
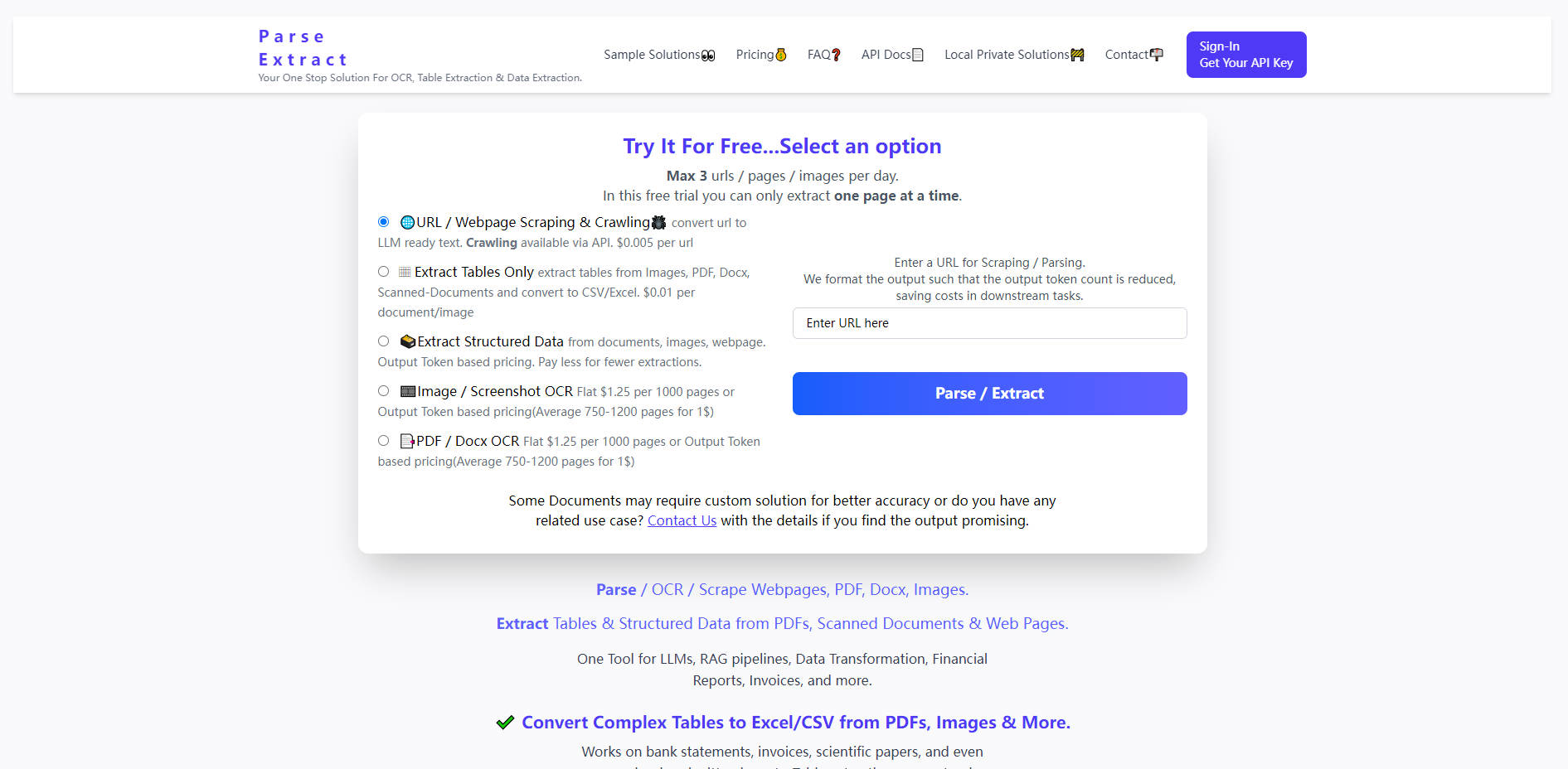
What is Parse Extract?
非结构化数据——从复杂的PDF、扫描文档到动态网页——是人工智能发展和数据自动化面临的一个巨大瓶颈。Parse Extract 正是一个为解决这一挑战而设计的专业高效数据准备平台。它提供统一的API接口,集光学字符识别(OCR)、结构化数据提取和网页解析功能于一身,确保将复杂的混合媒体输入转换为干净、可供LLM(大型语言模型)使用的文本,以及CSV和Excel等结构化格式。无论您是构建RAG(检索增强生成)管道、自动化财务分析,还是需要可靠的高吞吐量数据转换,Parse Extract 都能提供卓越的准确性和无与伦比的成本效益。
主要特性
Parse Extract 为开发者和数据团队提供了强大的工具,能够即时发掘杂乱文档和网站中隐藏的宝贵洞察。
📊 精准表格提取
远超基本的文本识别功能。Parse Extract 能够精准识别并转换各种复杂表格——包括低分辨率图像、银行对账单、科学论文以及手写或扫描的财务布局中的表格——直接生成可用的CSV或Excel文件。这一能力对于结构完整性至关重要的数据转换流程而言不可或缺。
🌐 LLM优化型网页抓取与爬虫
将任意URL或网页无缝转换为供大型语言模型使用的干净、结构化文本。该服务能够智能优化输出格式,最大限度地减少token(标记)数量,从而直接降低您在下游LLM任务(如摘要或分析)中的运营成本,同时为API驱动的网站爬虫提供所需数据。
📄 高吞吐量文档与图像OCR
利用强大的OCR能力,支持PDF、Docx和各种图像类型等多种格式。无论是处理密集的专业技术手册,还是批量扫描的发票,Parse Extract 都能确保高保真文本转换,支持最大100MB的文档,使其适用于大规模数字化项目。
🤖 集成式RAG与聊天机器人解决方案
Parse Extract 提供即开即用的检索增强生成(RAG)服务和定制化聊天机器人,能够有效应对现实世界数据的复杂性。这些解决方案经过精心设计,能够高效处理和分析包含图像、表格和数学表达式等多样化元素的文档,为企业知识检索奠定强大基础。
