
What is Unstract?
Unstractは、大規模言語モデル(LLM)を活用し、複雑な非構造化文書から高精度なデータ抽出を行うために特別に開発されたオープンソースのノーコードプラットフォームです。これは、多種多様な文書の準備や処理にともなう手作業の複雑さを効果的に解消し、精度と拡張性を追求する先進的なエンジニアや組織が、重要な非構造化データ資産のために信頼性が高く、監査可能なAPIおよびETLパイプラインを導入できるように支援します。
主要機能
Unstractは、あらゆる形式の文書入力を、クリーンで信頼性の高い、システムですぐに利用可能なJSONまたはCSVデータへと変換するために必要なアーキテクチャコンポーネントを提供します。
🧠 LLMChallenge:デュアルLLMコンセンサスエンジン
この独自のメカニズムは、抽出器と検証器という2つの独立したLLMを用いることで結果を検証し、データの信頼性を向上させます。システムは「 誤りよりもNULL(無効)が良い 」という原則に基づき機能し、プロセスの初期段階でハルシネーションを検知し、排除します。これにより、正確で検証済みの値のみが返されることを保証し、自動化されたワークフローの整合性を大幅に強化します。
🛠️ Prompt Studio:専用エンジニアリング環境
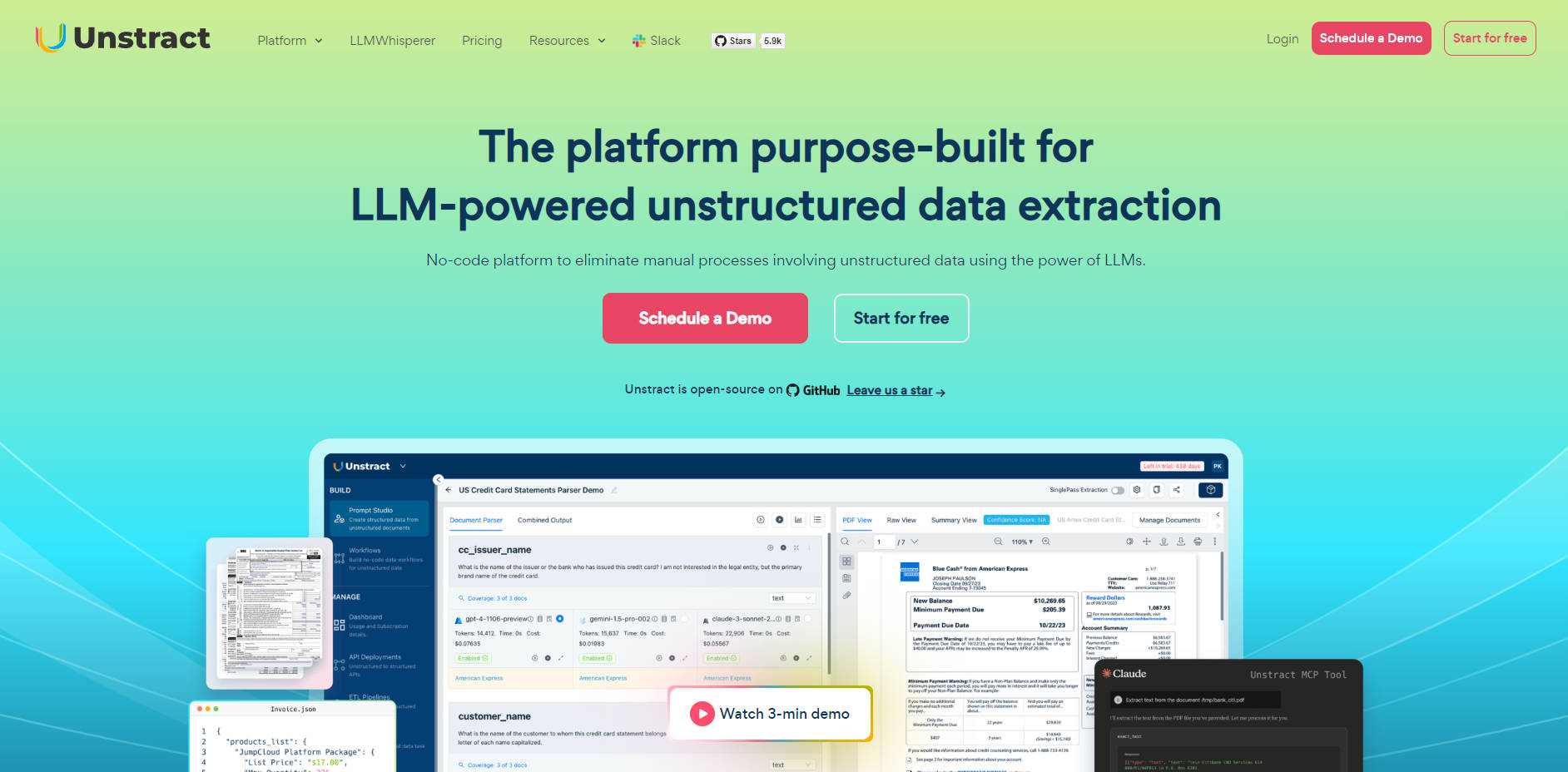
Prompt Studioは、プロンプトエンジニアが抽出ロジックを迅速に構築、テスト、洗練できるようにする専用の作業環境を提供します。代表的な少数の文書サンプルから汎用プロンプトを素早く構築でき、シンプルなテキストからネストされたJSONまで、 一貫したスキーマを適用 し、容易なテストとロールバックのための組み込み バージョン管理 を活用できます。この機能は、複雑で高精度なデプロイに必要な制御を提供します。
🖼️ LLMWhisperer:レイアウトを維持する文書準備
スキャンされたPDF、複数列のフォーム、スマートフォンで撮影された画像など、実際の文書を扱う場合には、知的な前処理が必要です。LLMWhispererはコンパニオンサービスとして機能し、LLMが最も理解しやすい形式で、高度に最適化された出力を生成します。その 独自のレイアウト維持モード により、LLMは複数列のレイアウト、フォーム、テーブルを正確に解釈し、手書き文字、チェックボックス、ラジオボタンさえも確実に検出することを可能にします。
⚡ SinglePass&Summarized Extraction:コスト効率のための最適化
トークン使用量を最適化することで、大幅なコスト削減と速度向上を実現します。 SinglePass Extraction は、すべてのフィールド抽出プロンプトを統合し、文書全体に対して1回の大規模な実行を行います。あるいは、 Summarized Extraction は、入力文書の非常にコンパクトなバージョンを自動的に構築し、この最適化されたバージョンに対してプロンプトを実行することで、処理するテキスト量を削減します。これらの戦略により、トークン使用量を最大 7倍 削減でき、最小限のコストで最大限の抽出を提供します。
