
Click outside to close
What is The Pile?
The Pile is an 825 GiB open-source language modeling dataset, meticulously curated from 22 diverse, high-quality datasets, hosted by Eye. It serves as a comprehensive resource for training models, offering improved cross-domain knowledge and enhancing generalization capabilities.
Key Features:
📚 Diverse Data Compilation:The Pile amalgamates 22 smaller datasets, encompassing a wide range of sources such as books, GitHub repositories, webpages, chat logs, and academic papers from various fields, fostering comprehensive language model training.
🚀 Enhanced Model Performance:Models trained on The Pile exhibit notable improvements in traditional language modeling benchmarks, as well as significant advancements in Pile BPB (bits per byte), indicating enhanced cross-domain text modeling proficiency.
🎯 Robust Benchmarking:Pile BPB serves as a rigorous benchmark, evaluating a model's comprehension and reasoning abilities across disparate domains, including literature, science, technology, and philosophy, offering insights into its general cross-domain text modeling competence.
Use Cases:
Academic Research:Researchers can leverage The Pile to train models for diverse linguistic tasks, enhancing their understanding of language dynamics and facilitating breakthroughs in natural language processing.
AI Model Development:Developers can utilize The Pile to train robust language models capable of comprehending and generating text across various domains, empowering applications in chatbots, content generation, and sentiment analysis.
Educational Initiatives:Educators can incorporate The Pile into curriculum development, enabling students to explore language modeling techniques and gain hands-on experience in analyzing and generating text across diverse contexts.
Conclusion:
With its vast and diverse dataset, The Pile offers a transformative resource for advancing language modeling capabilities. Whether for research, development, or education, its comprehensive coverage and robust benchmarking ensure heightened model performance and cross-domain applicability. Dive into The Pile today to unlock the full potential of language modeling.
FAQs:
What makes The Pile unique compared to other language modeling datasets?
The Pile stands out for its extensive compilation of diverse datasets, spanning multiple domains, including literature, science, technology, and more. This diversity enriches model training and fosters improved cross-domain text comprehension.
How can researchers contribute to The Pile?
Researchers can contribute to The Pile by providing feedback, suggesting additional datasets for inclusion, or sharing insights on model performance. Collaborative efforts ensure continuous enhancement and refinement of the dataset.
Is The Pile suitable for training models of all sizes?
Yes, The Pile caters to models of various sizes, from small-scale projects to large-scale deployments. Its scalability and versatility make it a valuable resource for diverse language modeling endeavors.
More information on The Pile
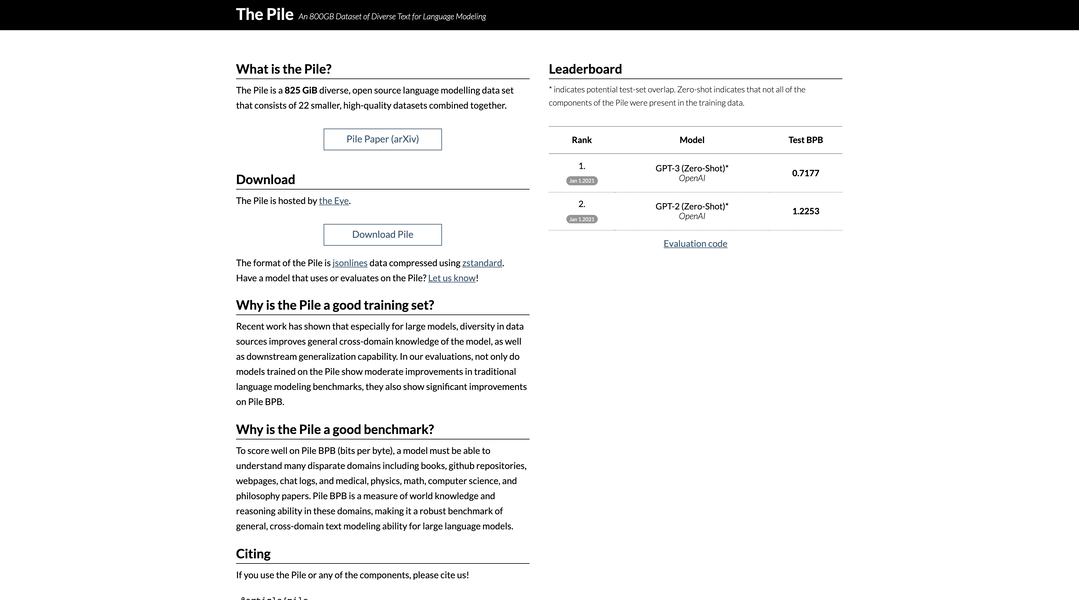
Top 5 Countries
29.5%
25.88%
14.98%
11.76%
9.47%
United States (29.5%)
India (25.88%)
France (14.98%)
Korea, Republic of (11.76%)
Canada (9.47%)
Traffic Sources
5.26%
20.92%
35.44%
37.03%
social (5.26%)
paidReferrals (1.05%)
mail (0.09%)
referrals (20.92%)
search (35.44%)
direct (37.03%)
Source: Similarweb (Jan 3, 2026)
The Pile was manually vetted by our editorial team and was first featured on 2023-03-07.
The Pile Alternatives
The Pile Alternatives-
GPT-NeoX-20B is a 20 billion parameter autoregressive language model trained on the Pile using the GPT-NeoX library.
-

Unlock your coding potential with Replit Code V-1.5 3B. This powerful Causal Language Model offers accurate code suggestions across programming languages.
-

Easy Dataset: Effortlessly create AI training data from your documents. Fine-tune LLMs with custom Q&A datasets. User-friendly & supports OpenAI format.
-

Discover StableLM, an open-source language model by Stability AI. Generate high-performing text and code on personal devices with small and efficient models. Transparent, accessible, and supportive AI technology for developers and researchers.
-
A Trailblazing Language Model Family for Advanced AI Applications. Explore efficient, open-source models with layer-wise scaling for enhanced accuracy.