应用场景
Parse Extract 简化了多个关键数据密集型领域的工作流程,将繁琐的人工操作转化为自动化的智能洞察。
1. 提升RAG管道性能
开发者利用 Parse Extract 在文档索引前对源文件(如手册、知识库、内部报告)进行预处理。通过精准提取表格并优化文本结构,可以生成更高质量的嵌入(embeddings),从而在用户查询RAG系统时,获得更准确、更具上下文关联性且更少出现幻觉的结果。
2. 自动化金融数据处理
金融机构或会计事务所可以自动化地从结构化但格式多样的文档中提取关键数据点。例如,将数千份扫描发票、银行对账单和季度报告输入 Parse Extract,可以实现表格和关键字段(日期、金额、供应商名称)的即时转换,生成结构化的Excel格式数据,从而极大加速对账和审计流程。
3. 构建高度专业化AI智能体
AI工程师利用 Parse Extract 的结构化数据提取能力,为复杂的AI智能体提供强大支持。通过为智能体提供从特定网页或复杂文档中提取的干净、可靠数据,您可以确保智能体获得执行复杂多步骤任务(如市场监控、竞争分析或自动化法规遵从性检查)所需的精确输入。
总结
Parse Extract 提供了必不可少的高精度基础,以弥合复杂非结构化数据与现代AI应用之间的鸿沟。通过优先考虑成本效益、精准表格提取和输出优化,它赋能开发者和企业构建更快、更智能且成本显著更低的数据管道。
More information on Parse Extract
Launched
2025-06
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Parse Extract was manually vetted by our editorial team and was first featured on 2025-10-31.
Parse Extract 替代方案
更多 替代方案-

-

-

Extractor API:利用人工智能,从任何网页、PDF或新闻中提取干净、结构化的数据,同时自动化复杂的网络爬取,并借助大型语言模型(LLM)提供深度洞察。
-

-
