
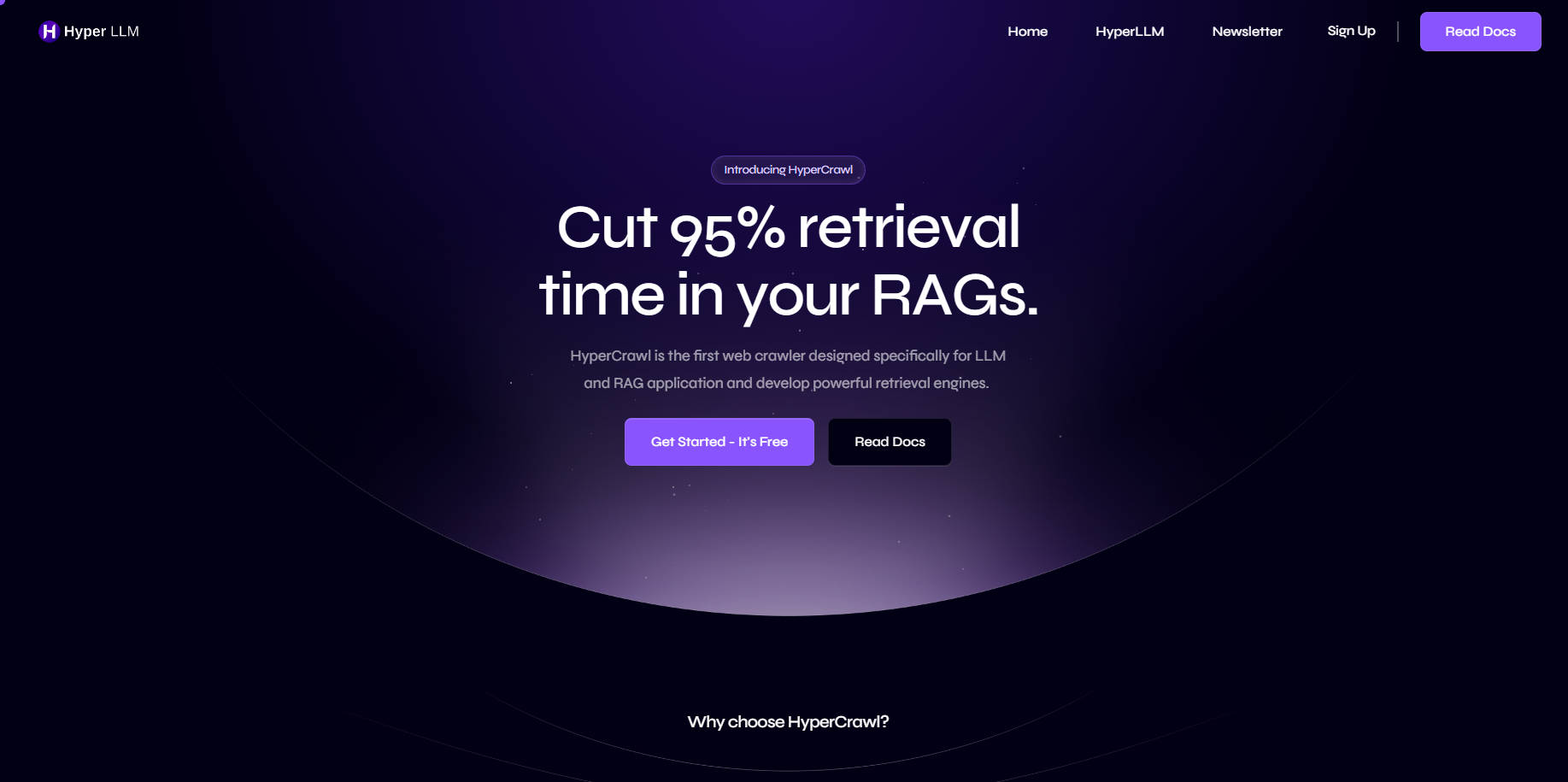
What is HyperCrawl?
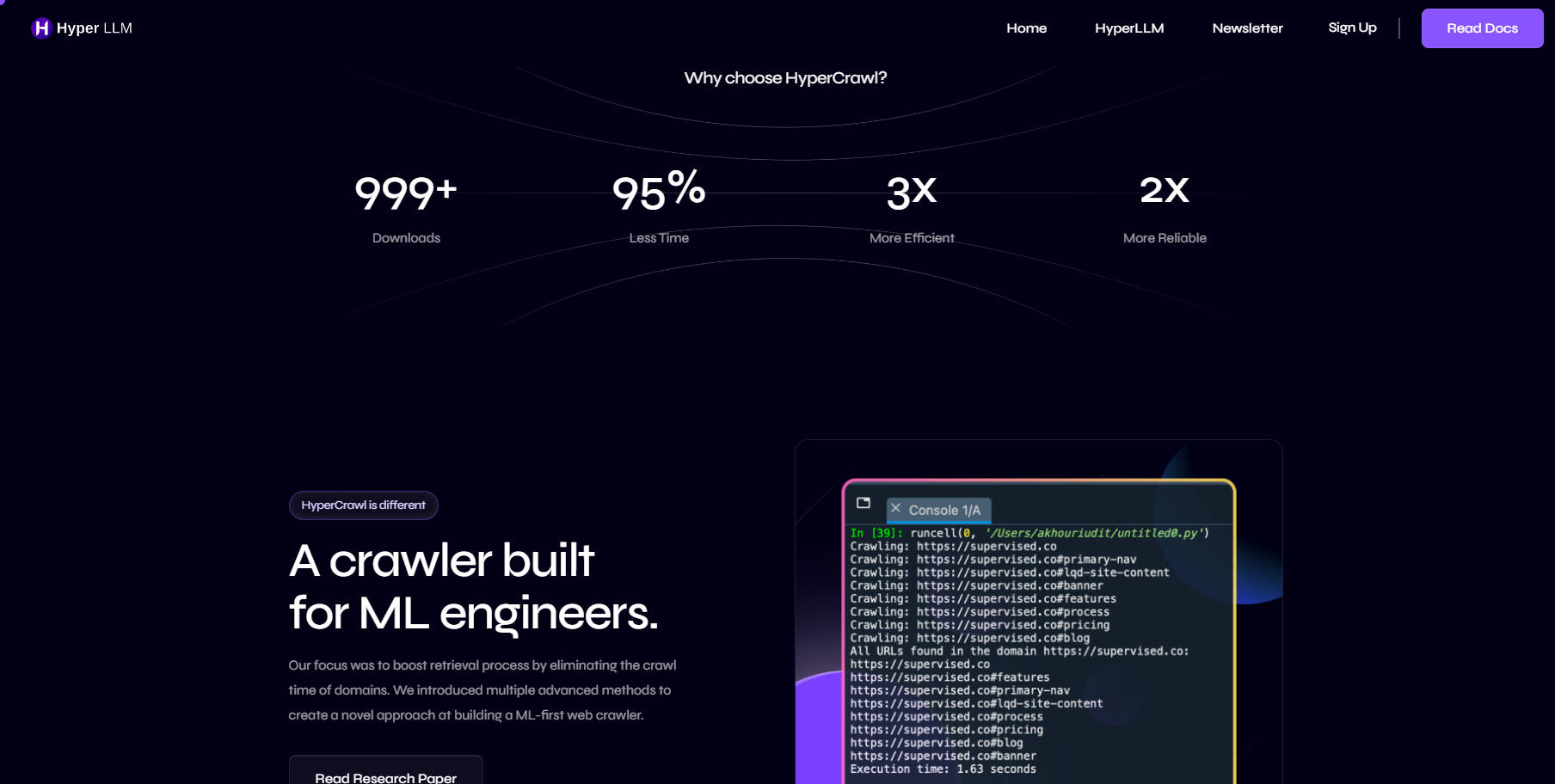
HyperCrawl 是一款為大型語言模型 (LLM) 和 Retrieval-Generator (RAG) 應用程式量身打造的突破性網路爬蟲。它提供了一種創新的建立擷取引擎的方法,將擷取時間大幅縮短高達 95%。HyperCrawl 專注於機器學習 (ML) 工程,旨在提升網路爬蟲流程的效率和可靠性。
主要功能
非同步 I/O:HyperCrawl 採用非同步 I/O,允許它同時請求多個網頁,就像同時下多個線上訂單一樣。這種方式消除了等待每個網頁單獨載入所浪費的時間。
併發管理:透過設定高併發層級,爬蟲可以同時處理多個任務,與依序處理任務相比,速度更快。
高效資源處理:HyperCrawl 透過重複使用現有連線來優化資源使用,就像重複使用購物袋而不是每次任務都取得新的購物袋。
已訪問 URL 追蹤:爬蟲會記住已訪問的 URL,避免重新處理之前訪問過的頁面,防止重複工作。
嵌套事件迴路支援:HyperCrawl 多功能,可以在各種環境中運作,例如 Google Colab 或 Jupyter 筆記本,而不會遇到事件迴路的任何問題。
使用案例
增強 LLM 訓練:HyperCrawl 可以有效地擷取大量資料,為訓練 LLM 提供豐富的資料集,從而產生更準確和更健壯的模型。
RAG 應用程式最佳化:對於使用 Retrieval-Generator 架構的應用程式,HyperCrawl 的速度和效率可確保更快、更相關的資料擷取,提升 RAG 系統的整體效能。
基於網路的 & JS 項目:HyperCrawl 透過 HyperAPI 提供,可以無縫整合到基於網路的和 JavaScript 項目中,擴展其在各個領域的效用。
結論
HyperCrawl 是一款專為 ML 工程師設計的開創性網路爬蟲。其創新功能和對效率的重視使其成為 LLM 和 RAG 應用的寶貴工具。透過縮短擷取時間和優化資源使用,HyperCrawl 為更快、更高效、更可靠的網路爬蟲流程鋪平了道路。加入快速 LLM 未來的浪潮,立即開始使用 HyperCrawl。
More information on HyperCrawl
Launched
2025-04
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Top 5 Countries
71.73%
28.27%
Singapore
Hong Kong
Traffic Sources
72.86%
27.14%
0%
Referrals
Direct
Search
Source: Similarweb (Jan 3, 2026)
HyperCrawl was manually vetted by our editorial team and was first featured on 2024-05-26.
Related Searches
HyperCrawl 替代方案
更多 替代方案-

-

-

-

-

輕鬆擷取網路資料!Webcrawlerapi 處理 JavaScript、代理伺服器與擴展性。取得結構化資料,用於 AI、分析及其他用途。