов, банковских выписок и квартальных отчётов в Parse Extract позволяет мгновенно преобразовывать таблицы и ключевые поля (даты, суммы, имена поставщиков) в структурированный формат Excel, что значительно ускоряет процессы сверки и аудита.
3. Создание высокоспециализированных ИИ-агентов
ИИ-инженеры используют возможности Parse Extract по извлечению структурированных данных для создания мощных ИИ-агентов. Предоставляя агентам чистые, надёжные данные, извлечённые с определённых веб-страниц или из сложных документов, вы гарантируете, что агенты получат точные входные данные, необходимые для выполнения сложных многошаговых задач, таких как мониторинг рынка, конкурентный анализ или автоматизированные проверки соответствия нормативным требованиям.
Заключение
Parse Extract обеспечивает необходимую высокоточную основу для преодоления разрыва между сложными, неструктурированными данными и современными ИИ-приложениями. Благодаря приоритету экономической эффективности, точному извлечению таблиц и оптимизации вывода, платформа даёт разработчикам и компаниям возможность создавать более быстрые, интеллектуальные и значительно более экономичные конвейеры обработки данных.
More information on Parse Extract
Launched
2025-06
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Parse Extract was manually vetted by our editorial team and was first featured on 2025-10-31.
Parse Extract Альтернативи
Больше Альтернативи-

-

-

Extractor API: Извлекайте чистые, структурированные данные с любой веб-страницы, из PDF или новостей с AI. Автоматизируйте сложный веб-скрейпинг и используйте LLMs для глубоких инсайтов.
-

С легкостью извлекайте структурированные веб-данные с любого сайта, используя ИИ. Код не нужен! Определяйте в точности, что вам нужно, с помощью промптов и схемы.
-

Извлекайте данные из любых неструктурированных документов с помощью Extracta.ai. Автоматически анализируйте отсканированные документы и извлекайте необходимую информацию.