What is HyperCrawl?
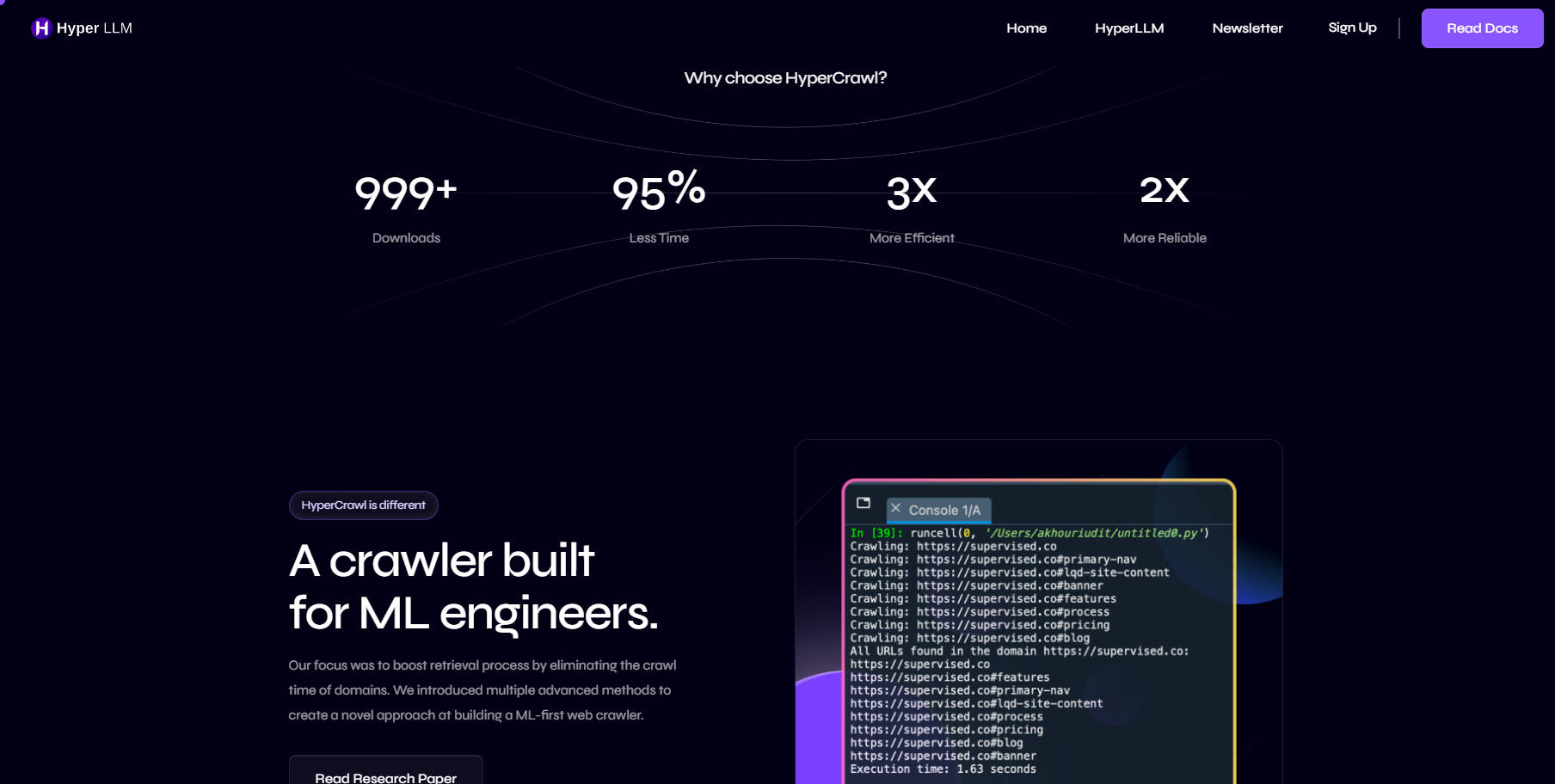
HyperCrawlは、大規模言語モデル(LLM)およびリトリーバージェネレーター(RAG)アプリケーション向けに特別に設計された画期的なウェブクローラーです。従来のリトリーバルエンジンの構築方法とは異なるアプローチを採用することで、リトリーバル時間を最大95%削減します。機械学習(ML)エンジニアリングに焦点を当てることで、HyperCrawlはウェブクロールプロセスの効率性と信頼性を向上させることを目指しています。
主な機能
非同期I/O:HyperCrawlは非同期I/Oを採用しており、複数のウェブページを同時にリクエストできます。これは、複数のオンライン注文を一度に置くようなものです。このアプローチにより、各ウェブページが個別にロードされるのを待つ無駄な時間を削減できます。
並行処理管理:高い並行処理レベルを設定することで、クローラーは多数のタスクを同時に処理できます。これは、タスクを順番に処理する場合よりもプロセスを高速化します。
効率的なリソース処理:HyperCrawlは、既存の接続を再利用することでリソースの使用を最適化します。これは、すべてのタスクのために新しいショッピングバッグを取得するのではなく、既存のショッピングバッグを再利用するようなものです。
訪問済みURL追跡:クローラーは訪問済みURLを記憶し、以前に訪問したページの再処理を回避することで、冗長な作業を防ぎます。
ネストされたイベントループのサポート:HyperCrawlは汎用性があり、Google ColabやJupyterノートブックなどのさまざまな環境で動作できます。イベントループの問題は発生しません。
ユースケース
LLMトレーニングの強化:HyperCrawlは大量のデータを効率的に取得できるため、LLMトレーニングのための豊富なデータセットを提供し、より正確で堅牢なモデルにつながります。
RAGアプリケーションの最適化:リトリーバージェネレーターフレームワークを使用するアプリケーションの場合、HyperCrawlの速度と効率により、より迅速で関連性の高いデータ取得が可能になり、RAGシステム全体の性能が向上します。
ウェブベースおよびJSプロジェクト:HyperCrawlはHyperAPIを介して利用できるため、ウェブベースのプロジェクトやJavaScriptプロジェクトにシームレスに統合できます。これは、さまざまなドメインでのユーティリティを拡大します。
結論
HyperCrawlは、MLエンジニアを念頭に置いて設計された先駆的なウェブクローラーです。革新的な機能と効率性への焦点は、LLMおよびRAGアプリケーションにとって貴重なツールとなっています。HyperCrawlは、リトリーバル時間を短縮し、リソースの使用を最適化することで、より高速で効率的、信頼性の高いウェブクロールプロセスへの道を切り開きます。HyperCrawlで今すぐ始めましょう。高速LLMの未来への動きに参加しましょう。
More information on HyperCrawl
Launched
2023-07
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Top 5 Countries
71.73%
28.27%
Singapore
Hong Kong
Traffic Sources
72.86%
27.14%
0%
Referrals
Direct
Search
Source: Similarweb (Jul 23, 2024)
HyperCrawl was manually vetted by our editorial team and was first featured on 2024-05-26.
Related Searches
HyperCrawl 代替ソフト
もっと見る 代替ソフト-

-

-

-

-

Webcrawlerapiを使えば、ウェブデータ抽出が簡単になります! JavaScriptの処理、プロキシ、スケーリングに対応。AIや分析などに必要な構造化データを取得できます。