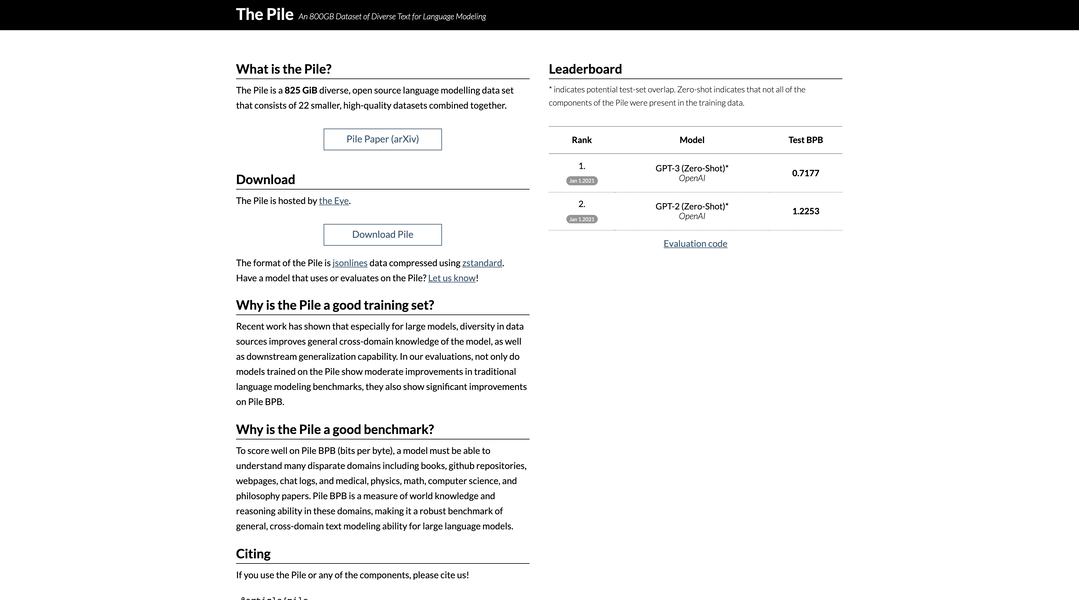
What is The Pile?
The Pileは、Eyeがホストする22の多様な高品質のデータセットから丹念にキュレーションされ、825 GiBのオープンソース言語モデリングデータセットです。モデルのトレーニングに包括的なリソースとして役立ち、クロスドメイン知識を向上させ、一般化能力を高めます。
主な機能:
? 多様なデータのコンパイル:The Pileは、書籍、GitHubリポジトリ、Webページ、チャットログ、さまざまな分野の学術論文など、さまざまなソースからなる22の小さなデータセットを統合し、包括的な言語モデルトレーニングを促進します。
? 強化されたモデルパフォーマンス:The Pileでトレーニングされたモデルは、従来の言語モデリングベンチマークで著しい改善を示すだけでなく、Pile BPB (1バイトあたりのビット数)で大幅な進歩を示し、クロスドメインテキストモデリングの熟達度の向上が示されます。
? 堅牢なベンチマーク:Pile BPBは厳格なベンチマークとして機能し、モデルの理解力と推論能力を文学、科学、技術、哲学などのさまざまなドメインで評価し、その一般的なクロスドメインテキストモデリング能力に関する洞察を提供します。
ユースケース:
学術研究:研究者たちは、言語動態の理解を深め、自然言語処理におけるブレークスルーを促進するために、さまざまな言語タスクのモデルをトレーニングするためにThe Pileを活用できます。
AIモデル開発:開発者は、チャットボット、コンテンツ生成、センチメント分析のアプリケーションを強化するために、さまざまなドメインにわたってテキストを理解して生成できる堅牢な言語モデルをトレーニングするためにThe Pileを活用できます。
教育イニシアチブ:教育者は、カリキュラム開発にThe Pileを組み込むことで、学生が言語モデリングの手法を探索し、さまざまなコンテキストでテキストの分析と生成に関する実践的な経験を積むことができます。
結論:
膨大で多様なデータセットを備えたThe Pileは、言語モデリング機能を向上させるための変革的なリソースを提供します。研究、開発、教育のいずれにおいても、その包括的なカバレッジと堅牢なベンチマークは、モデルのパフォーマンスとクロスドメイン適用性を向上させます。言語モデリングの真の可能性を解き放つために、今すぐThe Pileを活用してください。
FAQ:
The Pileは他の言語モデリングデータセットと比べて何がユニークですか?
The Pileは、文学、科学、技術など、複数のドメインにまたがる多様なデータセットを包括的にコンパイルしていることで際立っています。この多様性は、モデルのトレーニングを充実させ、クロスドメインテキスト理解の向上を促進します。
研究者はどのようにThe Pileに貢献できますか?
研究者は、フィードバックを提供したり、追加のデータセットを提案したり、モデルのパフォーマンスに関する洞察を共有したりすることで、The Pileに貢献できます。共同の取り組みは、データセットの継続的な強化と洗練を確保します。
The Pileはあらゆるサイズのモデルのトレーニングに適していますか?
はい、The Pileは小規模プロジェクトから大規模デプロイメントまで、さまざまなサイズのモデルに対応しています。そのスケーラビリティと汎用性は、多様な言語モデリングの取り組みにおいて貴重なリソースとなります。
More information on The Pile
Launched
2020-07
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Fastly,GitHub Pages,Varnish
Top 5 Countries
16.11%
15.16%
12.4%
11.04%
8.58%
India
Germany
France
United States
Turkey
Traffic Sources
3.65%
0.95%
0.15%
20.46%
38.66%
35.68%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
The Pile was manually vetted by our editorial team and was first featured on 2023-03-07.
Related Searches
The Pile 代替ソフト
もっと見る 代替ソフト-
-

Replit Code V-1.5 3Bでコーディングの可能性を開拓しましょう。この強力な因果言語モデルは、プログラミング言語全体で正確なコードの提案を提供します。
-

簡単なデータセット:ドキュメントからAIトレーニングデータを容易に作成できます。カスタムQ&AデータセットでLLMを微調整。ユーザーフレンドリーで、OpenAI形式をサポートします。
-

-