
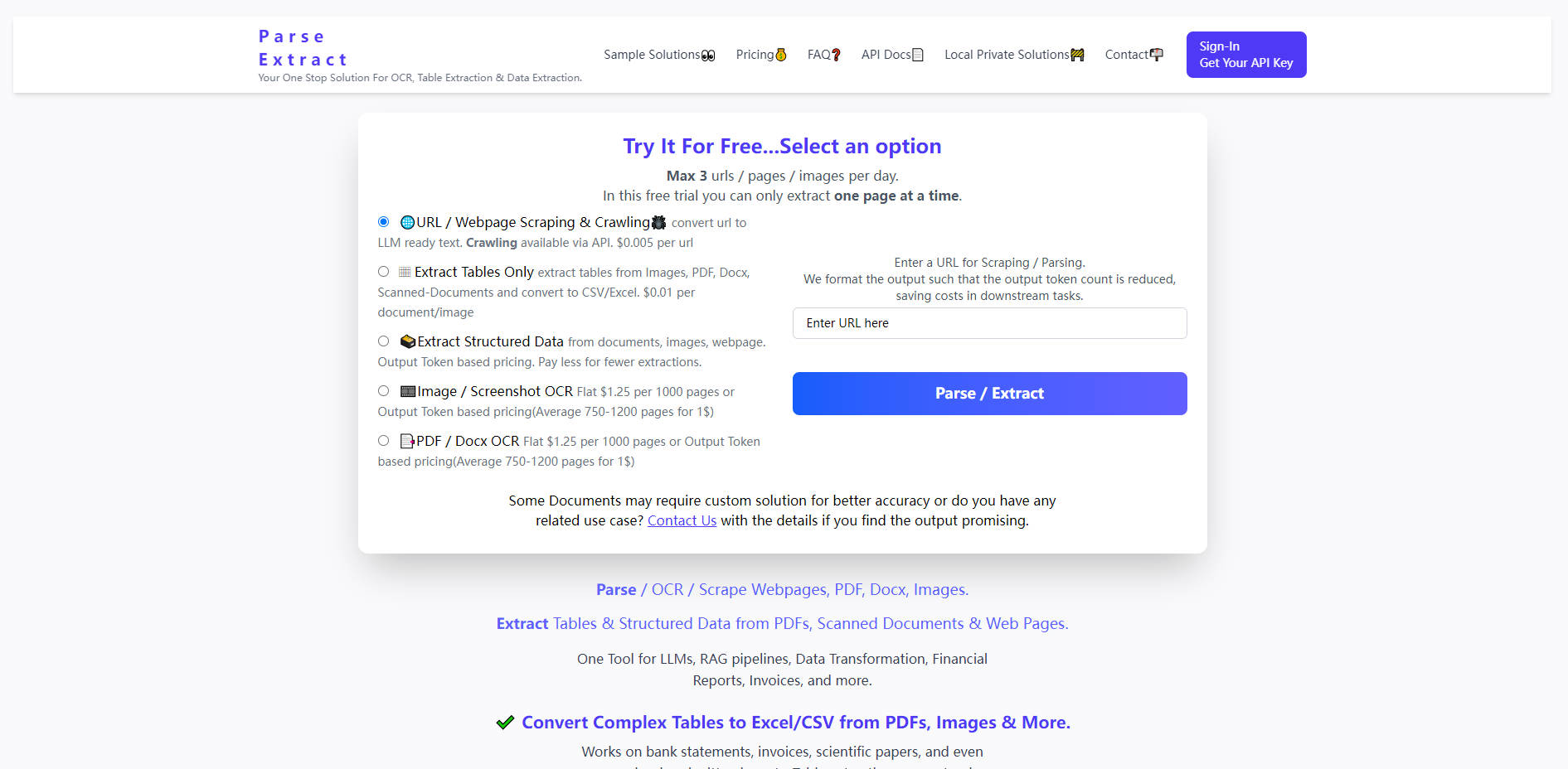
What is Parse Extract?
複雑なPDFやスキャンされた文書から動的なウェブページに至るまで、非構造化データはAI開発とデータ自動化における大きなボトルネックとなっています。 Parse Extract は、この課題を解決するために設計された、専門的かつ高効率なデータ準備プラットフォームです。OCR、構造化データ抽出、ウェブ解析のための統合APIを提供し、複雑な複合メディア入力であっても、LLMですぐに利用可能なクリーンなテキスト、そしてCSVやExcelのような構造化された形式へと変換されることを保証します。RAGパイプラインの構築、財務分析の自動化、あるいは信頼性の高い大量のデータ変換が必要な場合でも、Parse Extract は正確性と比類ない費用対効果を提供します。
主な機能
Parse Extract は、開発者やデータチームに強力なツールを提供し、煩雑な文書やウェブサイトに隠された洞察を瞬時に引き出すことを可能にします。
📊 高精度なテーブル抽出
単純なテキスト認識を超越します。Parse Extract は、低解像度の画像、銀行取引明細書、科学論文、手書きやスキャンされた財務レイアウトに含まれるものも含め、複雑なテーブルを正確に識別し、直接利用可能なCSVまたはExcelファイルへと変換します。この機能は、構造の整合性が最も重要となるデータ変換パイプラインにとって不可欠です。
🌐 LLMに最適化されたウェブスクレイピング & クローリング
任意のURLやウェブページを、大規模言語モデル(LLM)で利用可能なクリーンな構造化テキストへとシームレスに変換します。このサービスは、トークン数を最小限に抑えるように出力をインテリジェントにフォーマットします。これにより、要約や分析といった下流のLLMタスクにおける運用コストを直接削減しながら、API駆動型ウェブサイトクローリングに必要なデータも提供します。
📄 大容量文書 & 画像OCR
PDF、Docx、さまざまな画像タイプを含む幅広いフォーマットで、堅牢なOCR機能を活用できます。密度の高い技術マニュアルや大量のスキャン済み請求書の処理であっても、Parse Extract は高精度なテキスト変換を保証します。最大100MBまでの文書をサポートし、大規模なデジタル化プロジェクトにも適しています。
🤖 統合されたRAGとチャットボットソリューション
Parse Extract は、現実世界のデータの複雑性に対応する、すぐに展開可能なRAG(Retrieval-Augmented Generation)サービスとカスタムチャットボットを提供します。これらのソリューションは、画像、テーブル、数式といった多様な要素を含む文書を効率的に処理し、推論できるように設計されており、エンタープライズ知識検索のための非常に有能な基盤を提供します。
ユースケース
Parse Extract は、複数の重要なデータ集約型ドメインにおけるワークフローを効率化し、労力を自動化された洞察へと転換します。
