What is The Pile?
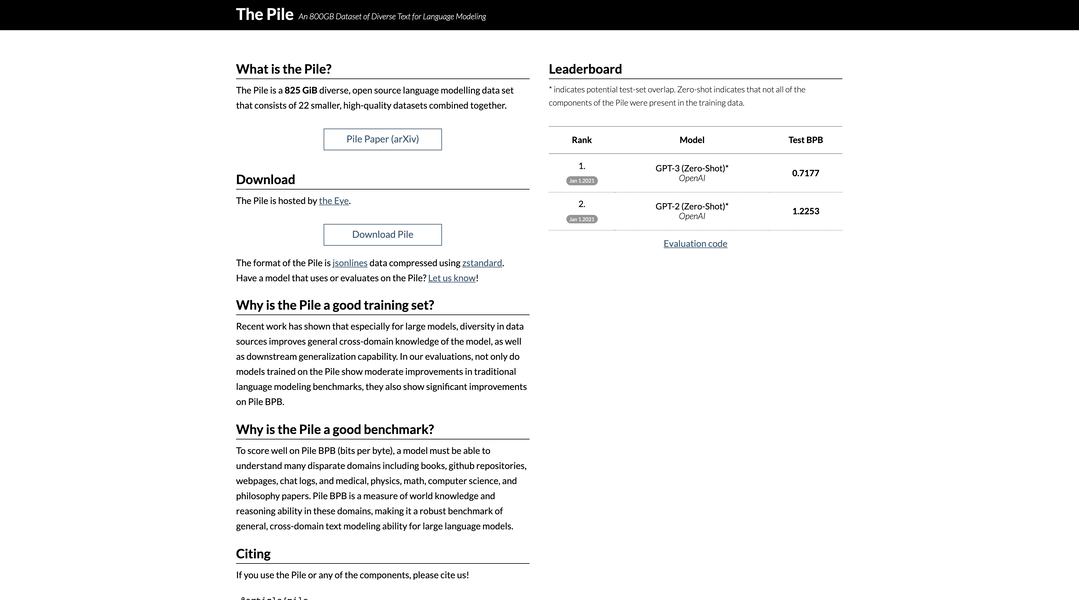
The Pile 是一个 825 GiB 的开源语言建模数据集,由 Eye 精心策划,从 22 个多样化的高质量数据集收集而来。它是一个全面的训练模型资源,提供改进的跨领域知识并增强泛化能力。
主要特点:
? 多样化的数据汇编:The Pile 汇集了 22 个较小的数据集,涵盖广泛的来源,如书籍、GitHub 存储库、网页、聊天记录和来自各个领域的学术论文,促进了全面的语言模型训练。
? 增强的模型性能:在 The Pile 上训练的模型在传统语言建模基准测试方面表现出显着的改进,并且在 Pile BPB(每字节比特)方面也有显著进步,这表明增强了跨领域文本建模能力。
? 稳健的基准测试:Pile BPB 作为一项严格的基准,评估了模型在不同领域(包括文学、科学、技术和哲学)的理解和推理能力,提供了对模型的跨领域文本建模能力的见解。
用例:
学术研究:研究人员可以利用 The Pile 为各种语言任务训练模型,增强他们对语言动态的理解并促进自然语言处理的突破。
人工智能模型开发:开发人员可以利用 The Pile 训练健壮的语言模型,能够理解和生成跨越不同领域的文本,从而在聊天机器人、内容生成和情感分析中实现应用程序。
教育计划:教育工作者可以将 The Pile 纳入课程开发,使学生能够探索语言建模技术并获得在不同语境中分析和生成文本的实践经验。
结论:
凭借其庞大而多样化的数据集,The Pile 为推进语言建模能力提供了一种变革性资源。无论是用于研究、开发还是教育,其全面的覆盖范围和稳健的基准测试都确保了更高的模型性能和跨领域适用性。立即深入了解 The Pile,释放语言建模的全部潜力。
常见问题解答:
与其他语言建模数据集相比,是什么让 The Pile 独一无二?
The Pile 因其广泛汇编的多样化数据集而脱颖而出,涵盖多个领域,包括文学、科学、技术等。这种多样性丰富了模型训练,并促进了改进的跨领域文本理解。
研究人员如何为 The Pile 做出贡献?
研究人员可以通过提供反馈、建议纳入其他数据集或分享对模型性能的见解为 The Pile 做出贡献。协作努力确保数据集的持续增强和完善。
The Pile 是否适用于训练各种规模的模型?
是的,The Pile 适用于各种规模的模型,从小型项目到大型部署。其可扩展性和多功能性使其成为多样化语言建模工作的一个宝贵资源。
More information on The Pile
Launched
2020-07
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Fastly,GitHub Pages,Varnish
Top 5 Countries
16.11%
15.16%
12.4%
11.04%
8.58%
India
Germany
France
United States
Turkey
Traffic Sources
3.65%
0.95%
0.15%
20.46%
38.66%
35.68%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
The Pile was manually vetted by our editorial team and was first featured on 2023-03-07.
Related Searches