What is The Pile?
The Pile — это набор данных для языкового моделирования с открытым исходным кодом объемом 825 ГиБ, тщательно отобранный из 22 разнообразных высококачественных наборов данных, размещенных Eye. Он служит комплексным ресурсом для обучения моделей, предлагая улучшенные междоменные знания и расширяя возможности обобщения.
Ключевые особенности:
? Разнообразный набор данных: The Pile объединяет 22 небольших набора данных, охватывающих широкий спектр источников, таких как книги, репозитории GitHub, веб-страницы, журналы чатов и научные статьи из различных областей, что способствует всестороннему обучению языковых моделей.
? Улучшенная производительность модели: модели, обученные на The Pile, демонстрируют заметные улучшения в традиционных тестах языкового моделирования, а также значительные улучшения в Pile BPB (биты на байт), что указывает на повышение эффективности междоменного текстового моделирования.
? Надежный бенчмаркинг: Pile BPB служит строгим бенчмарком, оценивающим способности модели к пониманию и рассуждению в различных доменах, включая литературу, науку, технологии и философию, давая представление о ее общей компетентности в междоменном текстовом моделировании.
Варианты использования:
Академические исследования: исследователи могут использовать The Pile для обучения моделей для различных языковых задач, улучшая их понимание языковой динамики и содействуя прорывам в области обработки естественного языка.
Разработка моделей ИИ: разработчики могут использовать The Pile для обучения надежных языковых моделей, способных понимать и генерировать текст в различных доменах, расширяя возможности приложений в чат-ботах, генерации контента и анализе настроений.
Образовательные инициативы: преподаватели могут включить The Pile в разработку учебных программ, позволяя студентам изучать методы языкового моделирования и получать практический опыт в анализе и генерации текста в различных контекстах.
Заключение:
Благодаря своему обширному и разнообразному набору данных The Pile предлагает революционный ресурс для развития возможностей языкового моделирования. Независимо от того, предназначен он для исследований, разработки или образования, его всестороннее покрытие и надежный бенчмаркинг обеспечивают высокую производительность модели и междоменную применимость. Погрузитесь в The Pile уже сегодня, чтобы раскрыть весь потенциал языкового моделирования.
Часто задаваемые вопросы:
Что отличает The Pile от других наборов данных для языкового моделирования?
The Pile выделяется своей обширной компиляцией разнообразных наборов данных, охватывающих несколько доменов, включая литературу, науку, технологии и многое другое. Это разнообразие обогащает обучение моделей и способствует улучшенному междоменному пониманию текста.
Как исследователи могут внести свой вклад в The Pile?
Исследователи могут внести свой вклад в The Pile, предоставляя обратную связь, предлагая дополнительные наборы данных для включения или делясь сведениями о производительности модели. Совместные усилия обеспечивают постоянное улучшение и совершенствование набора данных.
Подходит ли The Pile для обучения моделей всех размеров?
Да, The Pile подходит для моделей различных размеров: от небольших проектов до крупномасштабных развертываний. Его масштабируемость и универсальность делают его ценным ресурсом для различных проектов языкового моделирования.
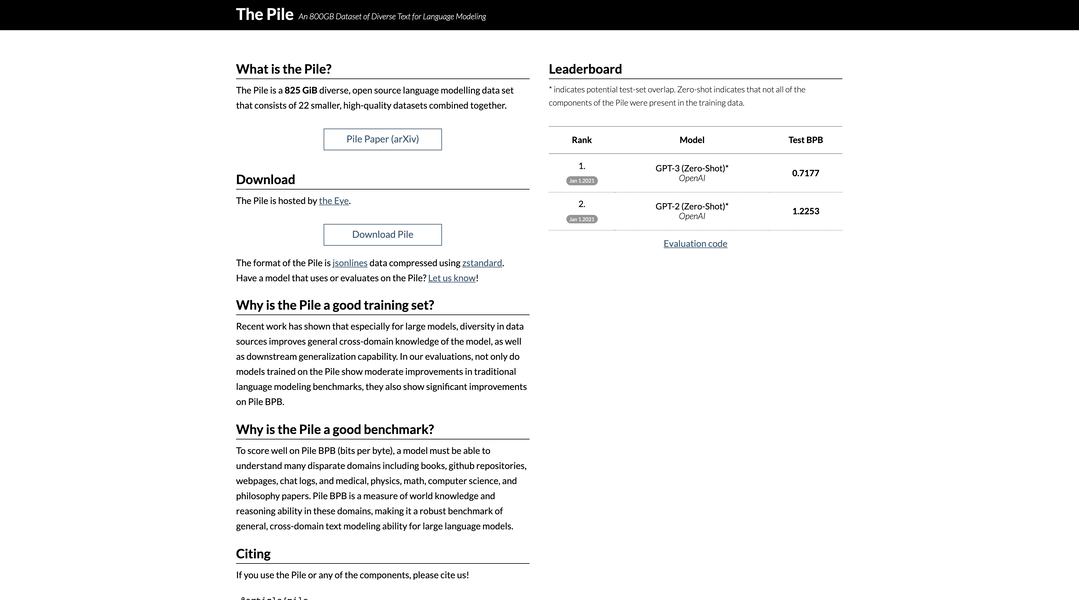
More information on The Pile
Launched
2020-07
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Fastly,GitHub Pages,Varnish
Top 5 Countries
16.11%
15.16%
12.4%
11.04%
8.58%
India
Germany
France
United States
Turkey
Traffic Sources
3.65%
0.95%
0.15%
20.46%
38.66%
35.68%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
The Pile was manually vetted by our editorial team and was first featured on 2023-03-07.
Related Searches
The Pile Альтернативи
Больше Альтернативи-
GPT-NeoX-20B — это крупная авторегрессивная языковая модель с 20 миллиардами параметров, обученная на Pile с использованием библиотеки GPT-NeoX.
-

Раскройте свой потенциал программирования с Replit Code V-1.5 3B. Эта мощная каузальная языковая модель предлагает точные предложения кода на различных языках программирования.
-

Простой Dataset: С легкостью создавайте данные для обучения ИИ на основе ваших документов. Точно настраивайте LLM с помощью пользовательских наборов данных вопросов и ответов. Удобный интерфейс и поддержка формата OpenAI.
-

Откройте для себя StableLM — открытую языковую модель от Stability AI. Генерируйте высокопроизводительный текст и код на персональных устройствах с помощью небольших и эффективных моделей. Прозрачная, доступная и поддерживаемая технология ИИ для разработчиков и исследователей.
-