What is HyperCrawl?
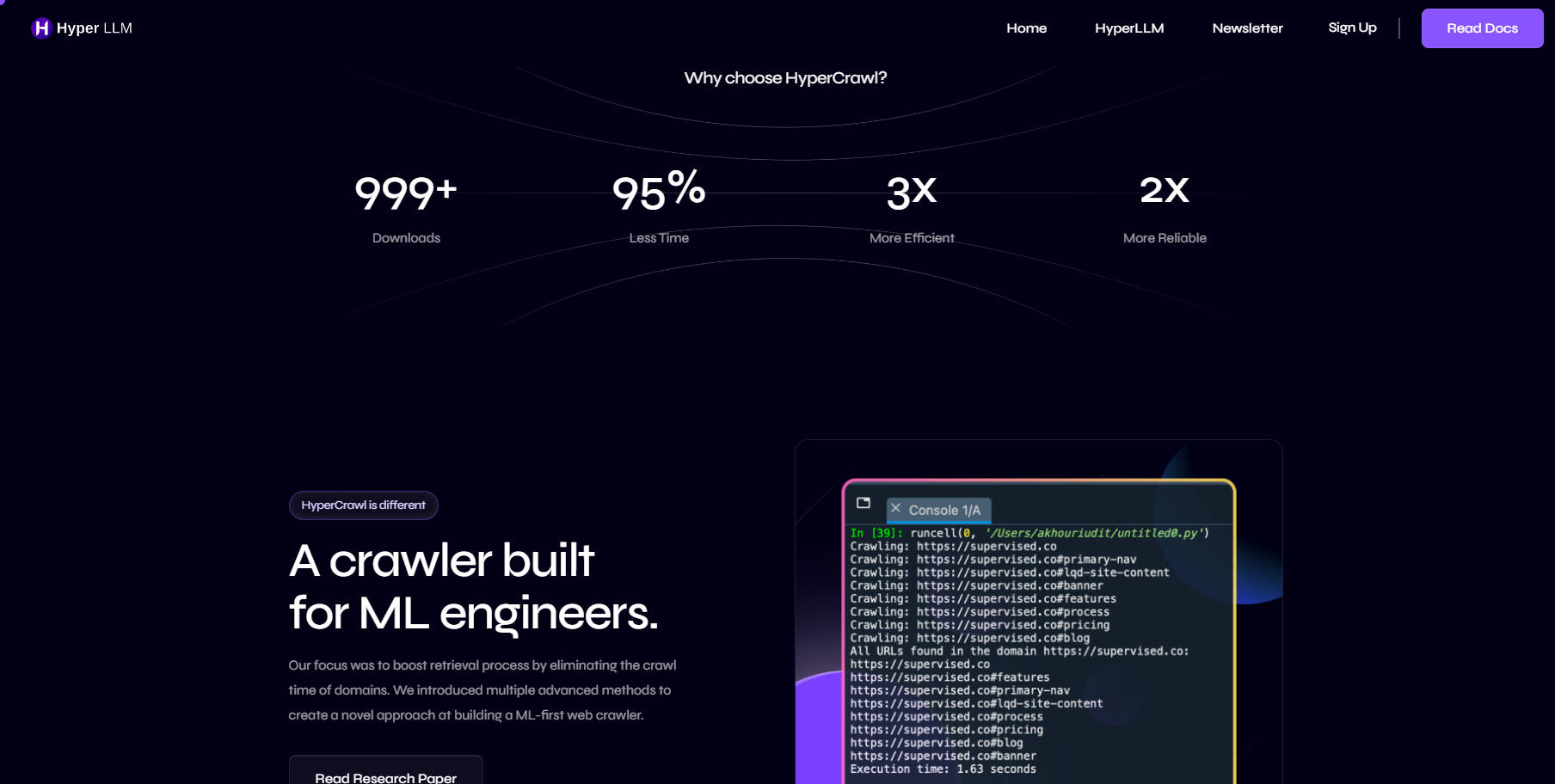
HyperCrawl 是一款为大型语言模型 (LLM) 和检索器-生成器 (RAG) 应用程序专门设计的突破性网络爬虫。它提供了一种构建检索引擎的新方法,将检索时间显著减少高达 95%。凭借其对机器学习 (ML) 工程的关注,HyperCrawl 旨在提高网络爬取过程的效率和可靠性。
主要特点
异步 I/O:HyperCrawl 采用异步 I/O,允许它同时请求多个网页,类似于同时下多个网购订单。这种方法消除了等待每个网页单独加载所浪费的时间。
并发管理:通过设置高并发级别,爬虫可以同时处理大量任务,与顺序处理任务相比,可以加快处理速度。
高效的资源处理:HyperCrawl 通过重用现有连接来优化资源使用,类似于重复使用购物袋而不是为每个任务都购买一个新的购物袋。
已访问 URL 跟踪:爬虫会记住已访问的 URL,避免重新处理之前访问的页面,防止重复工作。
嵌套事件循环支持:HyperCrawl 非常灵活,可以在各种环境中运行,例如 Google Colab 或 Jupyter 笔记本,而不会遇到事件循环问题。
用例
增强 LLM 训练:HyperCrawl 可以高效地检索大量数据,为训练 LLM 提供丰富的训练集,从而生成更准确、更强大的模型。
RAG 应用程序优化:对于使用检索器-生成器框架的应用程序,HyperCrawl 的速度和效率确保更快速、更相关的数据检索,从而提高 RAG 系统的整体性能。
基于 Web 的和 JS 项目:HyperCrawl 通过 HyperAPI 的可用性,可以无缝集成到基于 Web 的和 JavaScript 项目中,扩展其在各个领域的实用性。
结论
HyperCrawl 是一款面向 ML 工程师设计的开创性网络爬虫。其创新功能和对效率的关注使其成为 LLM 和 RAG 应用程序的宝贵工具。通过减少检索时间和优化资源使用,HyperCrawl 为更快、更高效、更可靠的网络爬取流程铺平了道路。立即开始使用 HyperCrawl,加入快速 LLM 未来发展的浪潮。
More information on HyperCrawl
Launched
2023-07
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Top 5 Countries
71.73%
28.27%
Singapore
Hong Kong
Traffic Sources
72.86%
27.14%
0%
Referrals
Direct
Search
Source: Similarweb (Jul 23, 2024)
HyperCrawl was manually vetted by our editorial team and was first featured on 2024-05-26.
Related Searches
HyperCrawl 替代方案
更多 替代方案-

-

-

-

-

轻松提取网络数据!Webcrawlerapi 可处理 JavaScript、代理和扩展等问题。获取结构化数据,用于 AI、分析及其他用途。