🧑💻 Human-in-the-Loop (HITL) 検証
絶対的な確実性が求められる本番環境レベルのデータに対しては、HITL機能が、自動抽出と完璧なデータとの間のギャップを埋めます。確信度スコアやフィールド値に基づいて スマートなルーティングルールを設定 でき、チームがエッジケースのみを確認するようにします。ユーザーは抽出されたデータをソース文書と並べて表示し、 ソース文書ハイライト を活用して、即座の検証、誤りの編集、そして完全な監査証跡の維持を可能にします。
ユースケース
Unstractは、従来のインテリジェント文書処理(IDP)やロボティック・プロセス・オートメーション(RPA)システムが対応に苦慮する複雑さと規模を処理するために構築されています。
多様な文書の処理: 多種多様な文書を含むタスクを容易に自動化できます。例えば、 200の異なる銀行の預金明細書 の処理や、50の異なる州で異なる形式の同じフォームの処理などです。Unstractは、文書のバリエーションにかかわらず、一貫した構造化されたJSON出力を保証します。
複雑な契約分析の自動化: エンジニアは、LLMWhispererとSinglePass抽出を活用して、請求書から特定の詳細な明細項目を効率的に抽出したり、長い法的契約書から重要な条項を特定したりできます。これにより、これまで人間のみが行っていたレビュー作業を、信頼性の高い自動ワークフローへと変革します。
データエコシステムとの連携: クラウドファイルストレージに保存された非構造化文書を構造化し、事前に構築されたETLパイプラインを使用して、データウェアハウスやデータベースに自動的にプッシュします。あるいは、Unstract APIを呼び出すことで、抽出機能を既存のアプリケーションに直接組み込み、取り込み時点でシームレスな文書構造化を可能にします。
ユニークな利点
Unstractは、従来の文書処理ソリューションの限界を超越するよう設計されており、速度、精度、エンジニアリングの柔軟性に焦点を当てています。
コンセンサスによる信頼性: LLMChallenge (デュアルLLMコンセンサスエンジン)は、中核となる差別化要因です。従来のシステムが確信度スコアや単一モデルの出力のみに依存しているのに対し、ハルシネーションを検知し、排除します。これにより、本番環境レベルのデータ整合性を保証します。
最大限の効率性、最小限のコスト: SinglePassやSummarized Extractionといった特殊な最適化技術により、トークン使用量を最大 7倍 削減できます。これにより、処理速度を向上させつつ、運用コストを劇的に削減します。
オープンソースの柔軟性: オープンソースのノーコードプラットフォームとして、Unstractは組織に完全な透明性と制御を提供します。マルチLLM環境(OpenAI、Claude、Azure GPT、Vertex)をサポートし、特定のコンプライアンスおよびパフォーマンス要件に合わせて、最適なVector DB、埋め込みモデル、およびテキスト抽出サービスを選択できます。