1. RAGパイプラインのパフォーマンス向上
開発者は、インデックス作成前にParse Extract を使用してソース文書(マニュアル、ナレッジベース、内部レポートなど)を前処理します。テーブルを正確に抽出し、テキスト構造を最適化することで、結果として得られる埋め込みの品質が向上し、ユーザーがRAGシステムにクエリを実行した際に、より正確で文脈に沿った、ハルシネーションの少ない結果が得られるようになります。
2. 財務データの自動処理
金融機関や会計事務所は、構造化されているものの多様な文書から重要なデータポイントの抽出を自動化できます。例えば、何千ものスキャンされた請求書、銀行取引明細書、四半期報告書をParse Extract に取り込むことで、テーブルや主要フィールド(日付、金額、ベンダー名など)を構造化されたExcel形式に瞬時に変換することが可能になり、照合および監査プロセスを劇的に加速させます。
3. 高度な専門性を持つAIエージェントの構築
AIエンジニアは、Parse Extract の構造化データ抽出機能を活用して、高度なAIエージェントを強化します。特定のウェブページや複雑な文書から抽出されたクリーンで信頼性の高いデータをエージェントに提供することで、市場監視、競合分析、自動規制コンプライアンスチェックといった複雑な多段階タスクを実行するために必要な、正確な入力データをエージェントが持つことを保証します。
まとめ
Parse Extract は、複雑な非構造化データと最新のAIアプリケーションとの間のギャップを埋めるために必要不可欠な、高精度基盤を提供します。費用対効果、高精度なテーブル抽出、出力最適化を重視することで、開発者や企業は、より迅速に、よりスマートに、そして大幅に費用を抑えてデータパイプラインを構築できるようになります。
More information on Parse Extract
Launched
2025-06
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Parse Extract was manually vetted by our editorial team and was first featured on 2025-10-31.
Parse Extract 代替ソフト
もっと見る 代替ソフト-

-

-

Extractor API: AIを駆使し、あらゆるウェブページ、PDF、ニュースから、クリーンで構造化されたデータを抽出。複雑なウェブスクレイピングを自動化し、LLMsを活用して深い洞察へと導きます。
-

AIを活用し、あらゆるサイトから構造化されたウェブデータを楽々抽出。コードは一切不要です!プロンプトとスキーマで、必要な情報を正確に定義するだけ。
-

Extracta.ai を使用して、構造化されていないあらゆる文書からデータを抽出します。スキャンした文書を自動的に解析し、必要な情報を取得します。