What is The Pile?
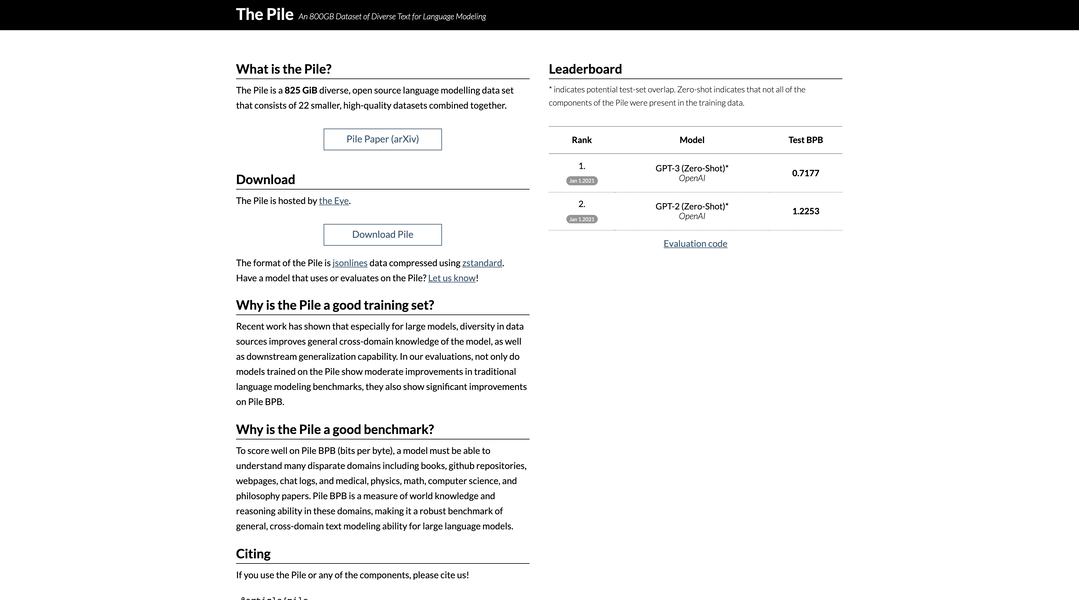
The Pile est un ensemble de données open-source pour la modélisation du langage de 825 Gio, méticuleusement établi à partir de 22 ensembles de données diversifiés de haute qualité, hébergés par Eye. Il constitue une ressource complète pour l'entraînement de modèles, offrant une meilleure connaissance interdomaine et améliorant les capacités de généralisation.
Caractéristiques principales :
? Compilation de données variées : The Pile regroupe 22 ensembles de données plus petits, englobant un large éventail de sources telles que des livres, des dépôts GitHub, des pages Web, des journaux de discussion et des articles universitaires provenant de divers domaines, favorisant une formation complète des modèles de langage.
? Performances améliorées des modèles : les modèles entraînés sur The Pile présentent des améliorations notables dans les références de modélisation linguistique traditionnelles, ainsi que des avancées significatives dans Pile BPB (bits par octet), indiquant une meilleure maîtrise de la modélisation de texte interdomaine.
? Benchmarking robuste : Pile BPB sert de référence rigoureuse, évaluant les capacités de compréhension et de raisonnement d'un modèle dans des domaines disparates, notamment la littérature, la science, la technologie et la philosophie, offrant un aperçu de sa compétence générale en modélisation de texte interdomaine.
Cas d'utilisation :
Recherche universitaire : les chercheurs peuvent exploiter The Pile pour entraîner des modèles pour diverses tâches linguistiques, améliorant leur compréhension de la dynamique du langage et facilitant les percées dans le traitement du langage naturel.
Développement de modèles d'IA : les développeurs peuvent utiliser The Pile pour entraîner des modèles de langage robustes capables de comprendre et de générer du texte dans divers domaines, renforçant les applications dans les chatbots, la génération de contenu et l'analyse des sentiments.
Initiatives éducatives : les éducateurs peuvent intégrer The Pile dans le développement des programmes d'études, permettant aux élèves d'explorer les techniques de modélisation du langage et d'acquérir une expérience pratique dans l'analyse et la génération de texte dans divers contextes.
Conclusion :
Avec son ensemble de données vaste et diversifié, The Pile offre une ressource transformatrice pour faire progresser les capacités de modélisation du langage. Que ce soit pour la recherche, le développement ou l'éducation, sa couverture complète et son benchmarking robuste garantissent des performances accrues des modèles et une applicabilité interdomaine. Plongez dans The Pile dès aujourd'hui pour libérer tout le potentiel de la modélisation du langage.
FAQ :
Qu'est-ce qui rend The Pile unique par rapport aux autres ensembles de données de modélisation du langage ?
The Pile se distingue par sa vaste compilation d'ensembles de données diversifiés, couvrant plusieurs domaines, notamment la littérature, la science, la technologie, etc. Cette diversité enrichit la formation des modèles et favorise une meilleure compréhension du texte interdomaine.
Comment les chercheurs peuvent-ils contribuer à The Pile ?
Les chercheurs peuvent contribuer à The Pile en fournissant des commentaires, en suggérant des ensembles de données supplémentaires à inclure ou en partageant des informations sur les performances des modèles. Les efforts de collaboration garantissent une amélioration et un raffinement continus de l'ensemble de données.
The Pile convient-il à l'entraînement de modèles de toutes tailles ?
Oui, The Pile s'adresse à des modèles de différentes tailles, des petits projets aux déploiements à grande échelle. Son évolutivité et sa polyvalence en font une ressource précieuse pour diverses initiatives de modélisation du langage.
More information on The Pile
Launched
2020-07
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Fastly,GitHub Pages,Varnish
Top 5 Countries
16.11%
15.16%
12.4%
11.04%
8.58%
India
Germany
France
United States
Turkey
Traffic Sources
3.65%
0.95%
0.15%
20.46%
38.66%
35.68%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
The Pile was manually vetted by our editorial team and was first featured on 2023-03-07.
Related Searches
The Pile Alternatives
Plus Alternatives-
GPT-NeoX-20B est un modèle de langage autorégressif à 20 milliards de paramètres entraîné sur Pile à l'aide de la bibliothèque GPT-NeoX.
-

Libérez votre potentiel de codage avec Replit Code V-1.5 3B. Ce puissant modèle de langage causal génère des suggestions de code précises dans de nombreux langages de programmation.
-

Easy Dataset : Créez sans effort des données d'entraînement pour l'IA à partir de vos documents. Affinez les LLM avec des ensembles de données de questions-réponses personnalisés. Convivial et compatible avec le format OpenAI.
-

Découvrez StableLM, un modèle linguistique open-source de Stability AI. Générez du texte et du code performants sur vos appareils personnels grâce à des modèles petits et efficaces. Une technologie IA transparente, accessible et offrant un soutien actif aux développeurs et chercheurs.
-