IDPとRPAを超えて: 最先端のLLM機能を活用することで、Unstractは非構造化データの核となる課題(特に高い変動性と一貫性のない形式)に対処します。従来のIDPやRPAのルールベースまたはテンプレート依存の限界を超えます。
まとめ
Unstractは、複雑で変動の多い文書を、デプロイ可能な構造化された信頼性の高いデータへと変換するために必要なツールと本番環境レベルのアーキテクチャを提供します。精度と拡張性のために構築されており、エンジニアが自動化のスケールを向上させ、手作業による監視を大幅に削減できるよう支援します。
Unstractがどのように最大限の抽出効率を達成し、次世代のデータパイプラインをデプロイするのに役立つかをご覧ください。 今すぐ14日間の無料トライアルを開始しましょう。
More information on Unstract
Launched
2023-08
Pricing Model
Freemium
Starting Price
Global Rank
451302
Follow
Month Visit
74.5K
Tech used
WordPress,Elementor,Bootstrap,animate.css,Clipboard.js,Font Awesome,Google Analytics,Google Font API,Google Tag Manager,HubSpot Analytics,Linkedin Insight Tag,Prism,Slick,Swiper Slider,jQuery,jQuery Migrate
Top 5 Countries
14.99%
8.71%
8.58%
7.61%
6.02%
United States
Nigeria
India
Brazil
Germany
Traffic Sources
15.81%
0.86%
0.11%
9.05%
40.45%
33.65%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Unstract was manually vetted by our editorial team and was first featured on 2024-06-19.
Related Searches
Unstract 代替ソフト
もっと見る 代替ソフト-

-

Unsiloed AI は、高度なAIエージェントを駆使して、非構造化文書を構造化された活用可能なデータへと変換する最先端プラットフォームです。
-

DocStrange: オープンソースのPythonライブラリ。あらゆるドキュメントをAIが活用しやすい構造化データに変換し、LLMやRAGの利用においてプライバシーと正確性を両立させます。
-

Parse Extract: LLMパイプライン向けの高度なデータ抽出とOCR。 複雑なドキュメントやウェブデータを、クリーンでLLMに最適なテキストへと変換します。 費用対効果に優れ、高いセキュリティを実現します。
-

DeepTagger: ノーコードAIが、インテリジェントな文書データ抽出を自動化します。複雑な文書を構造化された実用的なデータへと変換し、新たな知見を解き放ちます。